文本相似性深度学习方法
基于深度学习的语义匹配方法一般有两种类型:
- Representation-based Match:简单,速度快。
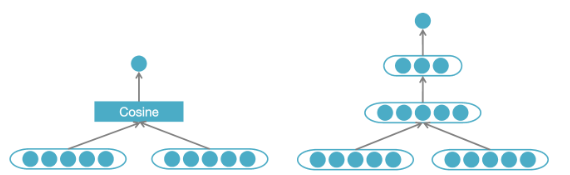
- Interaction-based Match:计算相对复杂,参数空间也更大。
Representation-based
Representation-based Match句子相似度计算的一般训练流程如下:
准备同义句数据集(比如,The Paraphrase Database,ParaNMT-50M);
选择模型结构(比如,Word Averaging,BiLSTM Averaging等);
- Word Averaging模型:平均句子中的所有词向量作为句子语义的表达
- BiLSTM Averaging模型:合并前向和反向LSTM编码得到的隐向量作为句子语义的表达
- 相对进阶一点的模型有InferSent,DSSM,CDSSM
选择负样本:
- 从当前batch中寻找与当前句子意义(根据当前模型判断)最不相近 的句子。
- 或者,Mega-batching:从更大的样本(合并多个mini batches)中寻找 意义较远的句子。
优化目标:hinge loss
- \[ \begin{array}{l} \min _{W_{c}, W_{w}} \frac{1}{|S|}\left(\sum_{\left\langle s_{1}, s_{2}\right\rangle \in S} \max \left(0, \delta-\cos \left(g\left(s_{1}\right), g\left(s_{2}\right)\right)\right.\right. \\ \left.+\cos \left(g\left(s_{1}\right), g\left(t_{1}\right)\right)\right)+\max \left(0, \delta-\cos \left(g\left(s_{1}\right), g\left(s_{2}\right)\right)\right. \\ \left.\left.+\cos \left(g\left(s_{2}\right), g\left(t_{2}\right)\right)\right)\right)+\lambda_{c}\left\|W_{c}\right\|^{2}+\lambda_{w}\left\|W_{w_{\text {initial}}}-W_{w}\right\|^{2} \end{array} \]
