Prompt, Adaptor, ...
预训练模型没有那么完美,其中两个问题:一,面对数据稀缺的情况,微调效果很可能一般;二,模型参数量大,存储空间占用较大,计算量大。目前相应的对策,效果较好的有:Prompt取代fine-tuning,设计Apdater减少模型训练参数。
Prompt
设计fine-tuning输入模板,让模型根据上下文填充MASK。
Input: [CLS] The spring break is coming soon. [MASK]. the spring break was over? | Label: no
Input: [CLS] I am going to have dinner. [MASK]. I am going to eat something? | Label: yes
MASK 部分可以是多个词,长度可调。
如何加入任务label信息?通过 verbalizer,将 MASK 部分预测的词与label的单词形成一个map。预测的时候,根据预测的词和map,找到对应的label。
通过预训练model,自己学习处任务相关的 prompt。充分利用预训练信息,这种方式看起来是不错的。
问题来了,怎么确定一个好的 verbalizer mapping ?
PET(Pattern-Exploiting Training)
PET 方案(少量样本半监督情景):
- 在监督数据上,进行多个Prompt范式tuning,得到多组 prompt 单词,分别对应到相应的label。
- 在无监督数据上,多个模型进行预测,每个模型分别在各自的 prompt 单词候选集中,进行输出的softmax。多个模型结果取平均,得到soft label。(蒸馏也用这招,一些半监督或者模型精调都有用到这种方法)。
- 联合监督数据和无监督数据,进行训练得到最终的模型。
iPET (Iterative PET)
PET 作者对 PET 的改进版。只是将 PET的三步,进行多轮,同时增大label mapping的范围。实验效果,在小样本场景下是超过 fine-tuning 的。但是,这对比实验,有点不公平。因为是在 fine-tuning 并没精心设计过的条件下的比较。
另外,PET多个模型训练的时间成本和资源消耗明显更高。那么,这些成本转换成对 fine-tuning 方式下,构建人工标注数据的成本呢?又该怎么说?是不是还简单直接一些?
LM-BFF(better few-shot fine-tuning of language models)
LM-BFF 则是另一种思路,增加更多的提示信息,输入到model。
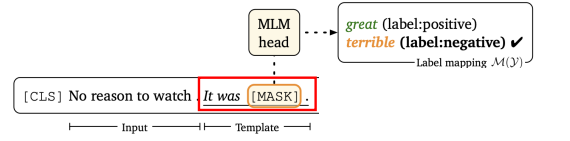
将上图改为:

后面加上了一组示例输入,作为一种显示提示。和GPT3的方式有点像。但是LM-BFF对模型进行训练的数据,有梯度更新。GPT3没有梯度更新,只是生成模型的inference提示。
这里的 mapping 设计方式,论文使用了人工设计和模型自己学习推断两种方法。效果这能说相差无几。
Multitask Prompt
