CUDA 笔记
异构计算
CPU和GPU是两个独立的处理器,它们通过单个计算节点中的PCI-Express总线相连。
GPU不是一个独立运行的平台而是CPU的协处理器。因此,GPU必须通过PCIe总线与基于CPU的主机相连进行操作。
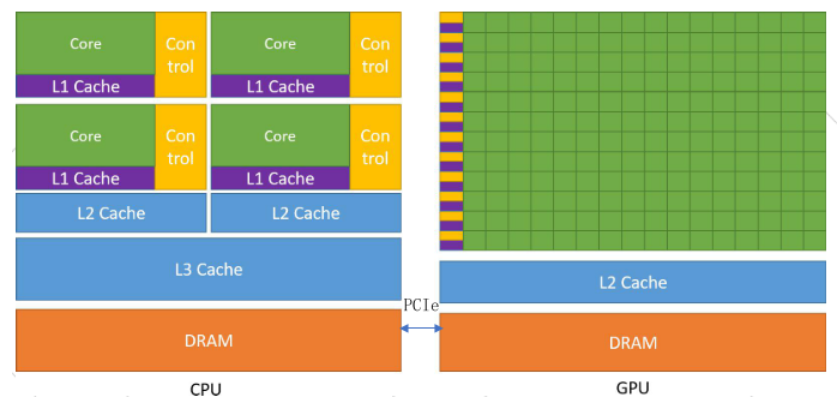
GPU:计算单元多,控制单元少,无大量Cache。
CPU:计算单元少,控制单元多, Cache占据了大量空间。
一个异构应用包括两部分:主机代码和设备代码。主机代码在CPU上运行,设备代码在GPU上运行。
程序通常由CPU初始化。在设备端加载计算密集型任务之前,CPU代码负责管理设备端的环境、代码和数据。
CPU适合处理数据规模较小、控制密集型任务,GPU适合处理数据规模较大、包含数据并行的计算密集型任务。
CUDA硬件环境
GPU架构:Tesla、Fermi、Kepler、Maxwell、Pascal、Volta、Turing、Ampere
显卡系列:GeForce、Quadro、Tesla、Jetson。
- GeForce:主要用于游戏和娱乐,也用于科学计算。
- Quadro:专业图形设计。
- Tesla:服务器专用卡,用于大规模并行计算,适用于机器学习。
- Jetson:适用于AI应用。
NVIDIA使用“计算能力”来对应硬件版本。
NVIDIA Amperep Architecture (compute capabilities 8.x):
- Tesla A Series
NVIDIA Turing Architecture (compute capabilities 7.x):
- GeForce 2000 Series Quadro RTX Series Tesla T Series
NVIDIA Volta Architecture (compute capabilities 7.x):
- DRIVE/JETSON AGX/Xavier Quadro GV Series Tesla v Series
NVIDIA Pascal Architecture (compute capabilities 6.x):
- Tegra X2 GeForce 1000 Series Quadro P Series Tesla P Series
重要概念
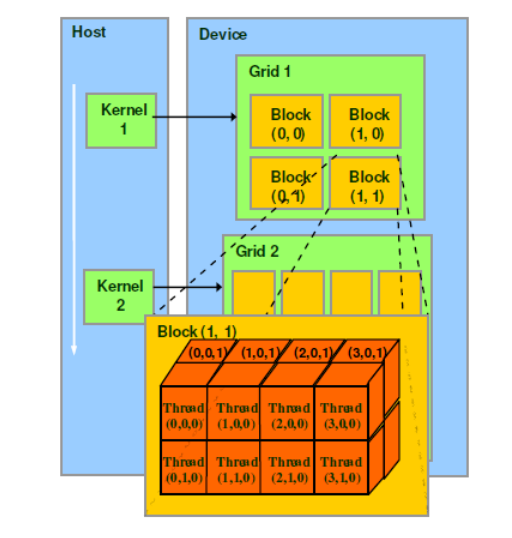
- thread: 一个CUDA的并行程序会被以许多个thread来执行。
- block: 数个thread组成一个block,同一个block中的thread可以同步,也可以通过shared memory进行通信。
- grid: 多个block则会再构成grid。
实际在硬件上就是按照 SM(Streaming MultiProcessor) 组织计算单元的。一个SM由多个流式单处理器(SP)组成。每个 SP 可以处理一个或多个线程。
SM采用的SIMT(Single-Instruction, Multiple-Thread,单指令多线程)架构,warp(线程束)是最基本的执行单元,一个warp包含32个并行thread。warp(线程束)由warp scheduler负责调度。
当一个kernel被执行时,gird中的block被分配到SM上,一个block的thread只能在一个SM上调度。
通常板块数量总是大于 SM 的数量,这时英伟达驱动就会在多个 SM 之间调度你提交的各个板块。正如操作系统在多个 CPU 核心之间调度线程那样。
GPU 不会像 CPU 那样做时间片轮换——板块一旦被调度到了一个 SM 上,就会一直执行,直到他执行完退出,这样的好处是不存在保存和切换上下文(寄存器,共享内存等)的开销,毕竟 GPU 的数据量比较大,禁不起这样切换来切换去。
