B+、B-link、LSM数据库常用数据结构分析
数据库结构
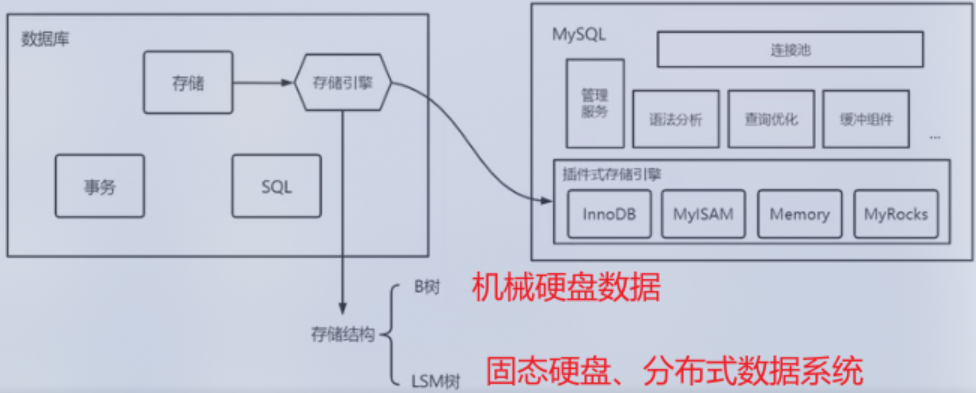
存储结构
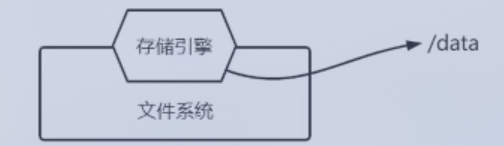
存储文件类型:数据文件 + 索引文件。
文件组织形式
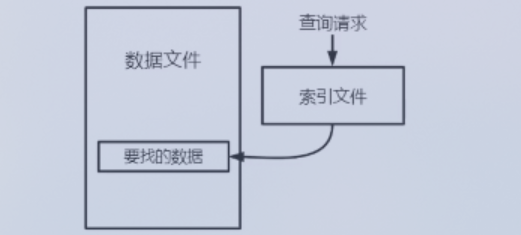
索引组织表
将 数据记录 存储在 索引文件 内部。代表:InnoDB。
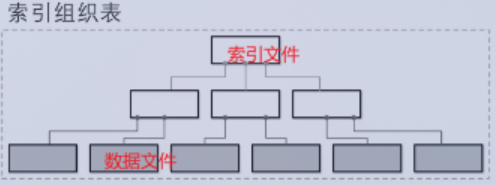
堆组织表/哈希组织表
数据记录 存储在 无序堆 中。索引和数据分离。主流一般没用哈希组织表。代表:Oracle、PostgreSQL。
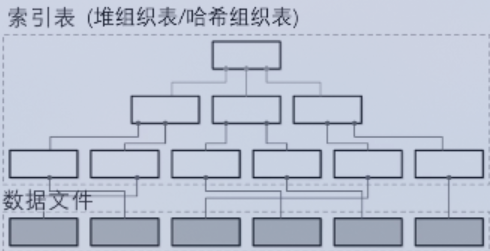
其写入性能比 索引组织表 高,读取性能比 索引组织表 低。但是总体上对性能影响较小。 其中索引文件组织形式,对性能影响更大。一般是B树或者LSM树。存储结构所指的也就是针对索引文件而言。
存储结构分类
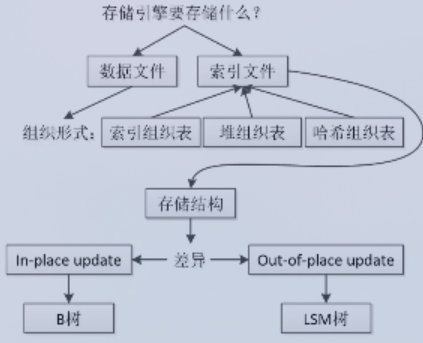
In-place update: 直接覆盖旧记录。方便读,但是更新会导致随机IO (IO了多个数据页才找到目标) 到目标位置,性能降低。
随机IO,比如中序遍历 B树 所造成的IO
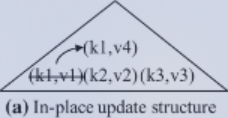
