神经网络normalization
深度学习中的Normalization,BN/LN/WN
为什么需要 Normalization
- independent and identically distributed,简称为 i.i.d
并非所有机器学习模型的必然要求(比如 Naive Bayes 模型就建立在特征彼此独立的基础之上,而Logistic Regression 和 神经网络 则在非独立的特征数据上依然可以训练出很好的模型),但独立同分布的数据可以简化常规机器学习模型的训练、提升机器学习模型的预测能力,已经是一个共识。
- 白化(whitening)
数据预处理步骤。
(1)去除特征之间的相关性 —> 独立;
(2)使得所有特征具有相同的均值和方差 —> 同分布。
- 深度学习中的 Internal Covariate Shift
参数更新使每一层的数据分布发生变化,向前叠加,高层的受到数据变化的影响,需要不断重新适应底层的数据变化。
Internal Covariate Shift,简称 ICS.
ML经典假设是“源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”
covariate shift是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同
1. 给定输入,拟合label,条件概率一致的
- 层间计算导致,各层分布发生改变,边缘概率是不同的
ICS的问题
- 上层参数需要不断适应新的输入数据分布,降低学习速度
- 下层输入的变化可能趋向于变大或者变小,导致上层落入饱和区,使得学习过早停止 (想想sigmoid)
- 每层的更新都会影响到其它层,因此每层的参数更新策略需要尽可能的谨慎
Normalization 的通用框架与基本思想
标准的白化操作代价高昂,特别是我们还希望白化操作是可微的(每一点上必存在非垂直切线),保证白化操作可以通过反向传播来更新梯度。
Normalization 方法退而求其次,进行了简化的白化操作。
- Normalization
先对其做平移和伸缩变换, 将
的分布规范化成在固定区间范围的标准分布。
是平移参数(shift parameter),
是缩放参数(scale parameter)
是再平移参数(re-shift parameter),
是再缩放参数(re-scale parameter)
最终得到的数据符合均值为
的分布
变换为均值为
- 再平移调整的意义
- 不会过分改变每一层计算结果
- 第一步的规范化会将几乎所有数据映射到激活函数的非饱和区(线性区),仅利用到了线性变化能力,从而降低了神经网络的表达能力。而进行再变换,则可以将数据从线性区变换到非线性区,恢复模型的表达能力(想想激活函数)
主流 Normalization 方法梳理
- Batch Normalization —— 纵向规范化:整个batch的不同维度(channel)
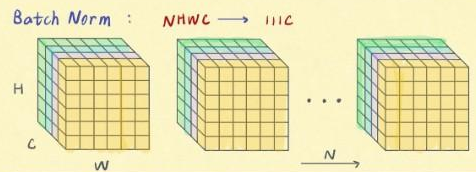
其中 
然后,用一个 mini-batch 的一阶统计量和二阶统计量,规范每一个输入维度
KEYPOINT:mini-batch数据决定,x每个维度的分布,上图可理解为RGB三个通道。
要求:每个 mini-batch 比较大,数据分布比较接近,充分的 shuffle
不适用:动态的网络结构 和 RNN 网络 (最后才知道mini-batch的\(\mu\))。Batch Normalization基于一个mini batch的数据计算均值和方差,而不是基于整个Training set来做,相当于进行梯度计算式引入噪声。因此,Batch Normalization不适用于对噪声敏感的强化学习、生成模型(Generative model:GAN,VAE)使用。
1 | |
ref Synchronized-BatchNorm-PyTorch,多GPU分布式同步各个节点的数据mean和var