一个grid可以包含多个block,block的组织方式可以是一维的,二维或者三维的。
CUDA中每一个线程都有一个唯一的标识ID即threadIdx,这个ID随着grid和block的划分方式的不同而变化。
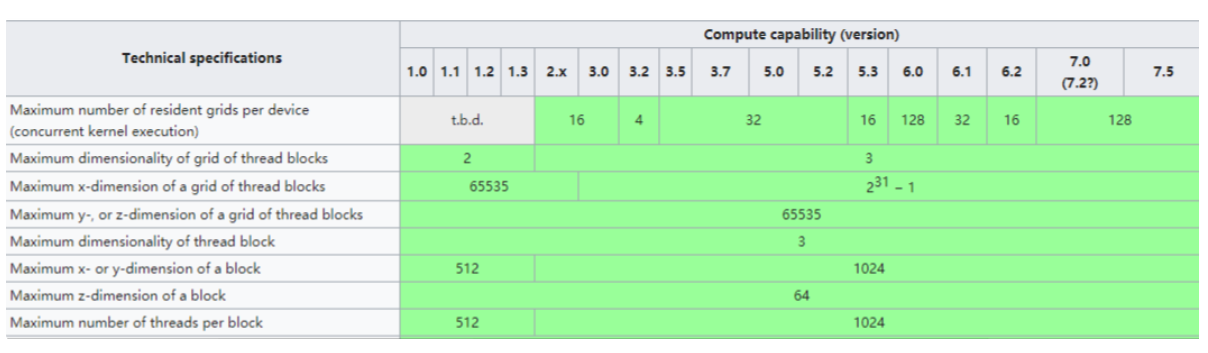
根据架构的不同,计算threadIdx需要考虑不同的维度。
版本52:Quadro M6000 , GeForce 900, GTX-970, GTX-980, GTX Titan X
版本53:Tegra (Jetson) TX1 / Tegra X1, Drive CX, Drive PX, Jetson Nano
版本60:Quadro GP100, Tesla P100, DGX-1 (Generic Pascal)
版本61:GTX 1080, GTX 1070, GTX 1060, GTX 1050, GTX 1030 (GP108), GT 1010 (GP108) Titan Xp, Tesla P40, Tesla P4, Discrete GPU on the NVIDIA Drive PX2
版本62:Integrated GPU on the NVIDIA Drive PX2, Tegra (Jetson) TX2
版本70:DGX-1 with Volta, Tesla V100, GTX 1180 (GV104), Titan V, Quadro GV100
版本72:Jetson AGX Xavier, Drive AGX Pegasus, Xavier NX
版本75:GTX/RTX Turing – GTX 1660 Ti, RTX 2060, RTX 2070, RTX 2080, Titan RTX, Quadro RTX 4000, Quadro RTX 5000, Quadro RTX 6000, Quadro RTX 8000, Quadro T1000/T2000, Tesla T4
版本80:NVIDIA A100 (the name “Tesla” has been dropped – GA100), NVIDIA DGX-A100
版本86:Tesla GA10x cards, RTX Ampere – RTX 3080, GA102 – RTX 3090, RTX A2000, A3000, A4000, A5000, A6000, NVIDIA A40, GA106 – RTX 3060, GA104 – RTX 3070, GA107 – RTX 3050, Quadro A10, Quadro A16, Quadro A40, A2 Tensor Core GPU
使用NVCC编译,需要注意版本号:
1 | |
使用CMake,可以指定多个可选版本号,但是会增加编译时间:
1 | |
CUDA软件体系
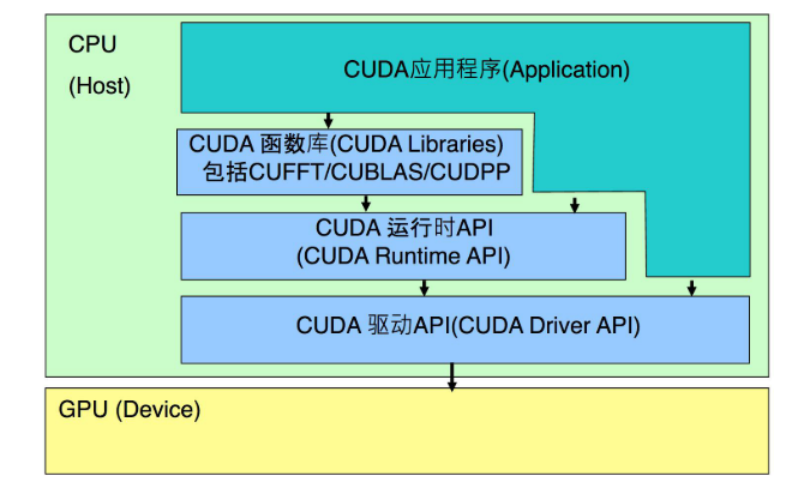
CUDA
- cuFFT :利用CUDA进行快速傅里叶变换的函数库 。
- cuBLAS:线性代数方面的CUDA库。
- cuDNN :利用CUDA进行深度卷积神经网络,深度学习常用。
- thrust:实现了众多基本并行算法的C++模板库。
- cuSolver:线性代数方面的CUDA库。
- cuRAND:随机数生成有关的库。
CUDA API
CUDA 运行时 API和CUDA 驱动API提供了实现设备管理、上下文管理、存储器管理、代码块管理、执行控制、 纹理索引管理与OpenGL和Direct3D的互操作性的应用接口。
