Large scale GAN training for high fidelity natural image synthesis
问题
GAN生成图像的过程是一个敏感的过程。虽然相比于VAE,其优化目标从Elmo最优损失函数的一个下界,变为直接优化生成结果和目标之间差异损失本身,直觉上是一种更好的方法,但是由于动态地交叉训练生成器与判别器,导致对网络设计、训练方法、参数设置等非常敏感。
尽管有研究表明在经验和理论上,获得了在多种设置中可以实现稳定训练的结论。但是GAN生成网络的效果始终有点差强人意。
当前在Image Net建模上的最佳结果仅达到了52.5的IS,而真实数据有233的IS。
Is( inception score):用来衡量GAN网络的两个指标: 生成图片的质量和多样性
- entropy = -sum(p_i * log(p_i))
The conditional probability captures our interest in image quality.
- KL (C || M) : KL divergence = p(y|x) * (log(p(y|x)) – log(p(y)))
The average of the KL divergence for all generated images. C for conditional and M for marginal distributions.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# calculate inception score in numpy
from numpy import asarray
from numpy import expand_dims
from numpy import log
from numpy import mean
from numpy import exp
# calculate the inception score for p(y|x)
def calculate_inception_score(p_yx, eps=1E-16):
# calculate p(y)
p_y = expand_dims(p_yx.mean(axis=0), 0)
# kl divergence for each image
kl_d = p_yx * (log(p_yx + eps) - log(p_y + eps))
# sum over classes
sum_kl_d = kl_d.sum(axis=1)
# average over images
avg_kl_d = mean(sum_kl_d)
# undo the logs
is_score = exp(avg_kl_d)
return is_score但是有一个缺陷,概率计算是建立在Inception数据集限制的1000种类别中的,不在其中的类别则无法评估,同时要达到较好的效果,计算score时,不同类别中的数据分布最好是比较均匀的。
《Large scale GAN training for high fidelity natural image synthesis》的研究正是探索生成效果的一项成果,作者成功地将GAN生成图像和真实图像之间的保真度和多样性gap大幅降低。
方法
高分辨率能够带来更为真实的生成图像,在这样的思想的指导下,本论文结合了GAN的各种新技术,并且分析了训练难的原因,最后提出自己的模型。
本文展示了GAN可以从训练规模中显著获益,并且能在参数数量很大和八倍Batch size于之前最佳结果,的条件下,仍然能以2倍到4倍的速度进行训练。
作者引入了两种简单的生成架构变化,提高了可扩展性,并修改了正则化方案以提升conditioning,通过实验说明了这样可以提升性能。
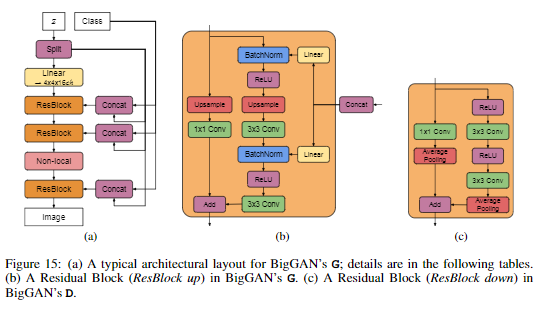
这篇论文没有提出新的模型,只是将原有的GAN的模型:
- 用8倍原有的batch size大小
- 将隐层的变量数量扩充到原有模型的4倍
训练获得了很好的图片生成的效果。与此同时,在扩充了变量数量和 batch size大小后,模型出现了不稳定的现象。
文章中对出现的不稳定现象,采用现有的比较有效的稳定训练GAN的方法,但是文中发现这样确实会稳定GAN的训练,但是同时会栖牲生成图片的质量。
实验结果
- 研究表明按8的倍数增加批大小可以将当前最佳的IS提高46%。
研究者假设这是由于每个批量覆盖了更多的模式,为生成器和鉴别器都提供了更好的梯度信息。
这种扩扆带来的值得注意的副作用是,模型以更少的迭代次数达到了更好的性能,但变得不稳定并且遭遇了完全的训练崩溃。
因此在实验中,研究者在崩溃刚好发生之后立刻停止训练,并从之前保存的检查点进行结果报告。
- 增加了每个层50%的宽度(通道数量),进一步的21%的IS提升。
生成器和鉴别器中的参数数量几乎翻倍。研究者假设这是由于模型相对于数据集复杂度的容量的增加。将深度翻倍,在ImageNet Based模型上,反而会降低性能。
- 其他技巧
截断技巧
生成器的随机噪声输入一般使用正态分布或者均匀分布的随机数。
本文采用了截断技术,对正态分布的随机数进行截断处理,实验发现这种方法的结果最好。
对此的直观解释是,如果网络的随机噪声输入的随机数变动范围越大,生成的样本在标准模板上的变动就越大,因此样本的多样性就越强,但真实性可能会降低。
首先用截断态分布N(0,1)随机数产生噪声向量Z,具体做法是如果随机数超出一定范围,则重新采样,使得其落在这个区间里。
这种做法称为截断技巧:向量Z的模超过某一指定阈值的随机数进行重釆样,这样可以提高单个样本的质量,但代价是降低了样本的多样性。
实验后分析
- 生成器的不稳定性
本文着重对小规模时稳定,大规模时不稳定的问题进行分析。
实验中发现,权重矩阵的前3个奇异值σ0,σ1,σ2蘊含的信息最丰富。
在训练中,G的大部分层的谱范数都是正常的,但有一些是病态的,这些谱范数随着训练的进行不断的增长,最后爆炸,导致训练坍塌。
结论
- 本文证明了将GAN用于多类自然图像生成任务时,加大模型的规模可以显著的提高生成的图像的质量,对生成的样本的真实性和多样性都是如此。
- 通过使用一些技巧,本文提出的方法的性能较之前的方法有了大度的提高。
- 另外,还分析了大规模GAN在训练时的机制,用它们的权重矩阵的奇异值来刻画它们的稳定性。
- 讨论了稳定性和性能即生成的图像的质量之间的相互作用和影响
参考链接:
百度论文复现课程:https://aistudio.baidu.com/aistudio/education/group/info/1340
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!