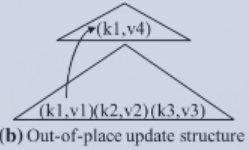
Out-of-place update: 将新内容存到新位置,而不是覆盖,所以查询时需要查找多个位置。但是这很契合固态硬盘(覆盖需要先擦除旧数据)和分布式数据库(本来就是多个位置存储、查询)。同时,为了防止数据无限膨胀,需要进行数据整合(Compaction)。
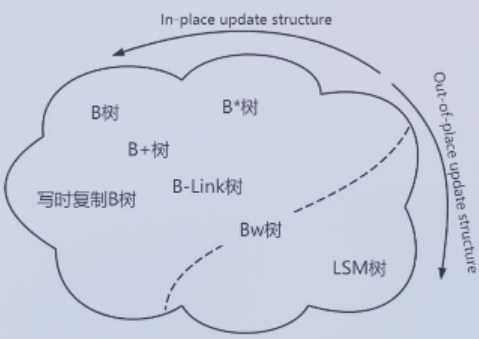
存储结构的共性
- 适合磁盘存储,粒度大,一次读取一片连续区域,IO尽量少。
- 允许并发操作,粒度小,增删改 对存储结构的影响尽量小。 满足1不满足2的结构:大文件、数组,一旦修改,就要锁住整个文件。 满足2不满足1的结构:链表、红黑树、跳表、哈希表。增删改 影响较小,但是读取的粒度也很小。 同时满足两个条件:B树、B+树、LSM树等。
存储引擎并发和事务并发的不同
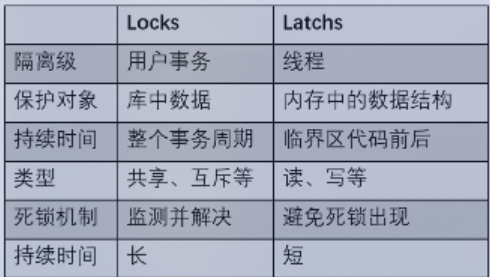
比如修改一条数据,首先是将对应页的数据加载到内存中,然后在该线程中上Latch锁,防止其他线程修改数据,当数据修改完成后释放Latch。 对于所要修改的那一条数据记录,加上事务锁Lock防止其他并发事务修改,当事务提交后释放Lock,此时Latch已经被释放了。
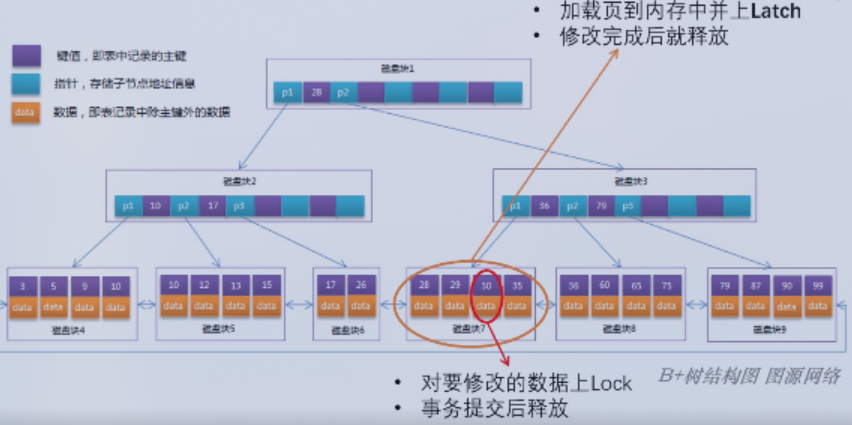
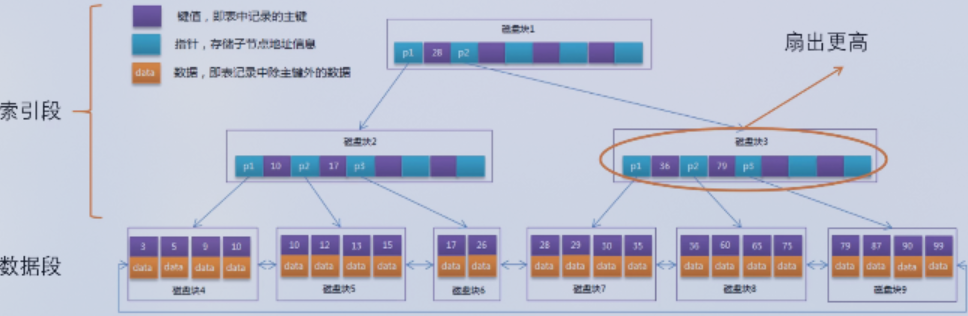
