More Effective Cpp
一、基础
条款 1:仔细区别 pointers和references
没有 null reference。一个 reference 必须总代表某个对象。
所以如果你有一个变量,其目的是用来指向(代表)另一个对象,但是也有可能它不指向(代表)任何对象,那么你应该使用 pointer,才可以将 pointer 设为 null。
Pointers 和 references 之间的另一个重要差异就是,pointers 可以被重新赋值,指向另一个对象,reference 却总是指向(代表)它最初获得的那个对象。
当你需要考虑“不指向任何对象”的可能性时,或是考虑“在不同时间指向不同对象”的能力时,你就应该采用 pointer。
当你确定“总是会代表某个对象”,而且“一旦代表了该对象就不能够再改变”,那么你应该选用 reference。
条款 2:最好使用 C++转型操作符
C++有 4个新的转型操作符(cast operators):static_cast,const_cast,dynamic_cast 和 reinterpret_cast。
static_cast 基本上拥有与 C 旧式转型相同的威力与意义,以及相同的限制。
const_cast 用来改变表达式中的常量性(constness)或变易性(volatileness)。
dynamic_cast 用来执行继承体系中“安全的向下转型或跨系转型动作”。也就是说你可以利用 dynamic_cast,将“指向 base class objects的 pointers或references” 转型为“指向 derived class objects 的 pointers 或references”。如果转型失败,会以一个 null指针(当转型对象是指针)或一个 exception(当转型对象是 reference)表现出来。
reinterpret_cast 转换结果几乎总是与编译平台息息相关。所以 reinterpret_casts 不具移植性。reinterpret_cast 的最常用用途是转换“函数指针”类型。
1 | |
条款 3:绝对不要以多态(polymorphically)方式处理数组
多态(polymorphism)和指针运算不能混用。数组对象几乎总是会涉及指针的算术运算,所以数组和多态不要混用。原因之一,若发生通过父类指针删除一个子类对象,其结果未定义。
条款 4:非必要不提供 default constructor
添加无意义的 default constructors,也会影响 class 的效率。
如果使用 member functions 测试字段是否真被初始化了,其调用者便必须为测试行为付出时间代价,并为测试代码付出空间代价。万一测试结果为否定,对应的处理程序又需要一些空间代价。
如果可以自定义 class constructors 确保对象的所有字段都会被正确地初始化,上述所有成本便都可以免除。default constructors 无法提供这种保证,那么最好避免让 default constructors 出现。
二、操作符
条款 5:对定制的“类型转换函数”保持警觉
两种函数允许编译器执行类型隐式转换:单自变量 constructors 和 隐式类型转换操作符。
所谓单自变量 constructors 是指能够以单一自变量成功调用的 constructors。如此的 constructor 可能声明拥有单一参数,也可能声明拥有多个参数,并且除了第一参数之外都有默认值。
所谓隐式类型转换操作符,是一个拥有奇怪名称的member function:关键词operator 之后加上一个类型名称。
1 | |
隐式转换可能带来不易察觉的问题或者错误。
C++引入关键词 explicit,就是为了解决隐式类型转换带来的问题。其用法十分直接易懂,只要将constructors声明为 explicit,编译器便不能因隐式类型转换的需要而调用它们。不过显式类型转换仍是允许的。
对于隐式类型转换操作符,如非必要,最好不要设计,而是设计一个功能对等的成员函数,以供显示调用。
1 | |
条款 6:自增(increment)、自减(decrement)操作符前缀形式与后缀形式的区别
重载函数是以其参数类型来区分彼此的,然而不论 increment 或 decrement 操作符的前置式或后置式,逻辑上都没有参数。为了做出区分,只好让后置式有一个 int 自变量,并且在它被调用时,编译器默默地为该 int 指定一个 0 值。
处理用户定制类型时,应该尽可能使用前置式 increment。
后置式 increment 和 decrement 操作符的实现应以其前置式兄弟为基础。方便维护,减少代码重复。
1 | |
条款 7:千万不要重载&&,||和,操作符
C++对于“真假值表达式”采用“骤死式”评估方式。意思是一旦该表达式的真假值确定,即使表达式中还有部分尚未检验,整个评估工作仍告结束。
“函数调用”语义和“骤死式”语义有两个重大的区别。
第一,当函数调用动作被执行,所有参数值都必须评估完成,所以当我们调用 operator&&和 operator||时,两个参数都已评估完成。换句话说没有什么骤死式语义。