驱动API是一种基于句柄的底层接口,大多数对象通过句柄被引用,其函数前缀均为cu。
运行时API对驱动API进行了一定的封装,隐藏了其部分实现细节,因此使用起来更为方便,简化了编程的过程。
CUDA
CUDA是一种通用的并行计算平台和编程模型,是在C语言基础上扩展的。借助于CUDA,可以像编写C语言程序一样实现并行算法。
CUDA编程模型是一个异构模型,需要CPU和GPU协同工作,因此引入了主机(Host)端与设备 (Device)端的概念。
一个完整的CUDA程序由主机代码(串行代码)和设备代码(并行代码)组成。
CUDA程序实现流程
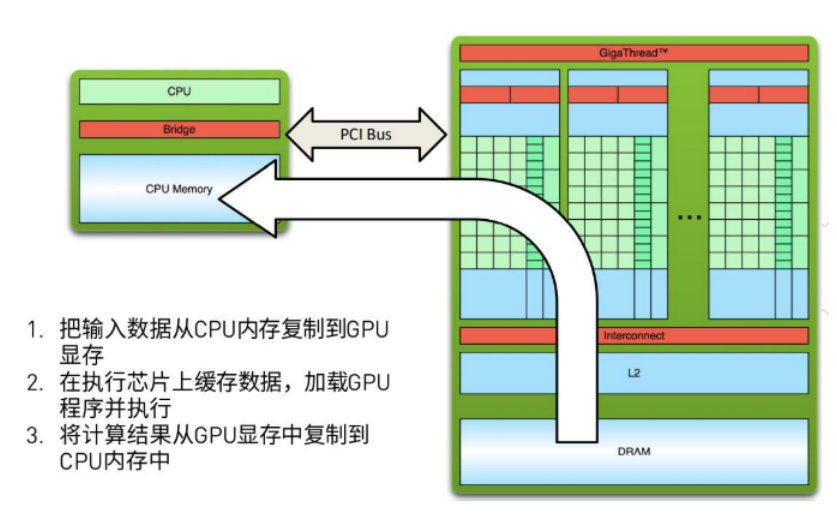
CUDA内存管理
CUDA运行时负责分配与释放设备内存,并且在主机内存和设备内存之间传输数据。
CUDA编程基础
CUDA程序主要由两部分组成,一部分是主函数,另一部分是设备函数。
__global__ 定义一个kernel函数入口函数,一般在CPU上调用,GPU上执行。函数类型必须为void类型。
__device__ 定义在device(GPU)执行的函数。
__host__ 定义在host(CPU)执行的函数。
使用nvcc对 .cu 源代码文件进行编译。
了 CUDA 的核函数调用时需要用 kernel<<<1, 1>>>() 这种语法。<<<block数量,每个板块中的线程数量>>>的形式,也就是<<<gridDim, blockDim>>>。总的板块数量由gridDim表示。
线程(thread):并行的最小单位 板块(block):包含若干个线程 网格(grid):指整个任务,包含若干个板块
线程<板块<网格
GPU 的板块相当于 CPU 的线程,GPU 的线程相当于 CPU 的SIMD,可以这样理解,但不完全等同。
CUDA 也支持三维的板块和线程区间。只要在三重尖括号内指定的参数改成 dim3 类型即可。
1 | |
二维的话,只需要把 dim3 最后一位(z方向)的值设为 1 即可。
线程索引
CUDA硬件环境部分,介绍了硬件在软件中的组织形式,所以可以计算:
1、 grid 1维,block 1维(blockDim 表示每一维的size, blockIdx表示在grid中的位置,threadIdx表示在block中的位置)
1 | |
2、 grid 1维,block 2维
1 | |
3、 grid 1维,block 3维
1 | |
4、 grid 2维,block 1维
1 | |
5、 grid 2维,block 2维
1 | |
6、 grid 2维,block 3维
1 | |
7、 grid 3维,block 1维
1 | |
8、 grid 3维,block 2维
1 | |
9、 grid 3维,block 3维
1 | |
CUDA编程
CUDA 的语法,基本完全兼容 C++。包括 C++17 新特性,都可以用。甚至可以把任何一个 C++ 项目的文件后缀名全部改成 .cu,都能编译出来。
CUDA 和 C++ 的关系就像 C++ 和 C 的关系一样,大部分都兼容,因此能很方便地重用 C++ 现有的任何代码库,引用 C++ 头文件等。
代码执行
__global__
定义函数 kernel(从 CPU 端通过三重尖括号语法调用),前面加上 __global__ 修饰符,即可让他在 GPU 上执行。不可以有返回值。
GPU 和 CPU 之间的通信,为了高效,是异步的。CPU实际上只是把 kernel 这个任务推送到 GPU 的执行队列上,然后立即返回,并不会等待GPU执行完毕。
可以调用 cudaDeviceSynchronize(),让 CPU 陷入等待,等 GPU 完成队列的所有任务后再返回。
核函数调用核函数
