Vision to text
视觉问答任务的定义是对于一张图片和一个跟这幅图片相关的问题,机器需要根据图片信息对问题进行回答。
- 输入:一张图片和一个关于图片信息的问题,常见的问题形式有选择题,判断题
- 输出:挑选出正确答案
视觉问答任务本质上是一个多模态的研究问题。这个任务需要我们结合自然语言处理(NLP)和计算机视觉(CV)的技术来进行回答。
- 自然语言处理(NLP)
- 举一个在NLP领域常见的基于文本的Q&A问题:how many bridges are there in Paris?
- 一个NLP Q&A 系统需要首先识别出这是一个什么类型的问题,比如这里是一个“how many” 关于计数的问题,所以答案应该是一个数字。之后系统需要提取出哪个物体(object)需要机器去计数,比如这里是 “bridges“。最后需要我们提取出问题中的背景(context),比如这个问题计数的限定范围是在巴黎这个城市。
- 当一个Q&A系统分析完问题,系统需要根据知识库(knowledge base)去得到答案。
- 机器视觉(CV)
- VQA区别于传统的text QA在于搜索答案和推理部分都是基于图片的内容。所以系统需要进行目标检测(object detection),再进行分类(classification),之后系统需要对图片中物体之间的关系进行推理。
VQA Notes
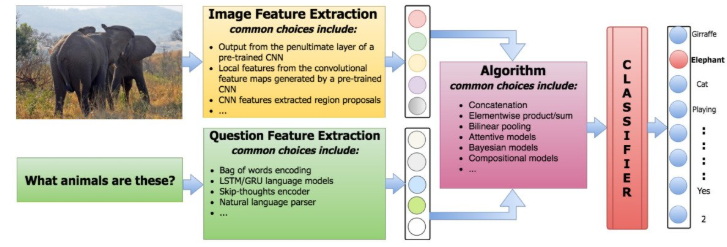
基于图像信息和文本信息匹配的VQA
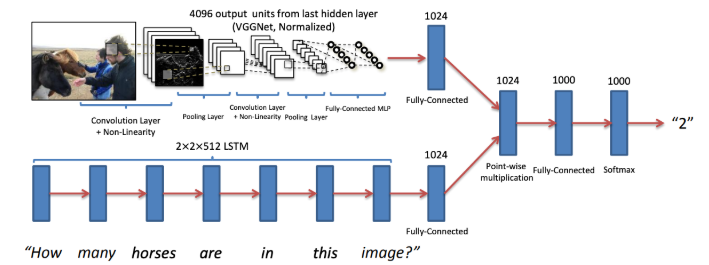
通常,一个VQA系统包含了以下三个步骤:
- 抽取问题特征
- 抽取图片特征
- 结合图片和问题特征去生成答案
基于注意力(attention)的VQA
VQA方案是使用位置注意力(spatial attention)去生成关于区域(region)的位置特征,并训练一个CNN网络。一般有两种方法去获得一张图片关于方位的区域。
- 划分成网格状(grid),并根据问题与图片特征去预测每一个网格的attention weight,将图片的CNN的feature通过加权求和的方式得到attention weighted feature,再通过attention weighted feature发现相对比较重要的区域
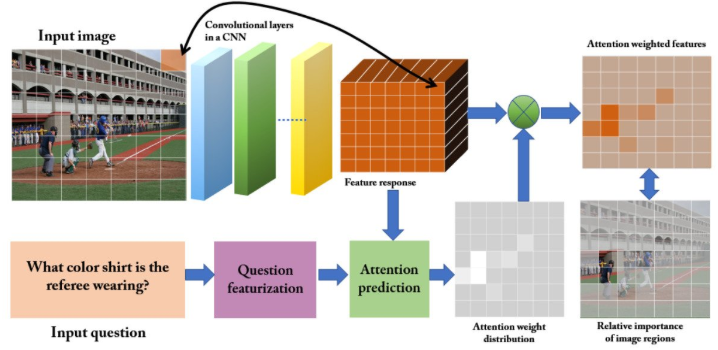
- 目标识别的方式生成很多bounding box。

根据生成的区域(region),使用问题去找到最相关的区域,并利用这些区域去生成答案。
Stacked Attention
Stacked Attention,多次重复question-image attention。
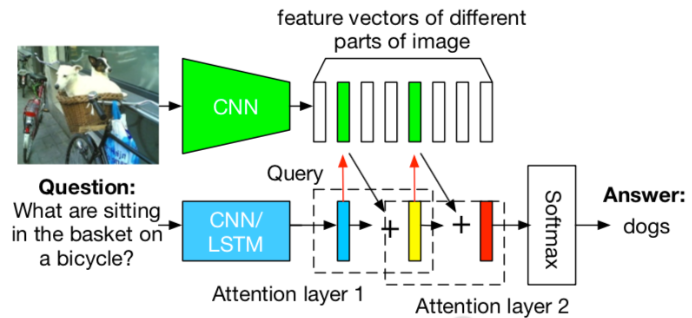
- 图片使用CNN 编码 \[\phi = CNN(I)\]
- 问题使用LSTM编码 \[s= LSTM(E_q)\]
- Stacked Attention \[\alpha_{c,l} \propto \exp F_c(s, \phi_l) ,~~ \sum_{l=1}^L \alpha_{c,l}=1, ~~ x_c = \sum_l \alpha_{c,l}\phi_l\]
- classifier, 其中G=[G_1, G_2, ..., G_M]是两层的全连接层 \[P(a_i|I,q) \propto \exp G_i(x,s),~~ x=[x_1, x2,...,x_C]\]
Image captioning
基本模型
常见的image captioning 系统是由一个CNN+RNN的编码解码模型完成。类比一下machine translation系统,通常由一个RNN encoder + RNN decoder组成。
图像编码