第二,C++语言规范并未明确定义函数调用动作中各参数的评估顺序,所以没办法知道 expression1 和 expression2 哪个会先被评估。这与骤死式评估法形成一个明确的对比,后者总是由左向右评估其自变量。
C++同样也有一些规则用来定义逗号操作符面对内建类型的行为。表达式如果内含逗号,那么逗号左侧会先被评估,然后逗号的右侧再被评估;最后,整个逗号表达式的结果以逗号右侧的值为代表。
1 | |
其他不能重载的操作符还有:
1 | |
可以重载:
1 | |
条款 8:了解各种不同意义的new和 delete
new operator
1 | |
以上使用的 new 是 new operator。这个操作符是由语言内建的,就像sizeof 那样,不能被改变意义,总是做相同的事情。它的动作分为两方面。
第一,它分配足够的内存,用来放置某类型的对象。第二,它调用一个 constructor,为刚才分配的内存中的那个对象设定初值。
new operator 总是做这两件事,无论如何你不能够改变其行为。
operator new
你能够改变的是用来容纳对象的那块内存的分配行为。new operator 调用某个函数,执行必要的内存分配动作,你可以重写或重载那个函数,改变其行为。这个函数的名称叫做 operator new。
1 | |
返回值类型是 void*,因为这个函数返回一个未经处理(raw)的指针,未初始化的内存。就象 malloc 一样,operator new 的职责只是分配内存。它对构造函数一无所知。
当你的编译器遇见这样的语句:
1 | |
它生成的代码或多或少与下面的伪代码相似:
1 | |
placement new
如果被调用的 operator new 除了接受“一定得有的 size_t 自变量”之外,还接受了一个 void* 参数,指向一块内存,准备用来接受构造好的对象。这样的operator new 就是 placement new。
1 | |
总结
- 如果你希望将对象产生于 heap,请使用 new operator。它不但分配内存而且为该对象调用一个constructor。
- 如果你只是打算分配内存,请调用 operator new,那就没有任何 constructor 会被调用。
- 如果你打算在 heap objects 产生时自己决定内存分配方式,请写一个自己的 operator new,并使用 new operator,它将会自动调用你所写的 operator new。
- 如果你打算在已分配(并拥有指针)的内存中构造对象,请使用placement new。
三、异常
如果一个函数利用“设定状态变量”的方式或是利用“返回错误码”的方式发出一个异常信号,无法保证此函数的调用者会检查那个变量或检验那个错误码。于是程序的执行可能会一直继续下去,远离错误发生地点。
但是如果函数以抛出 exception 的方式发出异常信号,而该 exception 未被捕捉,程序的执行便会立刻中止。
如果你需要一个“绝对不会被忽略的”异常信号发射方法,而且发射后的 stack 处理过程又能够确保局部对象的 destructors 被调用,那么你需要 C++ exceptions。
条款 9:利用 destructors避免泄漏资源
解决办法就是,以一个“类似指针的对象”取代指针。如此一来,当这个类似指针的对象被销毁,我们可以令其 destructor 调用delete。“行为类似指针”的对象我们称为 smart pointers。
C++提供一个名为 auto_ptr 的智能指针。隐藏在 auto_ptr 背后的观念是,以一个对象存放“必须自动释放的资源”,并依赖该对象的destructor 释放。
只要坚持这个规则,把资源封装在对象内,通常便可以在 exceptions 出现时避免泄漏资源。
一个 auto_ptr 的实现示例:
1 | |
条款 10:在 constructors内阻止资源泄漏(resource leak)
C++只能析构被完全构造的对象(fully contructed objects), 只有一个对象的构造函数完全运行完毕,这个对象才被完全地构造。若因为异常导致构造函数没有执行完毕,那么也不会调用析构函数。
由于 C++不自动清理那些“构造期间抛出exceptions”的对象,所以你必须设计你的constructors,使它们能够自我清理。
通常这只需将所有可能的 exceptions 捕捉起来,执行某种清理工作,然后重新抛出exception,使它继续传播出去即可。
另外,member initializaion list 是在构造函数之前进行的,所以可以利用这一点,可以让某系操作在构造函数之前进行,并处理异常。比如:
1 | |
如果你以 auto_ptr 对象来取代 pointer class members,免除了“exceptions 出现时发生资源泄漏”的危机,不再需要在 destructors 内亲自动手释放资源。
1 | |
条款 11:禁止异常(exceptions)流出destructors之外
两种情况下 destructor 会被调用。
- 第一种情况是当对象在正常状态下被销毁,也就是当它离开了它的生存空间(scope)或是被明确地删除;