Multitask Prompt 使用多任务的方式,每个任务设计一个 prompt template,进行学习。然后在模型没有见过的任务上,再进行prompt inference,期望模型实现 zero-shot inference。论文实验结果显示,使用T5或者T0模型进行多任务Prompt,更少的参数量就可以达到甚至超过GPT3的效果。
Other multitask based:
参数化 Prompt
设计 verbalizer 显然不够 AI。有研究者就直接时用可训练的 token 来替代 prompt,直接训练 token 对应的特殊的 embedding。
对于 GPT 这种自回归模型,设计 prefix token,加在输入 sentence 之前;对于 T5、BART 这类Encoder-Decoder 模型,在Encoder和Decoder两边加上 prefix-E 和 prefix-D。训练时将原预训练模型参数freeze。
还有像 P-tuning 这样的方法,使用 LSTM 对 Prompt 输入进行额外编码。同时开放 原预训练模型参数进行训练。效果不错,超越了 fine-tuning 效果。但是这个方法训练起来的成本显然比较高。
Tricks
prompt 单词使用 label 单词初始化,效果相比随机初始化要好。
Adaptor
Parameter-Efficient Fine-tuning,不训练原预训练模型的参数,只训练设计的 Adaptor 结构的参数。
fine-tuning 的想法是训练原模型参数,产生相应任务的有效 hidden representation。但是 Adaptor 是固定原模型参数,设计结构在原 hidden representation 基础上得到任务相关的 hidden representation。
Adaptor
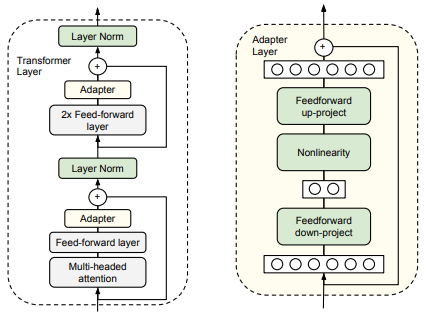
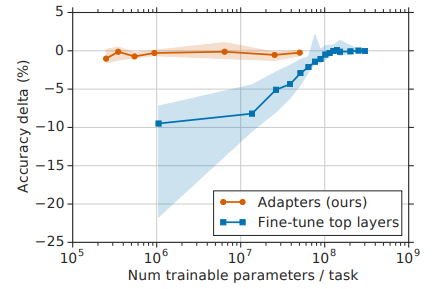
只训练 Adapter 层参数。更少的训练参数,更好的训练效果。
LoRA(Low-Rank Adaptation)
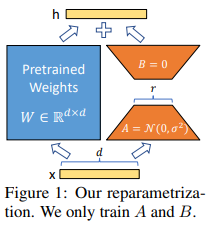
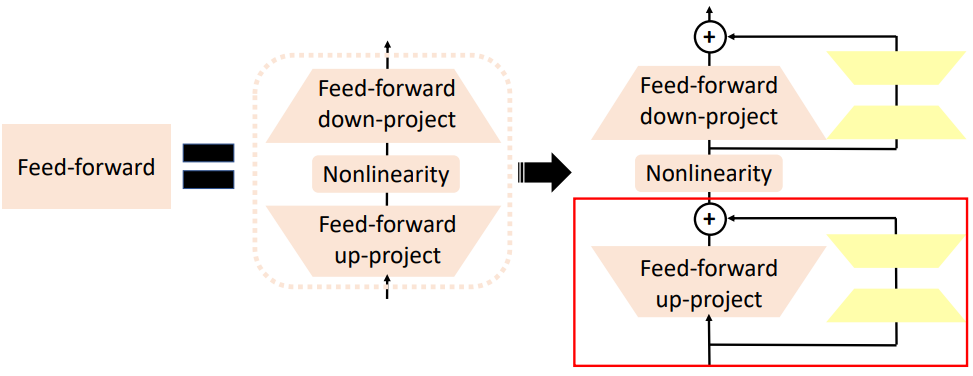
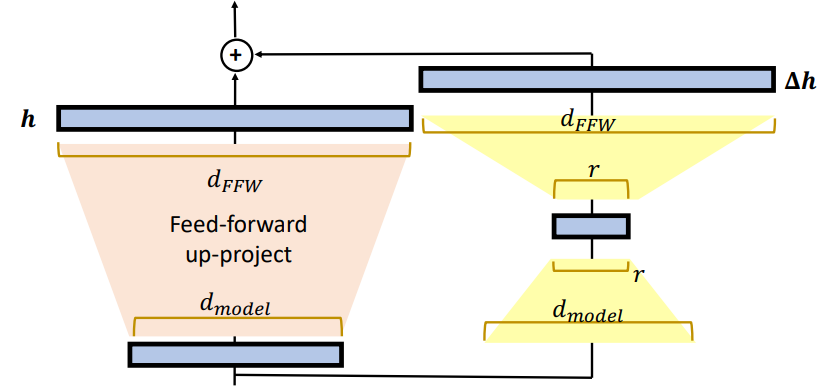
只在 Feed-forward 层,增加 Low-Rank Adaptation。
Prefix Tuning
Prefix Tuning 是 Prompt 中的一种方法,它也是高效训练的一种设计。只更新 Prefix 的参数。
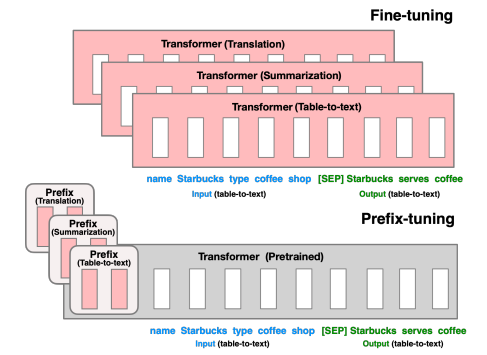
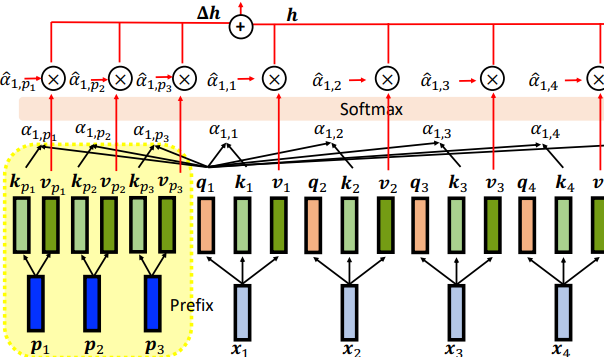
另外,使用了这种形式的 Prompt Tuning 对于多任务训练,有更高的效率。
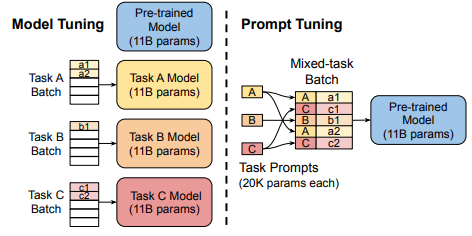
直接将不同的 prefix 一起多任务训练。这比 PET 这种“老古董模型”效率上强多了。ref
混合型
