A Sentence Embedding Baseline
论文《A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS》
Info:
- 类别: [engineering ; pragmatic]
- 研究目标
- 提升Towards universal paraphrastic sentence embeddings(John Wieting, Mohit Bansal, Kevin Gimpel, and Karen Livescu. )论文提出的监督学习方法,转而进行无监督学习。
- 提升基于word embedding的句子向量的表现力。
- 研究成果:
- completely unsupervised sentence embedding
- improves performance by about 10% to 30% in textual similarity tasks, and beats sophisticated supervised methods including RNN’s and LSTM’s.
- new “smoothing” terms that allow for words occurring out of context, as well as high probabilities for words like and, not in all contexts.
- 存在的问题:
- 在sentiment相关任务上,效果一般,与LSTM相差较大。
- 在下游任务为监督学习任务时,效果一般,没有LSTM、Skip-thought等方法有效。
- 关键词:sentence embedding,无监督学习
Brief Summary:
这项工作提供了一种简单的句子嵌入方法,基于随机游走模型生成句子文本(Arora et al., 2016)。它简单且无监督,但在各种文本相似性任务上,它的性能明显优于基线,甚至可以击败一些复杂的监督方法,如RNN和LSTM模型。获得的embedding可以作为下游监督任务的特征,与复杂方法相比也能获得不错的结果。
Main Thought:
简单且无监督的Sentence embeddings计算方法。
在 textual similarity tasks上,当选取了合适参数,效果相比于词向量的简单平均、LSTM、Skip-thought等方法有一定提升。
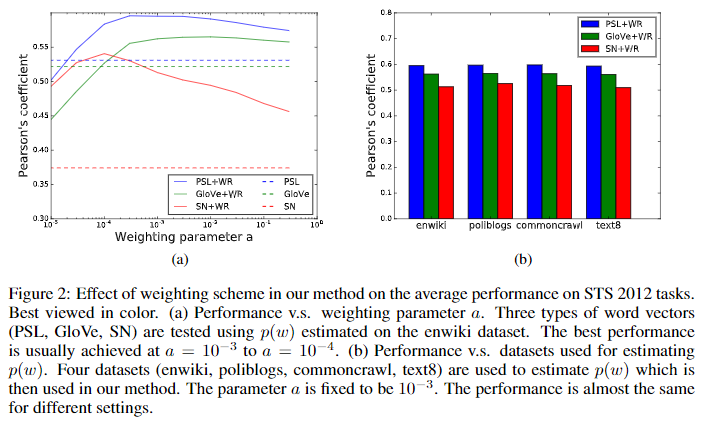
- 上图b中,在不同的领域都是有用的。这对于无监督方法尤其重要,因为未标记的可用数据可以从目标应用程序的不同域中收集。
在下游任务为监督学习任务时,效果下降的原因
- 这可能是因为similarity任务直接依靠余弦相似性, 这使得该方法倾向于removing the common components(可视为一种去噪denoising)。
- 而在监督任务, 由于有一些标签的信息用于训练, 分类器可以挑出有用少见的components和忽视常见的components。
无视词序
然而基于LSTM、RNN的结果表明,词序在similarity任务上是有作用的。本文方法忽视了次序,可以考虑两者结合。
忽略词序的方法,更能找到sentiment层面的信息。
与Word2vec的联系
- Word2vec使用子采样(sub-sampling)技术对单词w进行下采样,概率与1 /√p(w)成正比,其中p(w)是单词w的边缘概率。这种启发式方法不仅可以加快训练速度,而且学习了更常见的单词表示形式。
- 该文章模型中,对词向量进行隐式加权,因此在一些场景下可以更好的利用文档的统计信息。
Method
- latent variable generative model for text
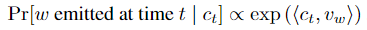
\(c_t\)为来自latent random walk的句子向量。使用MAP方法预测下一个(time t)生成的词的概率。
- Improved Random Walk model.
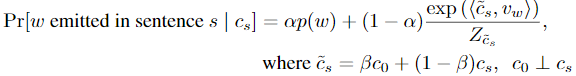
添加两个smooth项。\(p(w)\): 即使单词的向量与\(c_s\)的内积非常低,单词也可能出现。\(c_0\): 与语法相关的sentence向量校正项,保证最重要的向量维度处于主导地位。它提高了与\(c_0\)方向相近的单词在模型中的共现概率。
- Computing the sentence embedding
假设\(Z\)是一个常量

越常见的word \(w\),权重\(a/(p(w) +a)\)就越小,可以使embedding专注于具有代表性的词。
为了删去没有代表性的信息,计算\(c_0\)的方向为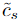 矩阵的第一个主成分(不进行 centralizing)。
矩阵的第一个主成分(不进行 centralizing)。

Notes:
PMI: Pointwise Mutual Information \[ PMI = log \frac{p(u, v)}{p(u)p(v)} \]
pPMI = max(0,PMI): positive Pointwise Mutual Information
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!