系统设计笔记
与面向对象
面向对象:具体细化的设计 系统设计:高屋建瓴,系统架构
示例:设计 twitter 系统
首先,先交流,比如用户规模、硬件条件等。
- 可行性 work solution
- special case
- analysis
- tradeoff
- knowledge base
4S分析
Scenario, Service, Storage, Scale
- Scenario 场景
- 说人话:需要设计哪些功能,设计得多牛
- Ask / Features / QPS / DAU / Interfaces
- Service 服务
- 说人话:将大系统拆分为小服务
- Split / Application / Module
- Storage 存储
- 说人话:数据如何存储与访问
- Schema / Data / SQL / NoSQL / File System
- Scale 升级
- 说人话:解决缺陷,处理可能遇到的问题
- Sharding / Optimize / Special Case
Work solution . NOT perfect solution.
Scenario
需要什么功能;多大的访问量(Daily active users, Monthly active users ...) 第一步 enumerate,罗列功能:
- Register / Login
- User Profile Display / Edit
- Upload Image / Video *
- Search *
- Post / Share a tweet
- Timeline / News Feed
- Follow / Unfollow a user 第二步 sort,选出核心功能:
- Post a Tweet
- Timeline
- News Feed
- Follow / Unfollow a user
- Register / Login 第三步 analysis & predict:
- 并发用户 concurrent user:
- 日活跃 = 每个用户平均请求次数 / 一天多少秒
- 峰值 Peak = average concurrent user * 3
- 对于快速增长的产品:MAX peak in 3 months = peak users * 2
- 读频率 read qps
- 写频率 write qps
QPS
- QPS = 100 用你的笔记本做 Web 服务器就好了
- QPS = 1k 用一台好点的 Web 服务器就差不多了,需要考虑 Single Point Failure
- QPS = 1m 需要建设一个1000台 Web 服务器的集群 ,需要考虑如何 Maintainance(某一台挂了怎么办
- QPS 和 Web Server (服务器) / Database (数据库) 之间的关系
- 一台 Web Server 约承受量是 1k 的 QPS (考虑到逻辑处理时间以及数据库查询的瓶颈)
- 一台 SQL Database 约承受量是 1k 的 QPS(如果 JOIN 和 INDEX query比较多的话,这个值会更小)
- 一台 NoSQL Database (Cassandra) 约承受量是 10k 的 QPS