从 Kelper 架构开始,__global 里可以调用另一个 __global,也就是说核函数可以调用另一个核函数,且其三重尖括号里的板块数和线程数可以动态指定。
1 | |
__device__
__device__ 则用于定义设备函数,他在 GPU 上执行,但是从 GPU 上调用的,而且不需要三重尖括号,和普通函数用起来一样,可以有参数,有返回值。
默认情况下 GPU 函数必须定义在同一个文件里。如果你试图分离声明和定义,调用另一个文件里的 __device 或 __global 函数,就会出错。
建议把要相互调用的 __device__ 函数放在同一个文件,这样方便编译器自动内联优化。
__host 则相反,将函数定义在 CPU 上。任何函数如果没有指明修饰符,则默认就是 __host。
通过 __host __device 这样的双重修饰符,可以把函数同时定义在 CPU 和 GPU 上。
总结
host 可以调用 global;global 可以调用 device;device 可以调用 device。
CUDA内联
inline 在现代 C++ 中的效果是声明一个函数为 weak 符号,和性能优化意义上的内联无关。
优化意义上的内联指把函数体直接放到调用者那里去。CUDA 编译器提供了__inline__ 来声明一个函数为内联。不论是 CPU 函数还是 GPU 都可以使用,只要你用的 CUDA 编译器。
__inline__ 不一定就保证内联了,如果函数太大编译器可能会放弃内联化。
因此 CUDA 还提供 __forceinline 这个关键字来强制一个函数为内联。GCC 也有相应的 __attribute((“always_inline”))。
还有 __noinline__ 来禁止内联优化。
constexpr 函数
指定 --expt-relaxed-constexpr 这个编译选项,把 constexpr 函数自动变成修饰 __host __device。因为 constexpr 通常都是一些可以内联的函数,数学计算表达式之类的。
当然,constexpr 里没办法调用 printf,也不能用 __syncthreads 之类的 GPU 特有的函数,因此也不能完全替代 __host 和 __device。
内存管理
从核函数里返回数据
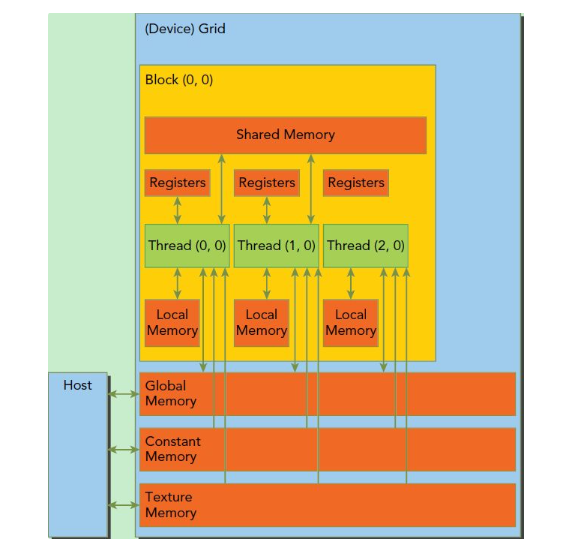
GPU 使用独立的显存,不能访问 CPU 内存。CPU 的内存称为主机内存(host)。GPU 使用的内存称为设备内存(device),他是显卡上板载的,速度更快,又称显存。
用 cudaMalloc 分配 GPU 上的显存,这样就不出错了,结束时 cudaFree 释放。cudaMalloc 的返回值已经用来表示错误代码,所以只能通过 &pret 二级指针返回结果。
1 | |
helper_cuda.h 在 /opt/cuda/samples/common/inc/helper_cuda.h ,可以直接将其和
helper_string.h 一起拷贝到指定的 include 文件夹下,使用一些封装好的功能。
这里比如保存在 .cu 文件的同级目录下include文件夹下,更改CMake文件:
1 | |
使用 checkCudaErrors 宏可自动帮你检查错误代码并打印在终端,然后退出。还会报告出错所在的行号,函数名等。
使用nvcc编译,就添加 --include-path 编译选项。
跨 GPU/CPU 地址空间拷贝数据
cudaMemcpy,他能够在 GPU 和 CPU 内存之间拷贝数据。
cudaMemcpy 会自动进行同步操作,即会调用 cudaDeviceSynchronize() !
1 | |
统一内存地址技术(Unified Memory)