s之间正样本相似度要尽量接近\(\delta\),与负样本t之间相似度要尽量大。同时在正则化中加入词向量变化约束,计算之后的词向量不能和初始化使用的Glove(或其他)词向量相差过大。
InferSent
给定两个句子,预测两个句子之间的关系 (entailment隐含, contradiction互斥, neutral无关),即预测三种概率。
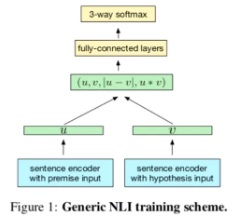
encoder作为语句特征的提取器。
训练时,若只为学习sentence representation,线性分类器也许会得到比较好的效果。为了达到更好的分类效果,可以采用更复杂的非线性分类器。
DSSM(Deep Structured Semantic Model)
微软研究院使用,用户搜索的关键词和最终点开的网页标题组成的数据,训练相似度计算模型。DSSM将语句映射到语义空间的连续表示,计算相似性。
Word Hashing
• 用于解决单词表和out of vocabulary问题 • 把单词(e.g. good)前后加上# (#good#) • 然后取所有的trigram (#go, goo, ood, od#),表示成bag of trigram 向量
原词表转换为了Compact representation,大小会变小,节省了空间。
对拼写错误有一定鲁棒性。
在大型NLP任务中可以轻松使用。
模型
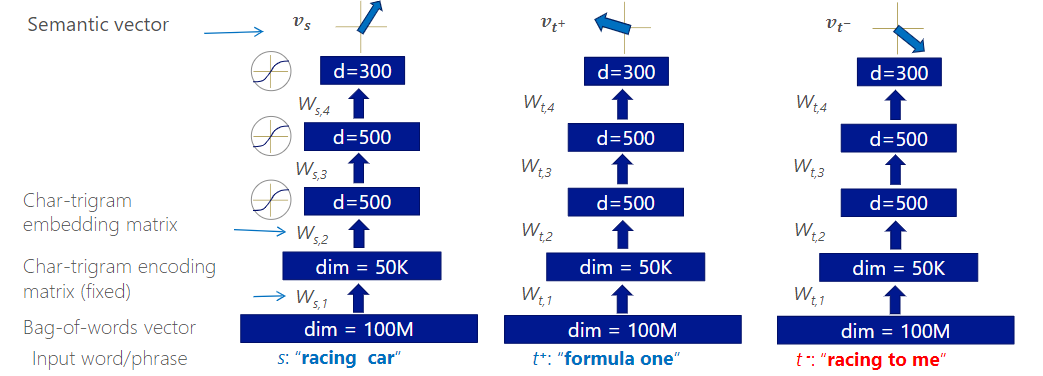
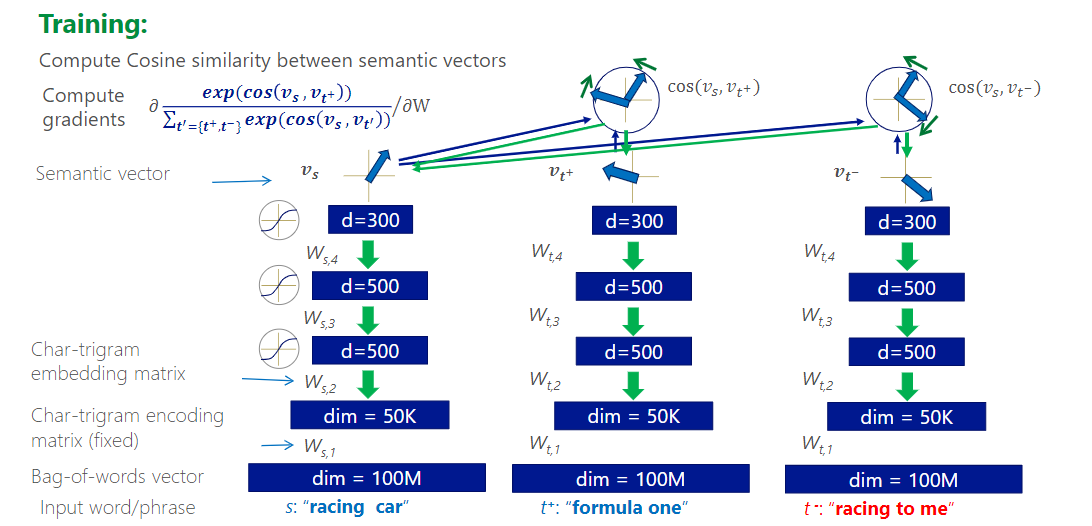
训练目标:

CDSSM
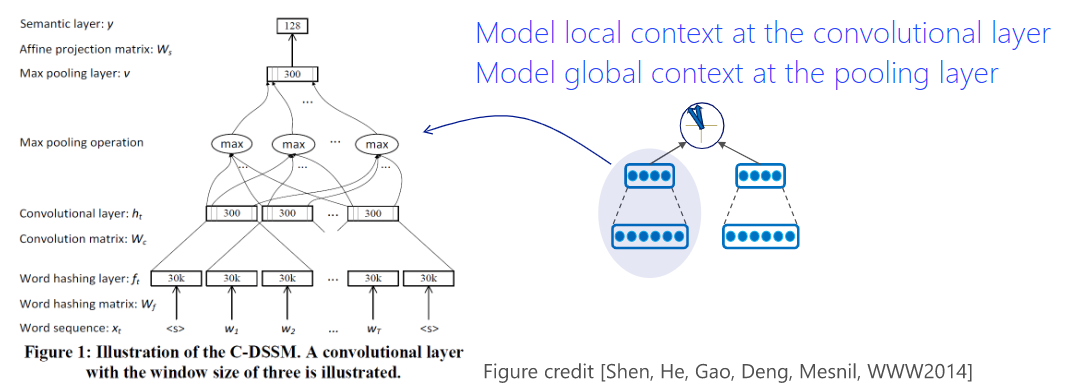
convolutional layer捕捉了局部上下文的含义。那么相同单词在不同上下文中的多义性,就可能通过模型捕捉。
global pooling捕捉语句整体的意图。实验中,一般情况下max pooling能够较准确地提取出整体语义。
Recurrent DSSM
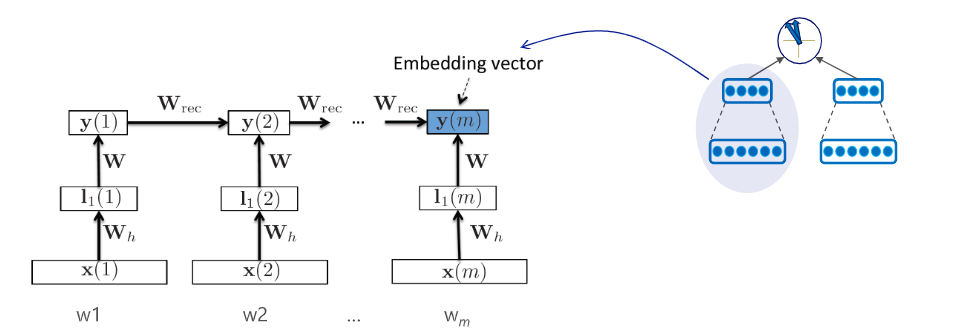
对比Seq2Seq,DSSM倾向于在语句语义空间内优化,而Seq2Seq更倾向于在word-level进行学习优化。
评价指标
NDCG a measure of ranking quality.