注意,上图中是B+树,非叶子节点只存储索引,叶子结点存储数据记录。
存储引擎锁机制
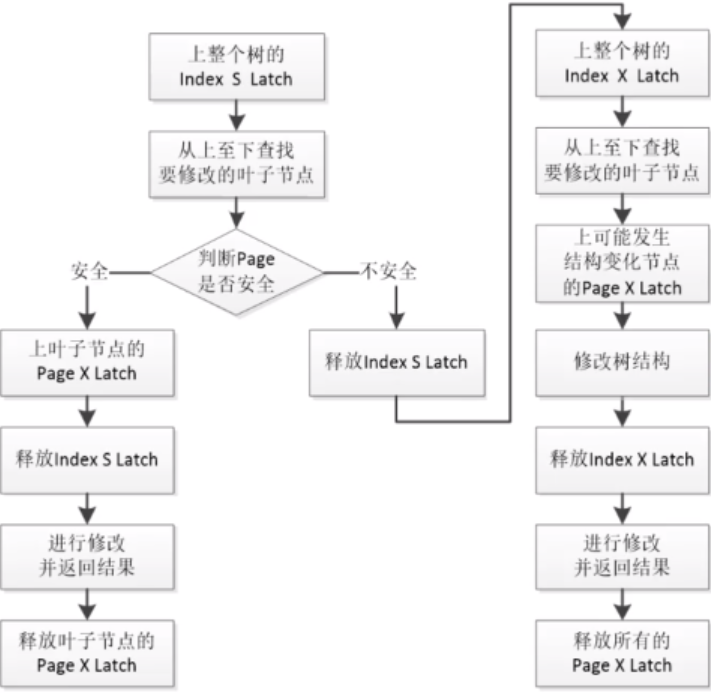
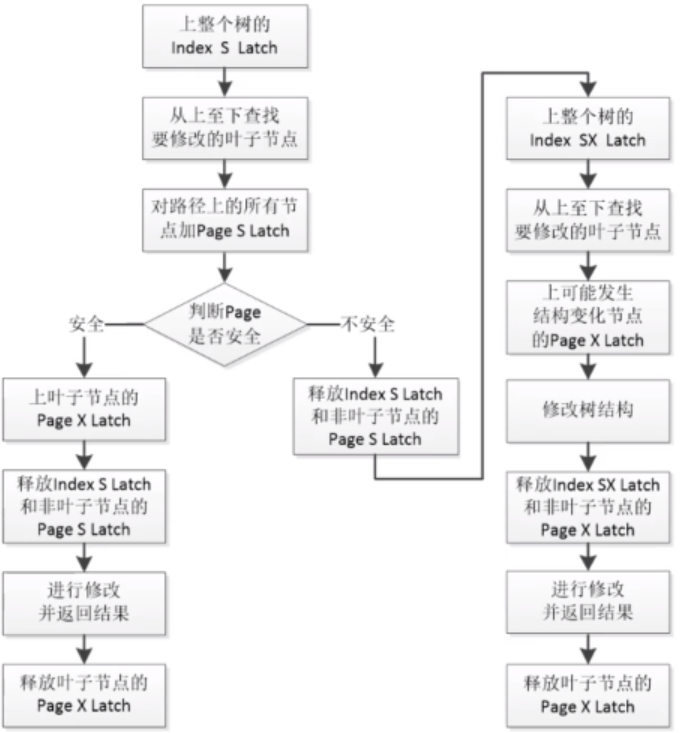
MySQL 5.6之前并发控制机制,S Latch 表示写锁,X Latch 表示写锁:
MySQL 5.7 8.0 并发控制机制,加入了和 S Latch 兼容的 SX Latch,两者可以同时上锁,也就是说,当对索引树修改时,也可以进行读操作,不阻塞。
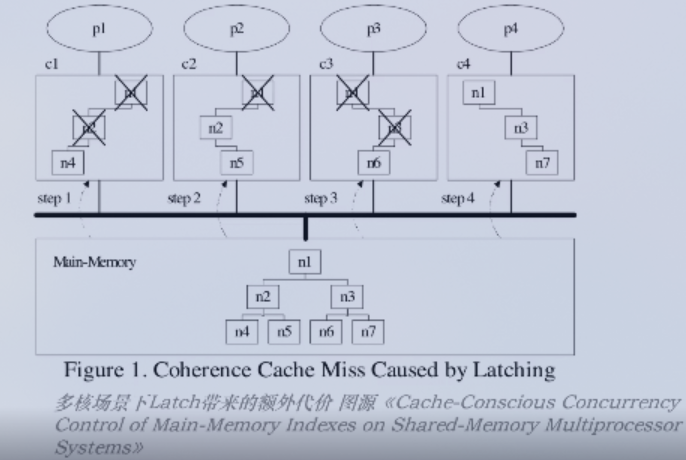
多核处理器中Latch代价
多个CPU核,每个都有独立的存储区域。读取和写入过程,需要把页数据加载到这块区域中。假如一个节点页数据(比如B树的根节点)同时存在于多个核的存储区域,此时加Latch锁和解Latch锁的操作必须同步给多个核,就会造成很多性能损耗。
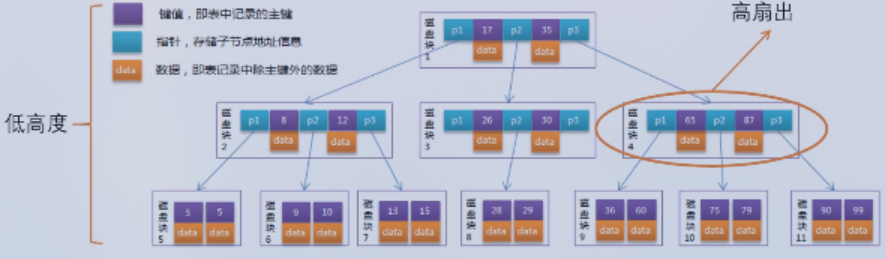
B树
- 每个数据只存储一份
- 以页为单位组织,InnoDB中一页16K,一页可以存储几百上千个指针
- 树高度低,读取数据块较大
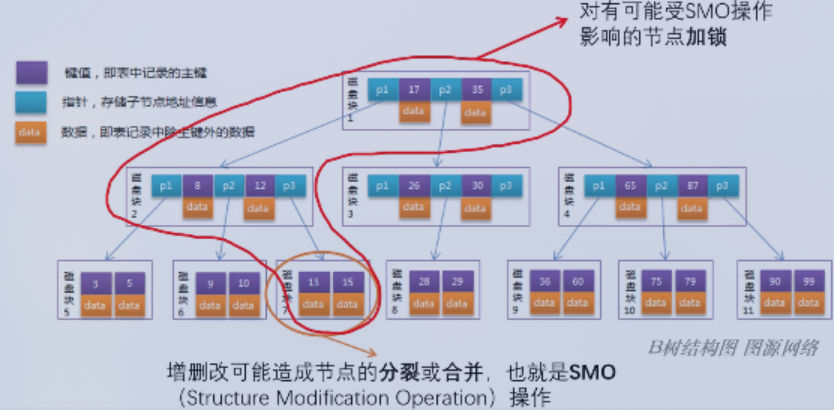
- 增删改 可能造成节点的分裂和合并(SMO,Structure Modification Operation),需要对可能发生分裂或者合并的节点数据进行加锁,导致并发操作性能不理想。