一种在比较新的显卡上支持的特性,那就是统一内存(managed),只需把 cudaMalloc 换成 cudaMallocManaged 即可,释放时也是通过 cudaFree。
从 Pascal 架构开始支持的,也就是 GTX9 开头及以上。
这样分配出来的地址,不论在 CPU 还是 GPU 上都是一模一样的,都可以访问。而且拷贝也会自动按需进行(当从 CPU 访问时),无需手动调用 cudaMemcpy。
虽然方便,但并非完全没有开销,手动拷贝可能高效一些。
1 | |
总结
- 主机内存(host):malloc、free
- 设备内存(device):cudaMalloc、cudaFree
- 统一内存(managed):cudaMallocManaged、cudaFree
C++封装
定制CudaAllocator,构建在GPU上的vector对象。
注意,vector 在初始化的时候(或是之后 resize 的时候)会调用所有元素的无参构造函数,对 int 类型来说就是零初始化。然而这个初始化会是在 CPU 上做的,因此我们需要禁用他。
通过给 allocator 添加 construct 成员函数,来魔改 vector 对元素的构造。
只需要判断是不是有参数,然后是不是传统的 C 语言类型(plain-old-data),如果是,则跳过其无参构造,从而避免在 CPU 上低效的零初始化。
1 | |
核函数可以是一个模板函数
CUDA 的优势在于对 C++ 的完全支持。所以 __global__ 修饰的核函数自然也是可以为模板函数的。
调用模板时一样可以用自动参数类型推导,如有手动指定的模板参数(单尖括号)请放在三重尖括号的前面。
核函数可以接受 functor,实现函数式编程
1 | |
注意:
- Func 不可以是 Func const &,那样会变成一个指向 CPU 内存地址的指针,从而出错。所以 CPU 向 GPU 的传参必须按值传。
- 做参数的这个函数必须是一个有着成员函数 operator() 的类型,即 functor 类。而不能是独立的函数。
- 这个函数必须标记为 __device__,即 GPU 上的函数,否则会变成 CPU 上的函数。
functor 可以是 lambda 表达式。不过必须在 [] 后,() 前,插入 __device__ 修饰符。而且需要开启 --extended-lambda 编译选项。在 CMake 中表示为:
1 | |
这里使用了 CMake 的生成器表达式,限制 flag 只对 CUDA 源码生效。
捕获外部变量
将 GPU 上的内存地址浅拷贝到 lambda 中。
1 | |
不能 [=] 传arr,因为vector 默认深拷贝。或者 [&] 传arr,因为arr是个CPU上的对象,不是GPU上实际内存地址的指针。
数学运算
使用C的函数计算,通过GPU进行加速。GPU 比 CPU 快了很多。另外GPU需要预热,若执行多次循环,速度会更快,相差100倍是没问题的。
注意计算 float 类型数值,使用对应 float 版本函数,sinf、cosf、rsqrtf等。
两个下划线的是 __sinf 是 GPU intrinstics,适合对精度要求不高,但有性能要求的图形学任务。
编译选项
--ftz=true 会把极小数(denormal)退化为0。
--prec-div=false 降低除法的精度换取速度。
--prec-sqrt=false 降低开方的精度换取速度。
--fmad 因为非常重要,所以默认就是开启的,会自动把 a * b + c 优化成乘加(FMA)指令。
若开启了 --use_fast_math 选项,那么所有对 sinf 的调用都会自动被替换成 __sinf。同时自动开启上述所有优化。