- Layer Normalization —— 横向规范化:单个输入 https://arxiv.org/abs/1607.06450
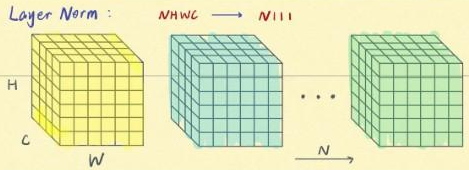
考虑一层所有维度的输入,计算该层的平均输入值和输入方差,然后用同一个规范化操作来转换各个维度的输入
KEYPOINT:LN 针对单个训练样本进行,用于 小mini-batch场景、动态网络场景和 RNN,特别是自然语言处理领域。此外,LN 不需要保存 mini-batch 的均值和方差,节省了额外的存储空间
NOTE:如果不同输入特征不属于相似的类别(比如颜色和大小),那么 LN 的处理可能会降低模型的表达能力。
1 | |
- Weight Normalization —— 参数规范化 https://arxiv.org/abs/1602.07868
将以下方程
理解为:
BN 和 LN 均将规范化应用于输入的特征数据
WN将规范化应用于线性变换的权重
用神经元的权重的欧氏范数对输入数据进行 scale。
KEYPOINT:WN 的规范化不直接使用输入数据的统计量,因此避免了 BN 过于依赖 mini-batch 的不足,以及 LN 每层唯一转换器的限制,同时也可以用于动态网络结构
Weight Normalization对通过标量g和向量v对权重W进行重写,重写向量v是固定的,因此,基于Weight Normalization的Normalization比Batch Normalization引入更少的噪声。
1 | |
- Cosine Normalization —— 余弦规范化
其中
超简单的变化,直接在wx的上scale,并且不需要再次缩放。
将 点积》》》变为余弦相似度
- Instance Norm
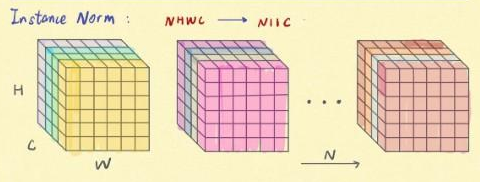
InstanceNorm等价于当Group Norm的num_groups等于num_channel.
- Group Norm https://arxiv.org/abs/1803.08494
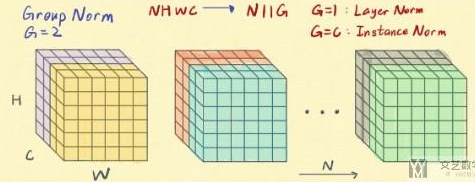
当Group Norm中group的数量是1的时候, 是与LayerNorm是等价的
1 | |
Normalization 为什么会有效?
- 权重伸缩不变性(weight scale invariance)
其中
由于
因此,权重的伸缩变化不会影响反向梯度的 Jacobian 矩阵,因此也就对反向传播没有影响,避免了反向传播时因为权重过大或过小导致的梯度消失或梯度爆炸问题,从而加速了神经网络的训练
- 参数正则
由于
因此,下层的权重值越大,\(\lambda\)越大,那么其梯度就越小。这样,参数的变化就越稳定,相当于实现了参数正则化的效果,避免参数的大幅震荡,提高网络的泛化性能。
- 数据伸缩不变性(data scale invariance)
当数据
其中
数据伸缩不变性仅对 BN、LN 和 CN 成立。WN 不具有这一性质。很明显。
- 数据伸缩不变性可以有效地减少梯度弥散,简化对学习率的选择
某一层神经元
每一层神经元的输出依赖于底下各层的计算结果。再次回忆activition function的图像
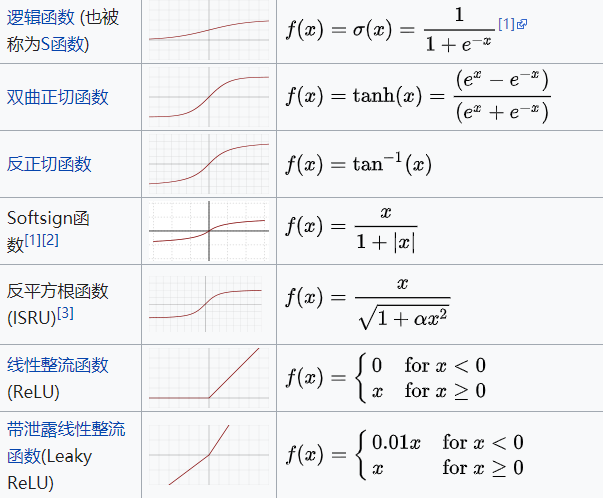
如果没有正则化,当下层输入发生伸缩变化时,经过层层传递,可能会导致数据发生剧烈的膨胀或者弥散,从而也导致了反向计算时的梯度爆炸或梯度弥散。
数据的伸缩变化也不会影响到对该层的权重参数更新,使得训练过程更加鲁棒,简化了对学习率的选择。
参考链接:https://zhuanlan.zhihu.com/p/33173246
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!