Vinyals et al. (2014) Show and Tell: A Neural Image Caption Generator 这篇文章将seq2seq模型中的LSTM encoder换成CNN encoder,用于提取图片的信息,得到一个固定长度的内容向量(context vector),之后通过一个RNN decoder,将信息使用文字的方式解码出来。
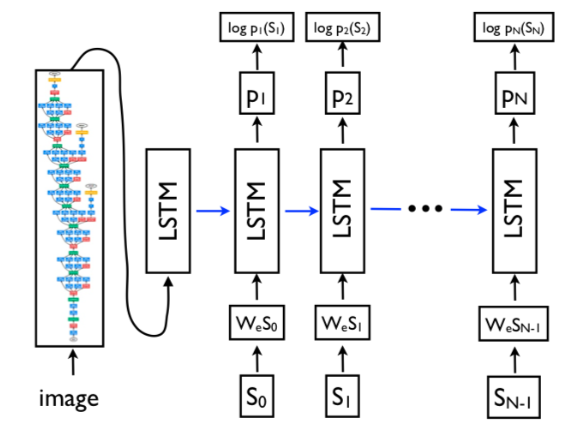
结合注意力机制 - Kelvin et al. (2014) Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
- 类比人看图说话:当人在解说一幅图片的时候,每预测一个字,会关注到图片上的不同位置。
- 在解码器预测文字的时候,会关注到跟当前文字内容和图片最相关的位置。
注意力机制
- 一张图片的卷积层中的向量有14x14=196个feature maps \(a_i, i=1...196\),每个feature map对应于每个图片中不同的高亮位置。
- 注意力机制通过计算每个feature map与当前的hidden state计算两者之间的相关度,这里的hidden state \(h_{t-1}\) 总结了已经生成的1到t-1个单词的内容。 \[e_{ti}=f_{att}(a_i, h_{t-1}) \\ \alpha_{ti} = {\exp(e_{ti}) \over \sum_{k=1}^L \exp(e_{tk}) }\]
- 之后通过加权求和得到注意力内容向量 \(\hat{z}_t\)。 \[\hat{z}_t=\phi(\{a_i\}, \{\alpha_i\})\]
- 通过将196个feature maps求平均值去初始化LSTM中的 memory cell \(c_0, h_0\)
- 根据图片及已经生成的部分单词,去预测下一个单词 \[c_0 = f_{init,c}({1\over L} \sum_i^L a_i) \\ h_0 = f_{init,h}({1\over L} \sum_i^L a_i) \\ p(y_t|a, y_1^{t-1}) \propto \exp(L_o (E y_{t-1} + L_h h_t + L_z \hat{z}_t))\]
beam search 优化
每次预测下一个单词的时候,计算当前所有路径的log-likelihood并进行排序, 只保留log-likelihood 最大值的K个beams。
目标识别
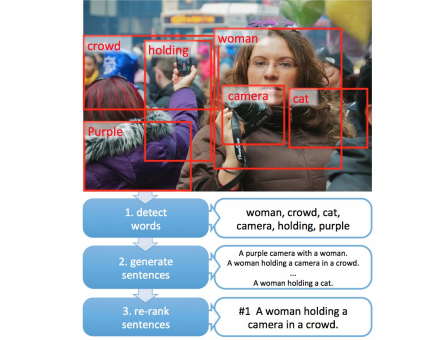
Fang et al 2014, From Captions to Visual Concepts and Back, 提供了另一个image caption系统的思路。
- 预测文字: 使用一个CNN去做目标识别,并且根据bounding box生成可能出现的文字
- 生成句子:通过一个统计语言模型,生成很多个可能的句子集合
- 重新排序已经生成的句子: 通过学习一个Deep Multimodal Similarity Model (DMSM)去重新排序所有可能的句子集合,取最高分数的句子作为系统输出。
评估指标
常见的image captioning 系统的评估指标使用的是
- BLEU, 是常见的机器翻译系统的评估指标,计算的是一句预测的文字与人类标注的参考文字之间的n-gram 重合度(overlap)。
- METEOR, 也是常见的机器翻译系统的评估指标,其通过建立一个短语词表(phrase table),考虑了输出文本是否使用了相似短语。
- CIDEr, 考虑了句子中的文字与图片的相关性
- ROUGE-L,是text summarization的评估指标
- SPICE 是专门设计出来用于 image caption 问题的。全称是 Semantic Propositional Image Caption Evaluation。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!