- 第二种情况是当对象被 exception 处理机制销毁,也就是exception 传播过程中的 stack-unwinding(栈展开)机制。
如果控制权基于 exception 的因素离开 destructor,而此时正有另一个 exception 处于作用状态,C++会调用 terminate 函数,将你的程序结束掉,甚至不等局部对象被销毁。
全力阻止 exceptions 传出 destructors之外:
- 第一,它可以避免 terminate 函数在 exception 传播过程的栈展开(stack-unwinding)机制中被调用;
- 第二,它可以协助确保 destructors 完成其应该完成的所有事情。
条款 12:了解“抛出一个exception”与“传递一个参数”或“调用一个虚函数”之间的差异
- 第一,exception objects 总是会被复制,如果以 by value 方式捕捉,它们甚至被复制两次。至于传递给函数参数的对象则不一定得复制。
- 第二,“被抛出成为 exceptions”的对象,相比于“被传递到函数去”的对象,其合法的类型转换更少。
- 第三,catch 子句以其“出现于源代码的顺序”被编译器检验比对,其中第一个匹配成功者便执行;而当我们以某对象调用一个虚函数,被选中执行的是那个“与对象类型最佳吻合”的函数,不论它是不是源代码所列的第一个。
条款 13:以 by reference方式捕捉 exceptions
如果 catch by reference,
- 可以避开对象删除问题;
- 可以避开 exception objects 的切割(slicing)问题;
- 可以保留捕捉标准 exceptions 的能力;
- 约束了 exception objects 需被复制的次数。
1 | |
条款 14:明智运用 exception specification
1 | |
结论是:
不应该将 templates 和 exception specifications 混合使用。
如果A 函数内调用了 B 函数,而 B 函数无 exception specifications,那么 A 函数本身也不要设定exception specifications。
处理“系统”可能抛出的exceptions。其中最常见的就是 bad_alloc,那是在内存分配失败时由operator new 和 operator new[]抛出的。
条款 15:了解异常处理(exception handling)的成本
- 为了能够在运行时期处理 exceptions,程序必须做大量记录工作。在每一个执行点,它们必须能够确认“如果发生 exception,哪些对象需要析构”,它们必须在每一个 try 语句块的进入点和离开点做记号,针对每个 try 语句块它们必须记录对应的 catch 子句及能够处理的 exceptions 类型。
- try 语句块,无论何时使用它,都得为此付出代价。不同的编译器实现 try 块的方法不同,所以编译器与编译器间的开销也不一样。粗略地估计,如果你使用 try 块,代码将膨胀5%-10%并且运行速度也同比例减慢。exception specification 通常也有与 try 块一样多的系统开销。
- 如果是因为异常而导致函数返回,函数的执行速度通常会比正常情况下慢 3 个数量级。当然,只有在抛出 exception 时才会承受这样的开销。
四、效率
条款 16:谨记 80-20 法则
80-20 法则说:一个程序 80%的资源用于 20%的代码身上。是的,80%的执行时间花在大约 20%的代码身上,80%的内存被大约 20%的代码使用,80%的磁盘访问动作由 20%的代码执行,80%的维护力气花在 20%的代码上面。
软件的整体性能几乎总是由代码的一小部分决定。
条款 17:考虑使用 lazy evaluation(缓式评估)
lazy evaluation(缓式评估)。延缓运算,直到那些运算结果刻不容缓地被迫切需要为止。如果其运算结果一直不被需要,运算也就一直不执行。
在你真正需要之前,不必着急为某物做一个副本。在某些应用领域,你常有可能永远不需要提供那样一个副本。
实现 lazy fetching 时,你必须面对一个问题:null 指针可能会在任何 member functions(包括const member functions)内被赋值,以指向真正的数据。然而当你企图在 const member functions 内修改 data members,编译器不会同意。除非将指针字段声明为 mutable。
lazy evaluation 在许多领域中都可能有用途:可避免非必要的对象复制,可区别 operator[] 的读取和写动作,可避免非必要的数据库读取动作,可避免非必要的数值计算动作。
条款 18:分期摊还预期的计算成本
另一种改善软件性能的方法是:令它超前进度地做“要求以外”的更多工作。该方法可称为超急评估(over-eager evaluation):在被要求之前就先把事情了。
Over-eager evaluation 背后的观念是,如果你预期程序常常会用到某个计算,你可以降低每次计算的平均成本,办法就是设计一份数据结构以便能够极有效率地处理需求,比如实时更新max、min等值,当需要使用时直接取值,而不用计算。