B树优化变种
- B+树:优化IO,非叶子节点只存储索引指针,叶子结点存储数据记录,各叶子节点连接成双向循环链表。区分出索引段和数据段,扫描全表时顺序IO得到优化。
这里优化IO,是因为叶子结点不会存储数据,而只是作为搜索索引,遍历索引不会对数据记录进行IO,这降低了索引IO的负担,一次读取更多的索引,IO性能自然更好。
- B* 树:优化空间利用率,分裂节点时,当相邻两个空间都满时,分裂出三个节点。
- B-Link:优化并发操作,对树的节点上锁时,可以不对整个树上锁,而是从下到上,只锁到需要修改的节点。
- Bw: 采用类似LSM树的out-of-place update方法,追加写入方式,完全没有Latch。
LSM树
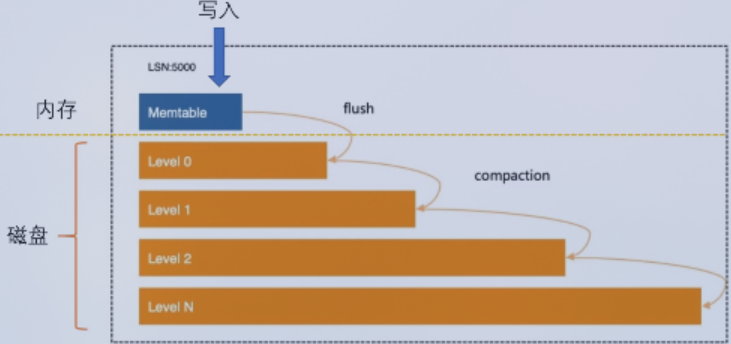
SSD读性能提升,弥补了LSM读取性能低的劣势。同时LSM树写数据的方式,对SSD的友好,不会频繁擦除数据,增加设备使用寿命。 LSM树是多层结构,下层数据越来越多。写入操作都是写入内存,写满规定容量后,就会将内存数据追加插入磁盘。通过对不同层间数据排序去重,压缩占用空间。
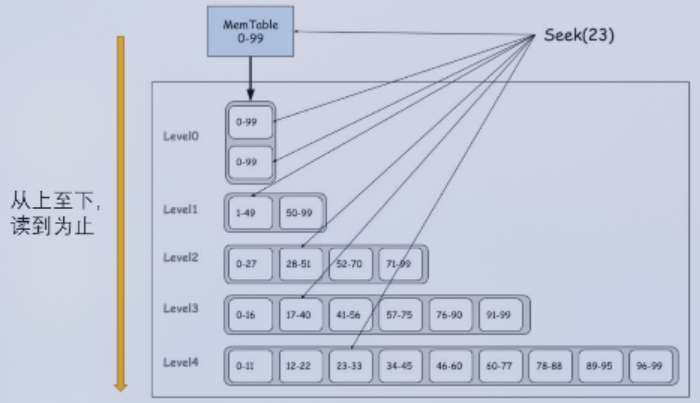
读取数据,以最新的为准。
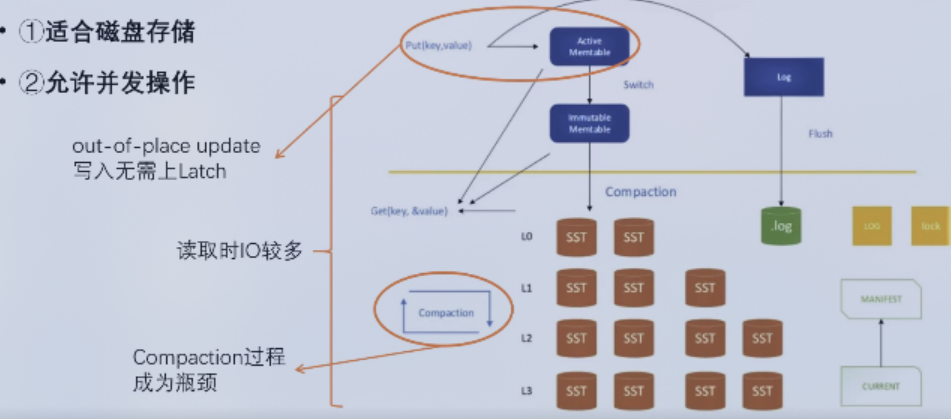
LSM树存储引擎结(RocksDB)构图。
- 写入数据先写 write ahead log
- 内存中数据结构使用 Skip List