两个基本假设:
- 相关度越高,排名越高。
- 高度相关的排名高于部分相关,部分相关的排名高于无关。
Cumulative Gain
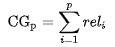
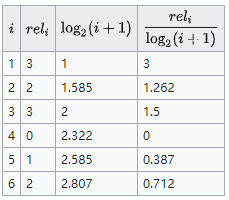
\(rel_i\) -- 是相关度分数,比如,第i个结果高度相关为5分
Discounted Cumulative Gain
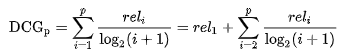
对高度相关的结果出现在ranking靠后位置时,进行惩罚。
另一个形式为:
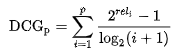
这个形式相对比较常用。
NDCG:normalized discounted cumulative gain
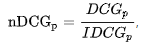
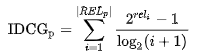
Example
令0 -- 不相关,1,2 -- 不同程度部分相关,3 -- 高度相关。相关性算法排序了前6个结果,降序:
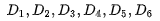
而用户数据中的相关性分数Ground Truth为,每个位置index代表一个语句:
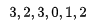
Cumulative Gain,简单相加:
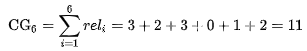
Discounted Cumulative Gain,DCG结果为:
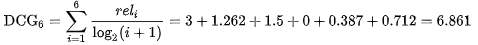
NDCG的IDCG,为期望的相关性排列顺序,即期望的最优输出:
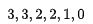

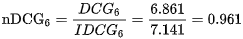
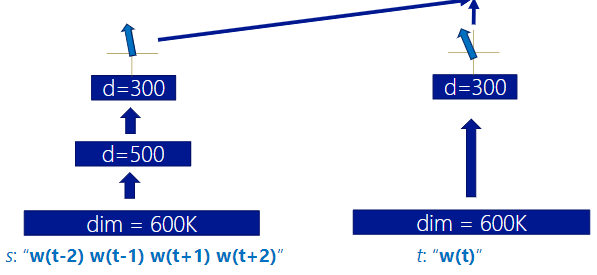
DSSM的其他应用
- 训练word embedding:上下文与中心词的语义相似性
- Knowledge Base Embedding学习
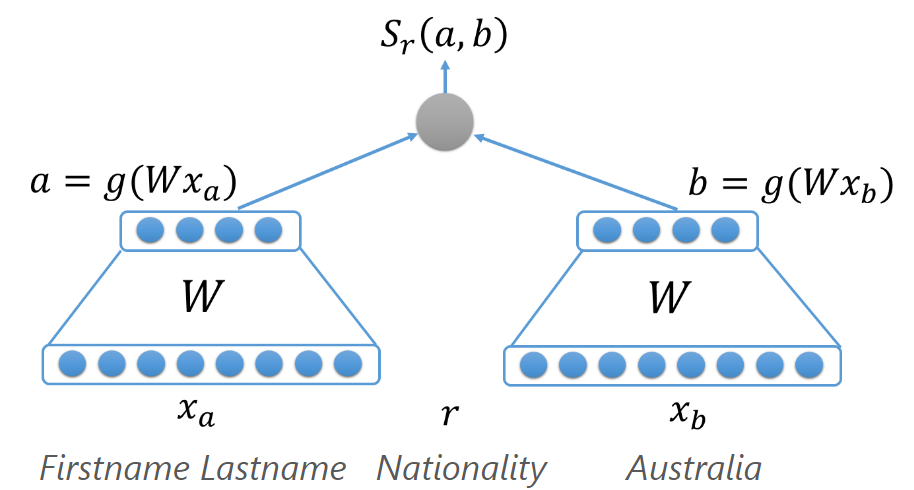
- QA
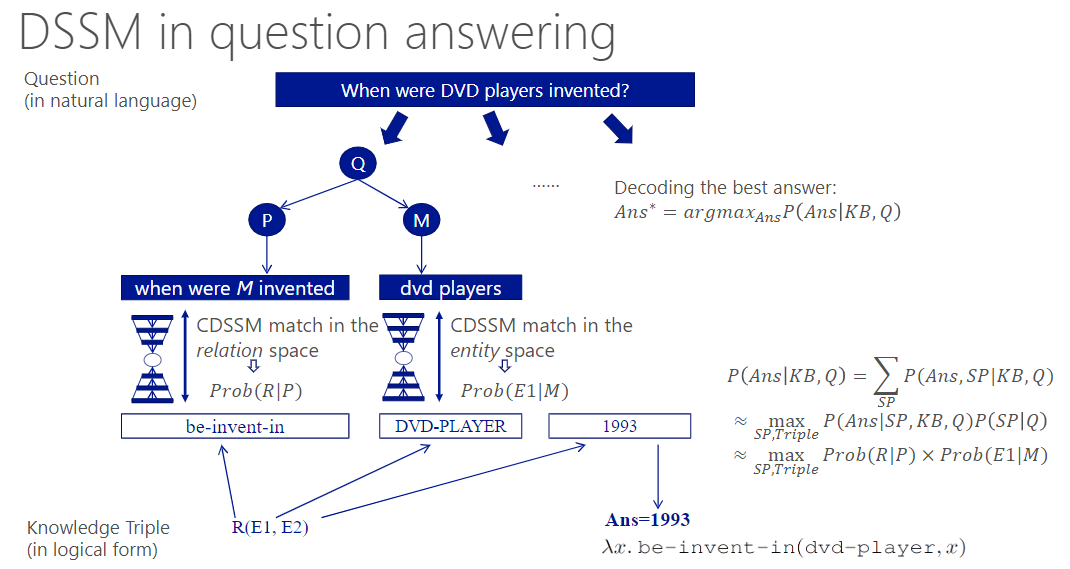
- Information Retrieval
- Contextual Entity Ranking
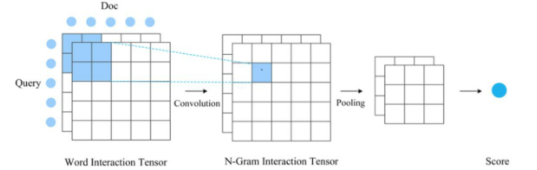
Interaction-based Matching
DRMM:Deep Relevance Matching Model
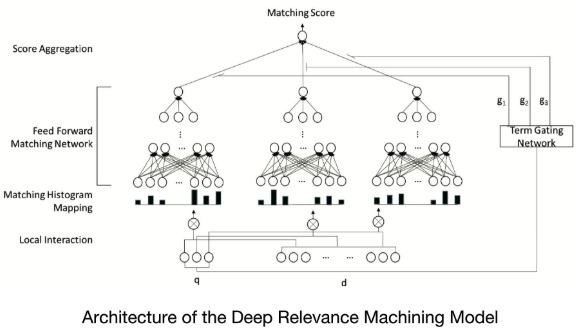
输入网络的特征是处理过的,把matching分数转化为histogram统计特征:
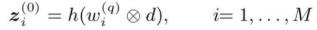
即q的term与d计算cosine similarity,不是乘法,然后统计多个不同区间的相似度的统计分布。
Term Gating Network
Term Gating Network用于计query中每个term的weight。
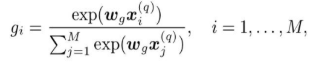
Hinge loss
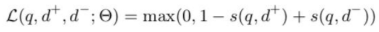
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!