Caching 是“分期摊还预期计算之成本”的一种做法,Prefetching(预先取出)则是另一种做法。
这些思想很常见很有用,cache 自不用多说。对于 prefetching,比如,prefetch内存数据时,总是按页大小进行成块取数据,局部性原理告诉我们相邻的数据通常会更可能被需要。有时对象太大超过页大小,就会增加换页活动,缓存命中率下降,造成性能损失。
可通过over-eager evaluation,如 caching 和 prefetching 等做法分摊预期运算成本,这和 lazy evaluation 并不矛盾。
- 当你必须支持某些运算而其结果并不总是需要的时候,lazy evaluation 可以改善程序效率。
- 当你必须支持某些运算而其结果几乎总是被需要,或其结果常常被多次需要的时候,over-eager evaluation 可以改善程序效率。
条款 19:了解临时对象的来源
C++ 临时对象是不可见的,不会在你的源代码中出现。只要你产生一个 non-heap object 而没有为它命名,便诞生了一个临时对象。
这种匿名对象通常发生于两种情况:一是当隐式类型转换(implicit type conversions)时产生,以求函数调用能够成功;二是当函数返回对象的时候。
隐式类型转换
1 | |
看一下 countChar 的调用。第一个被传送的参数是字符数组,但是对应函数的正被绑定 的参数的类型是 const string&。仅当消除类型不匹配后,才能成功进行这个调用。
编译器会建立一个 string 类型的临时对象。通过以 buffer 做为参数调用 string 的构造函数来初始化这个临时对象。countChar 的参数 str 被绑定在这个临时的 string 对象上。当 countChar 返回时,临时对象自动释放。
仅当通过传值(by value)方式传递对象 或 传递常量引用(reference-to-const)参数时,才会发生这些类型转换。当传递一个非常量引用(reference-to-non-const)参数对象,就不会发生。比如:
1 | |
这里假如产生一个临时对象,uppercasify会对string&所指的临时对象进行修改,而不是对subtleBookPlug字符数组进行修改,显然和uppercasify函数设计的本意是不符合的,这显然是一个错误,却不易察觉。
所以,C++语言禁止为非常量引用(reference-to-non-const) 产生临时对象。以上情况并不会发生。
函数返回对象
1 | |
这个函数的返回值是临时的,因为它没有被命名,它只是函数的返回值。你必须为每次调用operator+ 构造和释放这个对象而付出代价。有时可以通过 返回值优化(return value optimization)可以将这个临时对象消灭掉。
总结
- 任何时候只要你看到一个 reference-to-const 参数,就极可能会有一个临时对象被产生出来绑定至该参数上。
- 任何时候只要你看到函数返回一个对象,就会产生临时对象(并于稍后销毁)。
条款 20:协助完成“返回值优化(RVO)”
可以用某种特殊写法来撰写函数,使它在返回对象时,能够让编译器消除临时对象的成本。
方法是:返回 constructor arguments 以取代对象。
1 | |
虽然仍旧必须为在函数内临时对象的构造和释放而付出代价。但是此时,编译器可以进行优化了。
1 | |
编译器会消除在 operator* 内的临时变量和 operator* 返回的临时变量。直接在 c 的内存里构造 return 表达式定义的对象。调用 operator* 的临时对象的开销就是零:没有建立临时对象。
利用函数的 return 点消除一个局部临时对象,这种方法很常见,被称之为 return value optimization。
条款 21:利用重载技术(overload)避免隐式类型转换(implicit type conversion)
在重载操作符时,每个重载函数的参数必须至少一个是“用户定制类型”的自变量。如果不是,就会改变C++内部预先定义的操作符意义(参数类型全是内置类型),而那当然会导致天下大乱。
1 | |
增加一堆重载函数不一定是好事,除非能保证这样对程序效率有很大的改善。
条款 22:考虑以操作符复合形式(op=)取代其独身形式(op)
一个好方法就是以复合形式(例如,operator+=)为基础实现独身形式(例如,operator+)。
3 个与效率有关的情况值得注意。
第一,一般而言,复合操作符比其对应的独身版本效率高。因为独身版本通常必须返回一个新对象,而我们必须因此负担一个临时对象的构造和析构成本(见条款 19和 20)。复合版本则是直接将结果写入其左端自变量,所以不需要产生一个临时对象来放置返回值。
第二,如果同时提供某个操作符的复合形式和独身形式,那就是在允许你的客户在效率与便利性之间自行取舍。
第三、匿名对象总是比命名对象更容易被消除,所以当你面临命名对象或临时对象的抉择时,最好选择临时对象。匿名对象有可能降低成本(尤其在搭配旧式编译器时)。
条款 23:考虑使用其他程序库
不同的程序库即使提供相似的功能,也往往有不同的性能取舍策略,所以一旦你找出程序的瓶颈,你应该思考是否有可能使用其他程序库,来移除了那些瓶颈。