CUDA thrust 库
thrust 相当于设计给 GPU 的STL。包括上述中,GPU上的vector也不用手动实现,直接使用 thrust 就可以。
thrust::universal_vector 会在统一内存上分配,因此不论 GPU 还是 CPU 都可以直接访问到。
thrust::device_vector 则是在 GPU 上分配内存,thrust::host_vector 在 CPU 上分配内存。
可以通过 = 运算符在 thrust::device_vector 和 thrust::host_vector 之间拷贝数据,他会自动帮你调用 cudaMemcpy。
板块共享内存
GPU 是由多个流式多处理器(SM)组成的。每个 SM 可以处理一个或多个板块。
SM 又由多个流式单处理器(SP)组成。每个 SP 可以处理一个或多个线程。
每个 SM 都有自己的一块共享内存(shared memory),他的性质类似于 CPU 中的缓存——和主存相比很小,但是很快,用于缓冲临时数据。
在 CUDA 的语法中,共享内存可以通过定义一个修饰了 __shared__ 的变量来创建。
1 | |
内存延迟
SM 执行一个板块中的线程时,并不是全部同时执行的。而是一会儿执行这个线程,一会儿执行那个线程。某个线程有可能因为在等待内存数据的抵达,这时大可以切换到另一个线程继续执行计算任务。
内存延迟是阻碍 CPU 性能提升的一大瓶颈。
CPU 解决方案是超线程技术,一个物理核提供两个逻辑核,当一个逻辑核陷入内存等待时切换到另一个逻辑核上执行,避免空转。
GPU 的解决方法就是单个 SM 执行很多个线程,然后在遇到内存等待时,就自动切换到另一个线程。__syncthreads() 会强制同步当前板块内的所有线程。
线程组分歧(warp divergence)
GPU 线程组(warp)中 32 个线程实际是绑在一起执行的,就像 CPU 的 SIMD 那样。因此如果出现分支(if)语句时,如果 32 个 cond 中有的为真有的为假,则会导致两个分支都被执行!
建议 GPU 上的 if 尽可能 32 个线程都处于同一个分支,要么全部真要么全部假,否则实际消耗了两倍时间!
寄存器打翻(register spill)
板块中线程数量过多带来的问题。
GPU 线程的寄存器,实际上也是一块比较小而块的内存,称之为寄存器仓库(register file)。板块内的所有的线程共用一个寄存器仓库。
当板块中的线程数量(blockDim)过多时,就会导致每个线程能够分配到的寄存器数量急剧缩小。而如果你的程序恰好用到了非常多的寄存器,那就没办法全部装在高效的寄存器仓库里,而是要把一部分“打翻”到一级缓存中,这时对这些寄存器读写的速度就和一级缓存一样,相对而言低效了。若一级缓存还装不下,那会打翻到所有 SM 共用的二级缓存。
延迟隐藏(latency hiding)失效
板块中的线程数量过少带来的问题。
当线程组陷入内存等待时,可以切换到另一个线程,继续计算,这样一个 warp 的内存延迟就被另一个 warp 的计算延迟给隐藏起来了。因此,如果线程数量太少的话,就无法通过在多个 warp 之间调度来隐藏内存等待的延迟,从而低效。
最好让板块中的线程数量(blockDim)为32的整数倍,否则假如是 33 个线程的话,那还是需要启动两个 warp,其中第二个 warp 只有一个线程是有效的,非常浪费。
对于使用寄存器较少、访存为主的核函数(例如矢量加法),使用大 blockDim 为宜。反之(例如光线追踪)使用小 blockDim,但也不宜太小。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!