中文文本处理
中文文本基本任务与处理
1.分词
中文和日文单纯从文本形态上无法区分具备独立含义的词(拉丁语系纯天然由空格分隔不同的word)。因此在很多中文任务中,我们需要做的第一个处理叫做分词。
- 主流的分词方法主要是基于词典匹配的分词方法(正向最大匹配法、逆向最大匹配法和双向匹配分词法等)和基于统计的分词方法(HMM、CRF、和深度学习);‘
- 主流的分词工具库包括 中科院计算所NLPIR、哈工大LTP、清华大学THULAC、Hanlp分词器、Python jieba工具库等。
最大匹配法
最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。
双向最大匹配法:正向最大匹配和逆向最大匹配两种算法都切一遍,然后根据大颗粒度词越多越好,非词典词和单字词越少越好的原则,选取其中一种分词结果输出。
“我们在野生动物园玩”
- 正向最大匹配法:“我们/在野/生动/物/园/玩”,其中,单字字典词为2,非词典词为1。
- 逆向最大匹配法:“我们/在/野生动物园/玩”,其中,单字字典词为2,非词典词为0。
非字典词:正向(1)>逆向(0)(越少越好) 单字字典词:正向(2)=逆向(2)(越少越好) 总词数:正向(6)>逆向(4)(越少越好)
因此最终输出为逆向结果。
2.去停用词与N-gram
同英文
3.词性标注
词性标注(part-of-speech tagging),又称为词类标注或者简称标注,是指为分词结果中的每个单词标注一个正确的词性。
在汉语中,词性标注比较简单,因为汉语词汇词性多变的情况比较少见,大多词语只有一个词性,或者出现频次最高的词性远远高于第二位的词性。
4.句法依存分析
依存句法分析(Dependency Parsing, DP) 识别句子中的“主谓宾”、“定状补”这些语法成分,并分析各成分之间的关系。
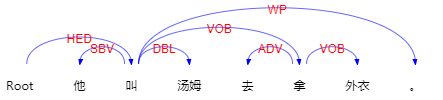
依存句法分析标注关系(共14种) 及含义如下(哈工大开源包使用):
| 关系类型 | Tag | Description | Example |
|---|---|---|---|
| 主谓关系 | SBV | subject-verb | 我送她一束花(我<–送) |
| 动宾关系 | VOB | 直接宾语,verb-object | 我送她一束花(送–> 花) |
| 间宾关系 | IOB | 间接宾语,indirect-object | 我送她一束花(送–> 她) |
| 前置宾语 | FOB | 前置宾语,fronting-object | 他什么书都读(书<–读) |
| 兼语 | DBL | double | 他请我吃饭(请–> 我) |
| 定中关系 | ATT | attribute | 红苹果(红<–苹果) |
| 状中结构 | ADV | adverbial | 非常美丽(非常<–美丽) |
| 动补结构 | CMP | complement | 做完了作业(做–> 完) |
| 并列关系 | COO | coordinate | 大山和大海(大山–> 大海) |
| 介宾关系 | POB | preposition-object | 在贸易区内(在–> 内) |
| 左附加关系 | LAD | left adjunct | 大山和大海(和<–大海) |
| 右附加关系 | RAD | right adjunct | 孩子们(孩子–> 们) |
| 独立结构 | IS | independent structure | 两个单句在结构上彼此独立 |
| 核心关系 | HED | head | 指整个句子的核心 |
5.语义依存分析
Semantic Dependency Parsing, SDP,分析句子各个语言单位间的语义关联。
使用语义依存刻画句子语义,好处在于不需要去抽象词汇本身,而是通过词汇所承受的语义框架来描述该词汇。
语义依存分析目标是跨越句子表层句法结构的束缚,直接获取深层的语义信息。
例如以下三个句子,用不同的表达方式表达了同一个语义信息,即张三实施了一个吃的动作,吃的动作是对苹果实施的。
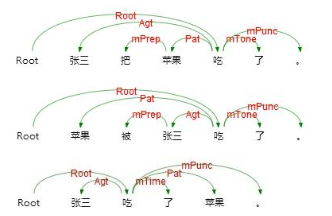
语义依存分析不受句法结构的影响,将具有直接语义关联的语言单元直接连接依存弧并标记上相应的语义关系。
语义依存关系分为三类,分别是
- 主要语义角色,每一种语义角色对应存在一个嵌套关系和反关系;
- 事件关系,描述两个事件间的关系;
- 语义依附标记,标记说话者语气等依附性信息。
http://ltp.ai/demo.html,http://ltp.ai/docs/index.html:哈工大开源包网站
6.语法解析
句子可以用主语、谓语、宾语来表示。在自然语言的处理过程中,有许多应用场景都需要考虑句子的语法,因此研究语法解析变得非常重要。
语法解析有两个主要的问题,其一是句子语法在计算机中的表达与存储方法,以及语料数据集;其二是语法解析的算法。
表达与存储
用树状结构图来表示
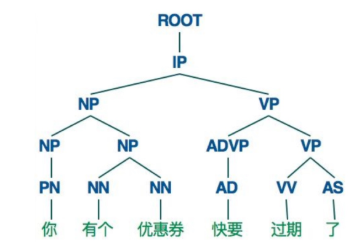
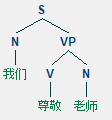
NP、VP、PP是名词、动词、介词短语(短语级别);N、V、P分别是名词、动词、介词。
语法解析的算法
上下文无关语法(Context-Free Grammer)
为了生成句子的语法树,我们可以定义如下的一套上下文无关语法。
•1)N表示一组非叶子节点的标注,例如{S、NP、VP、N...}
•2)Σ表示一组叶子结点的标注,例如{我们、尊敬...}
•3)R表示一组规则,每条规则可以表示为
•4)S表示语法树开始的标注