比如,iostream 相比于 stdio,iostream 有类型安全的特性,可扩展性好;而 stdio 更节省程序空间、速度更快。
条款 24:了解 virtual functions、multiple inheritance、virtual base class、runtime type identification的成本
当一个虚函数被调用,执行的代码必须对应于“调用者(对象)的动态类型”。
大部分编译器使用 virtual tables(vtbls)和 virtual table pointers(vptrs)实现动态类型。
virtual tables(vtbls)
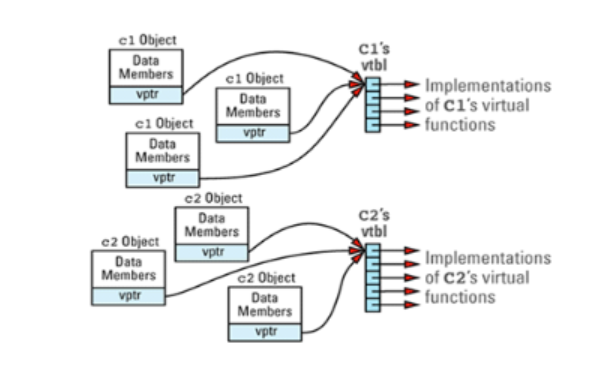
vtbl 通常是一个由“函数指针”数组。某些编译器会以链表(linked list)取代数组,但其基本策略相同。程序中的每一个class ,只要声明(或继承)虚函数者,都有自己的一个 vtbl,而其中的条目(entries)就是该 class 的各个虚函数具体实现的指针。
虚函数的第一个成本:你必须为每个拥有虚函数的 class 耗费一个 vtbl 空间,其大小视虚函数的个数(包括继承而来的)而定。
1 | |
C1 的 virtual table 数组看起来如下图所示:

注意非虚函数 f4 不在表中,而且 C1 的构造函数也不在。
1 | |
它的 virtual table 中包括指向没有被 C2 重定义的 C1 虚函数的指针:

virtual table pointers(vptrs)
Virtual tables 只是虚函数实现机构的一半而已。如果只有它,不能成气候。还需要某种方法可以指示出每个对象对应于哪一个 vtbl,vtbl 才真的有用。而这正是virtual table pointer(vptr)的任务。
凡声明有虚函数的 class,其对象都含有一个隐藏的 data member,vptr,用来指向该class 的 vtbl。这个隐藏的 data member 被编译器加入对象内某个只有编译器才知道的位置。
虚函数的第二个成本:你必须在每一个拥有虚函数的对象内付出“一个额外指针”的代价。
上述C1、C2对象关系可以表示为:
虚函数的调用
编译器必须产生代码,完成以下动作:
根据对象的 vptr 找出其 vtbl。编译器成本只有一个偏移调整(offset adjustment)就能获得 vptr,和一个指针间接动作,以便获得 vtbl。
找出被调用函数在 vtbl 内的对应指针。编译器为每个虚函数指定了一个独一无二的表格索引。本步骤的成本只是一个偏移(offset),在 vtbl 数组中索引。
调用步骤 2 所得指针所指向的函数。
RTTI
运行时期类型辨识(runtime typeidentification,RTTI)的成本。RTTI 让我们得以在运行时期获得 objects 和 class 的相关信息。它们被存放在类型为 type_info 的对象内。你可以利用 typeid 操作符取得某个class 相应的 type_info 对象。
C++规范书上说,只有当某种类型拥有至少一个虚函数,才保证我们能够检验该类型对象的动态类型。RTTI 的设计理念是:根据 class 的 vtbl 来实现。
RTTI 耗费的空间是在每个类的 vtbl 中的占用的额外单元再加上存储 type_info 对象的空间。就像在多数程序里 virtual table 所占的内存空间并不值得注意一样,你也不太可能因为 type_info 对象大小而遇到问题。
RTTI的代价:type_info 占用的空间。
假如 type_info 才是完整的 vtbl 内存布局:

多继承
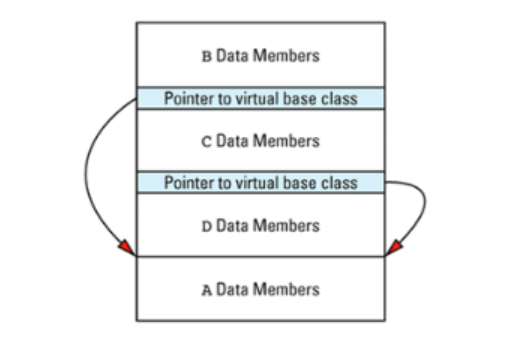
多继承经常导致对虚基类的需求。
没有虚基类,如果一个派生类有一个以上从基类的继承路径,基类的数据成员被复制到每一个继承类对象里,继承类与基类间的每条路径都有一个拷贝。
把基类定义为虚基类则可以消除这种复制。 虚基类的实现经常使用指向虚基类的指针做为避免复制的手段,一个或者更多的指针被存储在对象里。
另一种代价:虚基类的实现经常使用指向虚基类的指针。
比如:
1 | |
如果 A 中没有虚函数,D对象内存布局为:
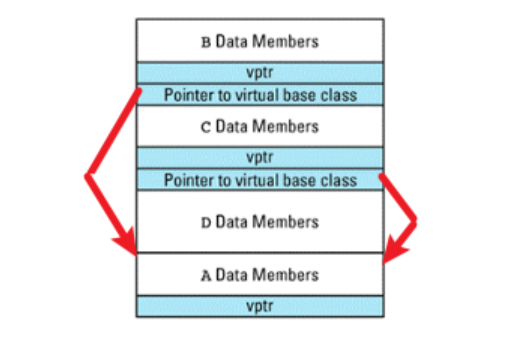
如果 A 中有虚函数,D对象内存布局为:
五、技术
条款 25:将 constructor 和 non-member functions 虚化
此处所谓 virtual 不是虚函数的 virtual,而是类似、形似的意思。
模仿 constructor 的行为,但能够视其获得的输入,产生不同类型的对象,所以称之为 virtual constructor。Virtual constructor 在许多情况下有用,其中之一就是从磁盘(或网络或磁带等)读取对象信息。
例如,假设你编写一个程序,用来进行新闻报道的工作,每一条新闻报道都由文字或图片组成。
1 | |
readComponent 所做的工作。它根据所读取的数据建立了一个新对象,或是 TextBlock 或是 Graphic。