- 一台 NoSQL Database (Memcached) 约承受量是 1M 的 QPS
Service 服务
差分系统:
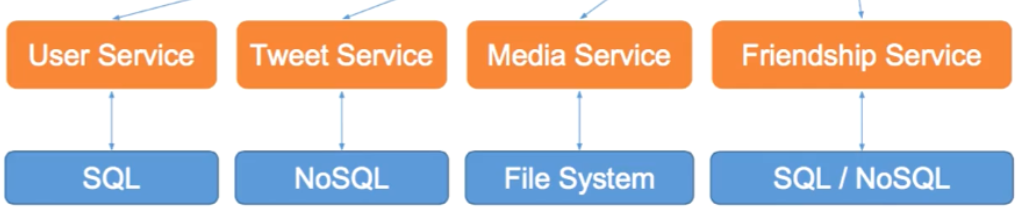
- replay 重放需求。比如,User Service, Tweet Service, Media Service,
Friendship Service
- 针对需求,添加服务
- 归并相同服务
- merge 归并需求
Storage 存储
- 数据库系统:对文件系统的一层包装,提供更丰富、功能更强大的接口
- 关系型数据库:用户信息
- 非关系型数据库:推文、社交图谱
- 文件系统
- 图片、视频
- 缓存
- 不支持数据持久化 nonpersistent
- 效率高,内存级访问速度
第一步 select:选择合适的存储结构 第二步 schema:细化数据表结构
程序 = 算法 + 数据结构 系统 = 服务 + 数据存储
设计 schema:
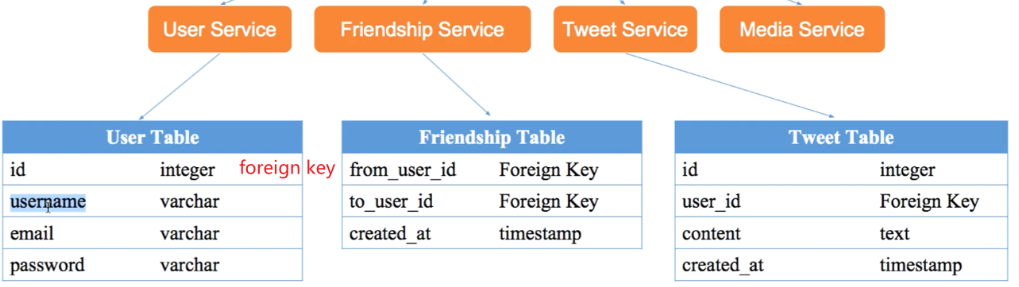
News Feed 如何存储
登录之后看到的信息流。每个人看到的内容时不同的。
Pull Model
主动拉取 算法:将每个好友的前100条信息,合并出100条news feed。 Merge K Sorted Arrays. 复杂度:N个关注对象,N次DB Reads 时间 + 归并时间。Post a tweet 是一次 DB Write 的时间。
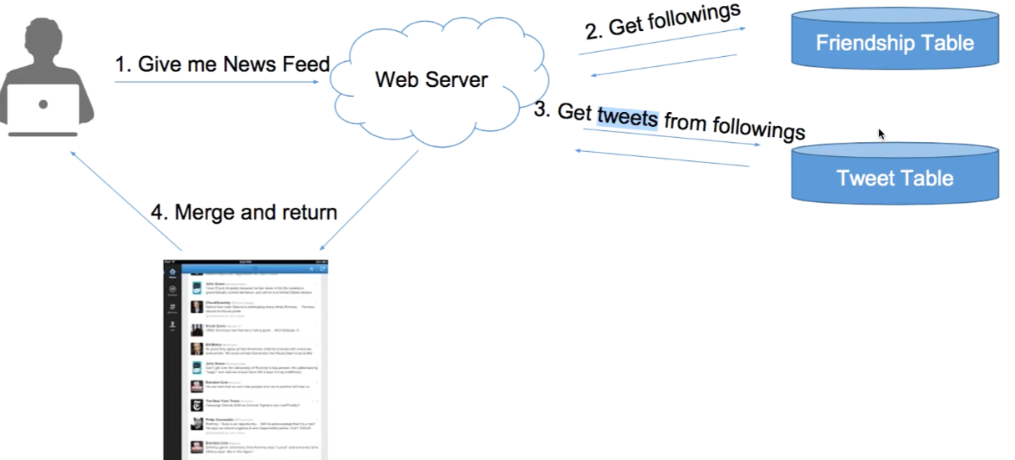
缺陷:
- N次 DB Reads非常慢
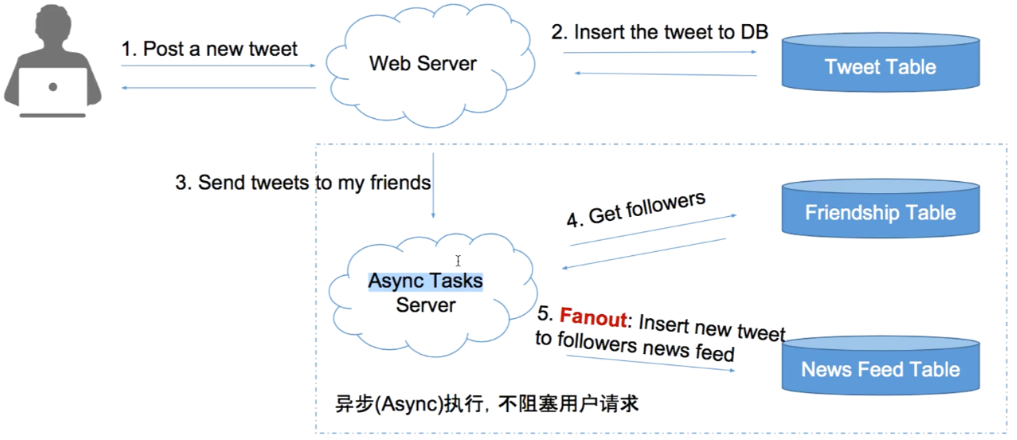
Push Model
算法:
- 每个用户一个 List 存储个人的 News Feed 信息
- 好友发出 tweet ,同步到每个用户的 List 中 (即 fanout 过程)
- 用户查询时,只需要从List中读取100条最新的信息 复杂度:
- 查询,执行一次 DB read
- post,N个粉丝,执行N次DB write。可异步执行。
新建 News Feed Table 可设计如下

建立索引:对于很大的 table,可建立 复合索引,先按x排序,x相同的再按照y排序,查询可以更高效。
比较
Social App的模型
- Facebook – Pull
- Instagram – Push + Pull
- Twitter -- Pull
- 朋友圈 -- Push
为了更好的 ranking,一般使用 Pull 模型。
Scale 扩展
优化系统
第一步 optimize:设计缺陷;功能设计;特殊情况 第二步 maintenance: 鲁棒性;扩展性
Pull 缺陷
- DB reads 前加入 cache
- cache 每个用户的 timeline:trade off,cache多少
- cache 每个用户的 news feed:没有 cache 时,读取,归并,然后取100;有cache时,归并N个用户在某个时间戳之后的 tweets
Quest: 对比 MySQL 与 Memcahed QPS
Push 缺陷
- 消耗更多的 Disk 空间,BUT disk is cheap. (Pull 取数据存在 内存 中)