TOWARDS A UNIFIED VIEW OF PARAMETER-EFFICIENT TRANSFER LEARNING 结合了几种常见方法:
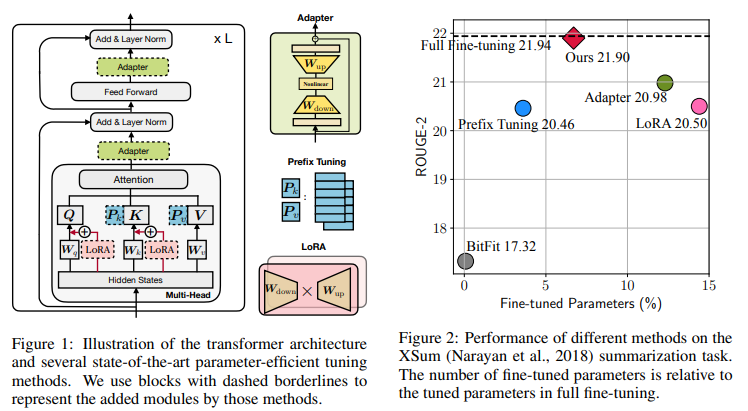
得到更好的效果。另外总结了几种常见的形式。
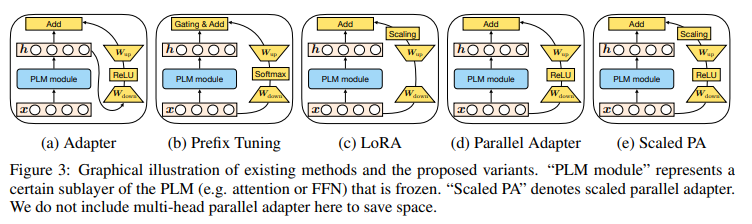
Early Exit
另一种思路,不是 Adaptor 类型的,但是放在这里一起对比了。
这种方法认为,模型在越高的层的输出存在 over thinking 的可能。所以,考虑提前结束训练,在较低的层就输出。
有几种方法:
Multi Exit
在每一层都设置一个输出层,联合每一层输出进行损失计算,并给更高的层更大的权重。最后选择其中一层最为 inference 输出。可以指定某一层。动态输出的方法有下面几种。
Shallow-deep
Shallow-deep其中使用方法是,对于每一层分类结果,选择第一个大于某个阈值的层,进行最终输出。
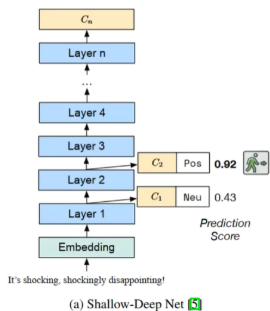
DeeBERT
DeeBERT 相比Shallow-deep,只是指标不一样,使用entropy进行比较。
PABEE
PABEE 思路比较简单,模型从下往上层,连续输出同一个 label 的次数超过限制,就进行输出。
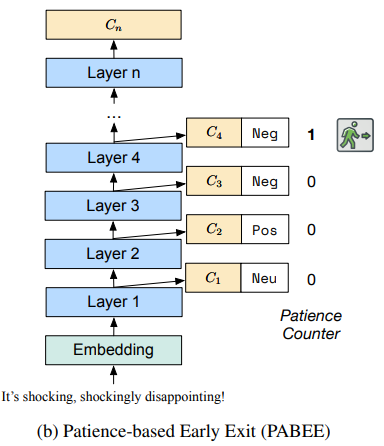
对于分类任务,次数限制设计为:
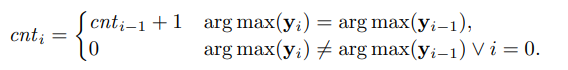
回归任务:
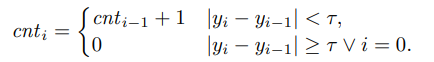
其他
Apdaptor 设计方式,在实验中更不易过拟合,并且模型迁移训练效果更好。对于小数据集也有不错的效果。
长序列优化
主要针对 self-attention 在长序列任务上的大计算量进行设计优化。
思路有几种:
- Longformer, BigBird: 更改attention window,设计局部 attention,空洞 attention,随机 attention,以及只对部分词进行全局 attention,这些方法一起使用。
- Reformer:对key 和 query先进性内存聚类,再按簇进行attention。
- Linformer:对key进行线性变换,降低key的个数。
- Efficient attention,Linear Transformer,Performer:将query和key的矩阵计算,经过一个变量分解,因为长序列这两个的计算量会O(n^2)级变大,而且这是可以通过类似核函数的方法进行分解的。将key和value的计算先进性,有效减少计算量。关键就是这个变换的设计形式。
- Synthesizer:不计算得到 attention weights 了,直接设为设计的固定参数矩阵。
- MLP-Mixer,Fnet:attention free,直接不attention了,使用其他方式。不同维度全连接层融合,或者转化到“频域”进行融合。
有空整理。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!