virtual copy constructor 是一种特别的 virtual constructor 。Virtual copy constructor 会返回一个指针,指向其调用者(某对象)的一个新副本。基于这种行为,virtual copy constructors 通常以 copySelf 或cloneSelf 命名,或者像下面一样命名为 clone。
1 | |
non-member functions 也可以进行虚化。编写一个虚函数来完成工作,然后再写一个非虚函数,它什么也不做只是调用这个虚函数。
1 | |
条款 26:限制某个 class 所能产生的对象数量
每产生一个对象,会有一个 constructor被调用。
使用 static 控制对象数量的产生,是一种方法。首先要知道:
- class 拥有一个static成员对象时,即使从未使用到,也会被构造,且其初始化时机,并不明确;
- function 中有一个static对象,此对象在函数第一次被调用时才产生,且其初始化时机是明确的。
“阻止某个 class 产出对象” 的最简单方法就是将其 constructor 声明为 private。
一个限制对象数量的 class 设计,一个 Printer 对象实现:
1 | |
条款 27:要求(或禁止)对象产生于 heap 之中
有时你想这样管理某些对象,要让某种类型的对象能够自我销毁,也就是能够“delete this”。很明显这种管理方式需要此类型对象被分配在堆中。而其它一些时候你想获得一种 保障:“不在堆中分配对象,从而保证某种类型的类不会发生内存泄漏。”
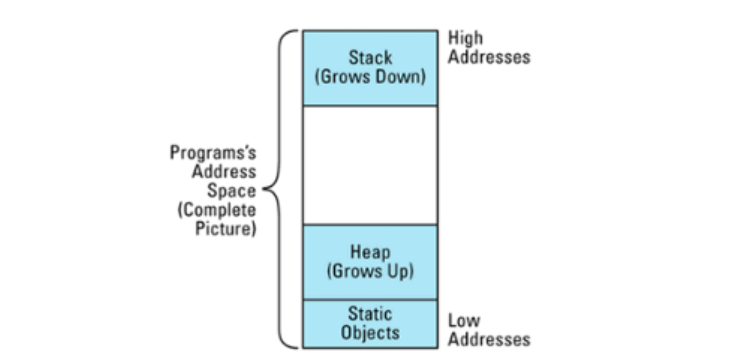
判断对象是否在堆上,可以使用地址比较法,栈段地址从高到低生长,堆段地址从低到高生长。以下方法可以实现:
1 | |
但是,static 对象的地址在堆段地址下方,以上方法并不能确定是否是静态对象。
另一种方式,是设计 abstract mixin base class 来实现判断堆对象的功能。
所谓 abstract base class 是一个不能够被实例化的 base class。也就是说它至少有一个纯虚函数。所谓 mixin(“mix in”)class 则提供一组定义完好的能力,能够与其 derived class 所可能提供的其他任何能力兼容。如此的 class 几乎总是abstract。于是可以设计 abstract mixin base class,用来为 derived class 提供“判断某指针是否以 oeprator new 分配出来”的能力。
1 | |
如果是在堆上分配内存,就会调用 operator new,可以通过 isOnHeap 判断是否在堆上。只要继承自 HeapTracked 类的子类,就都有了 isOnHeap 的功能。
如果要禁止对象在堆上分配内存,将 operator new 设计为 private 是一种简单的方式。
条款 28:Smart Pointers(智能指针)
当你以 smart pointers 取代 C++的内建指针(亦即 dumb pointers),你将获得以下各种指针行为的控制权:
- 构造和析构(Construction and Destruction)。你可以决定smart pointer 被产生以及被销毁时发生什么事。通常我们会给 smart pointers 一个默认值 nullptr,以避免“指针未获初始化”的头痛问题。某些 smart pointers 可以删除它们所指的对象,比如当指向该对象的最后一个 smart pointer 被销毁时。这是消除资源泄漏问题的一大进步。
- 复制和赋值(Copying and Assignment)。当一个 smart pointer 被复制或涉及赋值动作时,你可以控制发生什么事。某些 smart pointer 会希望在此时刻自动为其所指之物进行复制或赋值动作,也就是执行深复制(deep copy)。另一些 smart pointer 则可能只希望指针本身被复制或赋值就好。还有一些则根本不允许复制和赋值。不论你希望什么样的行为,smart pointer 都可以让你如愿。
- 解引(Dereferencing)。当 client 解引(取用)smart pointer 所指之物时,你有权决定发生什么事情。例如你可以利用 smart pointer 协助实现出条款 17 所说的 lazy fetching 策略。
Smart pointer的构造行为通常明确易解:确定一个目标物(通常是利用smart pointer 的 constructor 参数),然后让 smart pointer 内部的 dumb pointer 指向它。如果尚未决定目标物,就将内部指针设为 nullptr,或是发出一个错误消息(可能是抛出 exception)。
Smart pointer 不要提供对 dumb pointer 的隐式转换操作符,除非不得已。
在涉及继承相关的类型转换时,smart pointer 是做不到 dumb pointer 所能做的一切的。此时,别使用 smart pointer ,而是 dumb pointer 。
条款 29:Reference counting(引用计数)