- Inactive Users:粉丝排序,比如按登录时间顺序排序,先fanout活跃用户
- 异步的一种潜在缺陷:Unfollow 之后,刷新 timeline 存在延迟
结合
- 在现有模型的基础上,做最小的改,比如用更多的机器进行 Push 的fanout
- 对长期的增长进行估计,评估是否值得转换模型
结合方案:
- 普通用户:Push
- 明星用户:不进行 Push
- 当用户需要的时候,从明星用户的timeline里取,并合并到 news feed 中
出现问题:如何定义 明星用户?当明星用户突然变成普通用户从 Pull 模型转换为 Push 模式,如何保证前明星用户的信息推送到粉丝 news feed 中?
- 是不是明星不能在线动态计算,要离线计算
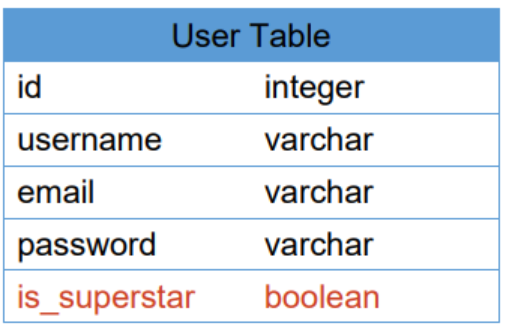
- 为 User 增加一个 is_superstar 的属性
- 一个用户被标记为 superstar 之后,就不能再被取消标记
选择 tradeoff
什么时候用 Push ?
- 资源少
- 少写代码
- 实时性要求不高
- 用户发帖少
- 双向好友关系,没有明星问题(朋友圈)
什么时候用 Pull ?
- 资源充足
- 实时性要求高
- 用户发帖很多
- 单向好友关系,有明星问题
其他通用问题
- 数据库服务器挂了怎么办?
- 用户逐渐增加怎么办?
- 服务器顶不住压力
- 数据库顶不住压力
系统设计总结
- No more no less
- Work solution first
- Analysis is important than solution
拓展问题:Normalize VS Denormalize
扩展问题:惊群现象 Thundering Herd
通常会使用缓存来作为数据库的“挡箭牌” ,优化一些经常读取的数据的访问速度。 在高并发情况下,如果一条非常热的数据,因为 “缓存过期” 或者 “被淘汰算法淘汰”, 缓存之后,会导致短时间内(<1s), 大量的数据请求会出现 “缓存穿透”(Cache Miss),因为数据从 DB 到 Cache 需要时间,从而这些请求都会去访问数据库,导致数据库处理不过来而崩溃,从而影响 到其他数据的访问而导致整个网站崩溃。
解决办法及参考资料 Memcache Lease Get - 《Scaling Memcache at Facebook》http://bit.ly/1jDzKZK Facebook 如何解决惊群效应的:https://bit.ly/1Q3t3P7 Redis 防雪崩架构设计 https://bit.ly/2KFneb
消息队列
- 先进先出的任务队列
- 做任务的worker进程共享一个列表
- worker从任务列表中获取任务,做完之后反馈给队列服务器
- 队列服务器是做异步任务必须要有的组成部分 常用:RabbitMQ、ZeroMQ、Redis、Kafka
其他问题
- news feed 如何实现 分页 pagination?
- twitter pull 用 cache 来存 timeline 时,如何保存实时性问题?
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!