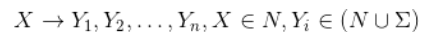
当给定一个句子时,我们便可以按照从左到右的顺序来解析语法。
例如,句子the man sleeps就可以表示为(S (NP (DT the) (NN man)) (VP sleeps))。
规则R示例如下:
S -> NP VP VP -> V NP | V NP PP PP -> P NP
V -> "saw" | "ate" NP -> "John" | "Mary" | "Bob" | Det N | Det N PP Det -> "a" | "an" | "the" | "my" N -> "dog" | "cat" | "cookie" | "park" P -> "in" | "on" | "by" | "with"
概率分布的上下文无关语法(Probabilistic Context-Free Grammar)
上下文无关的语法可以很容易的推导出一个句子的语法结构,但是缺点是推导出的结构可能存在二义性。
由于语法的解析存在二义性,我们就需要找到一种方法从多种可能的语法树种找出最可能的一棵树。
一种常见的方法既是PCFG (Probabilistic Context-Free Grammar)。除了常规的语法规则以外,我们还对每一条规则赋予了一个概率。对于每一棵生成的语法树,我们将其中所有规则的概率的乘积作为语法树的出现概率。
分别计算每颗语法树的概率p(t),出现概率最大的那颗语法树就是我们希望得到的结果,即argmax p(t)。
训练算法:
算法依赖于CFG中对于N、Σ、R、S的定义以及PCFG中的p(x)。
- 统计出语料库中所有的N和Σ
- 利用语料库中的所有规则作为R
- 针对每个规则A -> B,从语料库中估算p(x) = p(A -> B) / p(A)
在CFG的定义的基础上,重新定义一种叫Chomsky的语法格式。这种格式要求每条规则只能是X -> Y1 Y2或者X -> Y的格式。实际上Chomsky语法格式保证生产的语法树总是二叉树的格式,同时任意一棵语法树总是能够转化成Chomsky语法格式。
语法树预测算法:
输入一个句子x1, x2, ... , xn时,计算句子对应的语法树有两种方法:
- 第一种方法是暴力遍历的方法,每个单词x可能有m = len(N)种取值,句子长度是n,每种情况至少存在n个规则,所以在时间复杂度\(O(mn^2)\)的情况下,我们可以判断出所有可能的语法树并计算出最佳的那个。
- 第二种方法当然是动态规划,我们定义w[i, j, X]是第i个单词至第j个单词由标注X来表示的最大概率。w[i, j, PP]代表的是继续往上一层递归时,只选择当前概率最大的组合方式。
缺点:
PCFG也有一些缺点,例如:1)缺乏词法信息;2)连续短语(如名词、介词)的处理等。但总体来讲它给语法解析提供了一种非常有效的实现方法。
7.命名实体识别
从一段非结构化文本中找出相关实体(triplet中的主词和宾词),并标注出其位置以及类型,它是NLP领域中一些复杂任务(如关系抽取、信息检索、知识问答、知识图谱等)的基础。
关键词抽取
文本关键词抽取,是对文本信息进行高度凝练的一种有效手段,通过3-5个词语准确概括文本的主题,帮助读者快速理解文本信息。是文本检索、文本摘要等许多下游文本挖掘任务的基础性和必要性的工作。
jieba
基本分词函数与用法
jieba.cut 以及 jieba.cut_for_search 返回的结构都是一个可迭代的 generator。
jieba.lcut以及jieba.lcut_for_search直接返回 list
添加用户自定义字典
1.可以用jieba.load_userdict(file_name)加载用户字典
2.少量的词汇可以自己用下面方法手动添加:
- 用 add_word(word, freq=None, tag=None) 和 del_word(word) 在程序中动态修改词典用
- suggest_freq(segment, tune=True) 可调节单个词语的词频,使其能(或不能)被分出来。
词性标注
1 | |
关键词抽取
基于 TF-IDF 算法的关键词抽取
import jieba.analyse
jieba.analyse.extract_tags(sentence, topK=20, withWeight=False, allowPOS=())
- sentence 为待提取的文本
- topK 为返回几个 TF/IDF 权重最大的关键词,默认值为 20
- withWeight 为是否一并返回关键词权重值,默认值为 False
- allowPOS 仅包括指定词性的词,默认值为空,即不筛选
自定义逆向文件频率(IDF)文本语料库
自定义停止词(Stop Words)文本语料库
关键词一并返回关键词权重值示例
- 用法示例见这里
基于 TextRank 算法的关键词抽取
jieba.analyse.textrank(sentence, topK=20, withWeight=False, allowPOS=('ns', 'n', 'vn', 'v')) 直接使用,接口相同,注意默认过滤词性。
jieba.analyse.TextRank() 新建自定义 TextRank 实例
基本思想:
- 将待抽取关键词的文本进行分词
- 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
- 计算图中节点的PageRank,注意是无向带权图
详解见textrank
1 | |
示例
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!