通过 reference counting 可以建构出垃圾回收机制(garbage collection)的一个简单形式。Reference counting 的另一个发展动机则只是为了实现一种常识。如果许多对象有相同的值,将那个值存储多次是件愚蠢的事。最好是让所有等值对象共享一份实值就好。
copy-on-write
“和其他对象共享一份实值,直到我们必须对自己所拥有的那一份实值进行写动作,才进行复制”,这就是:copy-on-write(写时才复制)。
特别是在操作系统领域,各进程(processes)之间往往允许共享某些内存分页(memory pages),直到它们打算修改属于自己的那一分页,才进行复制。这是提升效率的一般化做法(也就是 lazy evaluation,条款 17)。
实现
首先产生一个 base class RCObject,作为“reference-counted 对象”之用。RCObject 组成为:
- “引用计数器”
- 增减计数值的函数
- 一个函数,用来将不再被使用(也就是其引用次数为 0)的对象值销毁掉。
- 一个成员,用来追踪资源是否“可共享”,并提供查询其值、将该成员设为 false 等相关函数。在默认情况下为可共享状态。一旦某个对象被贴上“不可共享”标签,就没有办法再恢复其“可共享”的身份了。
其他
简单地说,以下是使用 reference counting 改善效率的最适当时机:
- 相对多数的对象共享相对少量的实值。这种共享行为通常是通过assignment operators 和 copy constructors。
- 对象实值的产生或销毁成本很高,或是资源占用内存很多。若实值(资源)可被多个对象共享,reference counting 能带来较高收益。
RCObject 的设计目的是用来作为有引用计数能力之“实值对象”的基类。
那些“实值对象”即实际的资源,设计 RCPtr smart pointer 进行管理(RAII保证)。
RCObject、RCPtr 不应该被外界看到,应为私有成员,以限制其用途。
条款 30:Proxy class(代理类)
凡“用来代表(象征)其他对象”的对象,常被称为 proxy objects(替身对象),而用以表现 proxy objects 者,我们称为 proxy class。
当 class 的身份从“与真实对象”移转到“与替身对象(proxies)”,往往会造成 class 语义的改变,因为 proxy objects 所展现的行为常常和真正对象的行为有些隐微差异。
在很多情况下,proxy 对象可以完美替代实际对象。当它们可以工作时,意味着两者间的差异并不影响什么。
多维数组
优化二维数组的使用形式:
1 | |
左值/右值的区分
operator[]可以在两种不同的情况下调用:读一个字符或写一个字符。读是个 右值操作;写是个左值操作。(这个名词来自于编译器,左值出现在赋值运算的左边,右值 出现在赋值运算的右边。)
通常,将一个对象做左值使用意味着它可能被修改,做右值用意 味着它不能够被修改。
虽然或许不可能知道 operator[] 是在左值或右值情境下被调用,我们还是可以区分读和写。只要将处理动作推迟,直至知道 operator[] 的返回结果将如何被使用为止。(lazy evaluation)
Proxy class 可是实现此 lazy evaluation。可以修改 operator[],令它返回字符串中字符的 proxy,而不返回字符本身。然后等待,看看这个 proxy 如何被运用。如果它被读,就将 operator[] 的调用动作视为一个读取动作。如果它被写,就将 operator[] 的调用视为一个写动作。
1 | |
1 | |
条款 31:让函数根据一个以上的对象类型来决定如何虚化
假设你必须以 C++完成任务,也就是你必须自行想办法完成上述需求(常被称为 double-dispatching)。此名称来自面向对象程序设计社区,在那个领域里,人们把一个“虚函数调用动作”称为一个“message dispatch”(消息分派)。
因此某个函数调用如果根据两个参数而虚化(两个参数发生动态类型绑定),自然而然地就被称为“double dispatch”。更广泛的情况(函数根据多个参数而虚化)则被称为 multiple dispatch。
- 虚函数+ RTTI(运行时期类型辨识),根据不同的 typeid() 结果,进行条件判断实现不同处理逻辑。
- 只使用虚函数,在两个类型中,分别按照 single dispatch 的方式处理,然后组合使用。比RTTI方法更安全。
- 自行仿真虚函数表格(Virtual Function Tables),略
六、杂项讨论
条款 32:在未来时态下发展程序
所谓在未来时态下设计程序,就是接受“事情总会改变”的事实,并准备应对方法。
也许程序库会加入新的函数,导致新的重载(overloading)发生,于是导致潜在的歧义。
也许继承体系会加入新的 class,致使今天的 derived class 成为明天的 base class。
也许新的应用软件会出现,函数会在新的环境下被调用,而我们必须考虑那种情况下仍能正确执行任务。
程序的维护者通常都不是当初的开发者,所以设计和实现时应该注意到如何帮助其他人理解、修改、强化你的程序。