- 数据落盘到 L0 层不进行合并,所以会有重复数据
- 数据达到需要写入下层的量时,创建 SST(Sorted String Table) 类似一个小型的子数据库结构
- 每层之间,向下落盘时,只合并重叠的部分,每层数据不重叠
- 查找时,使用 Bloom Filter (将key值通过多个hash函数,映射到bit array中不同的index位置,查看是否都是1,表示查找命中),不会返回假阴性(false positive)结果,就是查找结果时不在的,就一定不在
- 合并策略可以是合并后替换下层数据,也可以是将上层合并的结果放入下一层,而不进行写替换
不实际替换的写效率显然是更高的。这点在设计频繁写入的数据结构时,是可以借鉴这种延迟替换的实现方式的。
对 Compaction 操作,有一些优化方案:
- 读、合并、写入操作流水线化
- Compaction 之后,主动更新 Cache
- 采用单独设计的FPGA硬件,负责 Compaction 操作,减少CPU负担。
追加写入,没有SMO过程。没有B树存在的Latch导致的问题。 但是,LSM读取数据时,可能会多层多次读取,每层数据较多,缓存Miss情况可能会多一些,读性能收到影响。 另外,虽然写入过程没有SMO,但是Compaction过程是存在SMO问题的,还存在缓冲丢失、write stall(写停顿)等问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!