未来式思维只不过是加上一些额外的考虑:
提供完整的 class,即使某些部分目前用不到。当新的需求进来,你不太需要回头去修改那些 class。
设计你的接口,让这些 class 轻易地被正确运用,难以被错误运用。例如,面对那些“copying 和 assignment 并不合理”的 class,请禁止那些动作的发生。
尽量使你的代码一般化(泛化),除非有不良的巨大后果。举个例子,如果你正在写一个算法,用于树状结构(tree)的来回遍历,请考虑将它一般化,以便能够处理任何种类的 directed acyclic(非环状的)graph。
使用设计模式封装变化。
条款 33:将非尾端类(non~leaf class)设计为抽象类(abstract class)
将函数声明为纯虚函数,并非暗示它没有实现,而是意味着:
- 目前这个 class 是抽象的。
- 任何继承此 class 的具体类,都必须将该纯虚函数重新声明为一个正常的虚函数(也就是说,不可以再令它“=0”)。
的确,大部分纯虚函数并没有实现码,但是 pure virtual destructors 是个例外。它们必须被实现出来,因为只要有一个 derived classdestructor 被调用,它们便会被调用。此外,它们通常执行一些有用的工作,如释放资源或记录运转消息等等。纯虚函数的实现或许并不常见,但对 pure virtual destructors 而言,实现不仅是平常的事,甚至是必要的事。
一般性的法则是:继承体系中的 non-leaf(非尾端)类应该是抽象类。
条款 34:如何在同一个程序中结合 C++和 C
有 4 件事情你需要考虑:name mangling(名称重整)、statics(静态对象)初始化、动态内存分配、数据结构的兼容性。
- Name Mangling(名称重整)
Name mangling 是一种程序。通过它,你的 C++编译器为程序内的每一个函数编出独一无二的名称。在 C 语言中,此程序并无必要,因为你无法将函数名称重载(overload);但是几乎所有的 C++程序都有一些函数拥有相同的名称。
- Statics 的初始化
许多代码会在 main之前和之后执行起来。更明确地说,static class 对象、全局对象、namespace 内的对象以及文件范围(file scope)内的对象,其 constructors 总是在 main 之前就获得执行。这个过程称为static initialization。同样道理,通过 static initialization 产生出来的对象,其destructors 必须在 static destruction 过程中被调用。static destruction 发生在 main 结束之后。
- 动态内存分配
动态内存分配的一般规则很简单:程序的 C++部分使用 new 和delete,程序的 C 部分则使用 malloc(及其变种)和free。只要内存是以 new 分配而得,就以 delete 删除。只要内存是以 malloc 分配而得,就以 free 释放。
- 数据结构的兼容性
从数据结构的观点来看,我们可以说:在 C 和 C++之间对数据结构做双向交流,应该是安全的——前提是那些结构的定义式在 C 和C++ 中都可编译。为 C++ struct 加上非虚函数,可能不影响其兼容性;其他任何改变则几乎都会影响。
- 准则
如果你打算在同一个程序中混用 C++和 C,请记住以下几个简单守则:
- 确定你的 C++和 C 编译器产出兼容的目标文件(object files)。
- 将双方都使用的函数声明为 extern "C"。
- 如果可能,尽量在 C++ 中撰写 main。
- 总是以 delete 删除 new返回的内存;总是以 free 释放 malloc 返回的内存。
- 将两个语言间的“数据结构传递”限制于 C 所能了解的形式。
条款 35:让自己习惯于标准 C++语言
C++最重要的几项改变如下所示(时间在C++11之前)。
- 增加了一些新的语言特性:RTTI、namespaces、bool、关键词mutable 和explicit、enums 作为重载函数之自变量所引发的类型晋升转换,以及“在class 定义区内直接为整数型(integral)conststatic class members 设定初值”的能力。
- 扩充了 Templates 的弹性:允许 member templates 存在等。
- 强化了异常处理机制(Exception handling):编译期间更严密地检验 exception specifications等。
- 修改了内存分配例程:加入 operator new[] 和 operator delete[],内存未能分配成功时由 operator new/new[] 抛出一个exception,在内存分配失败时返回 0。
- 增加了新的转型形式:static_cast,dynamic_cast,const_cast 和reinterpret_cast。
- 语言规则更为优雅精练:重新定义虚函数时,其返回类型不再一定得与原定义完全吻合。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!