Knowledge Distillation Note
知识蒸馏模型采用类似迁移学习的方法,通过采用预先训练好的老师模型(Teacher model)的输出作为监督信号去训练另外一个简单的学生模型(Student model)。
所谓的知识就是从输入向量引至输出向量的节点图。
大概分为三类:知识蒸馏(模型压缩),跨域迁移无标签转换,集成蒸馏。
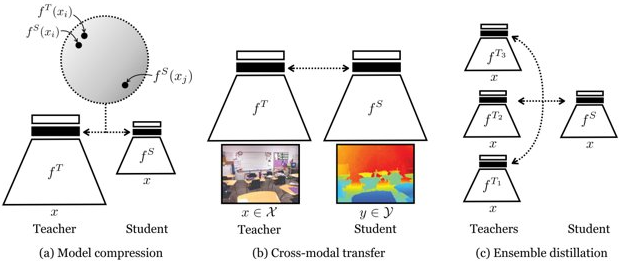
此处关注知识蒸馏(模型压缩)这一类。
First Step
1、训练复杂的教师模型(teacher model):先用硬目标(hard target),也就是正常的标签(label)训练大模型。
2、计算软目标(soft target):利用训练好的大模型来计算软目标(soft target),也就是大模型预测后再经过softmax层的输出。
3、训练小模型,在小模型的基础上再加一个额外的软目标(soft target)的损失函数,通过权重参数来调节两个损失函数的比重。
4、预测时,将训练好的小模型来进行实验。
软目标(soft target),尽量提高复杂模型里的信息量,也就是熵。
离散的数据在等概的情况下熵值是最大的,在分类的过程中,要尽量贴近与等概率的情况,这样就可以使得软目标(soft target)在每次训练的过程中获得更多的信息和更小的梯度方差,小模型可以用更少的数据和更小的学习率来进行训练,进一步压缩。
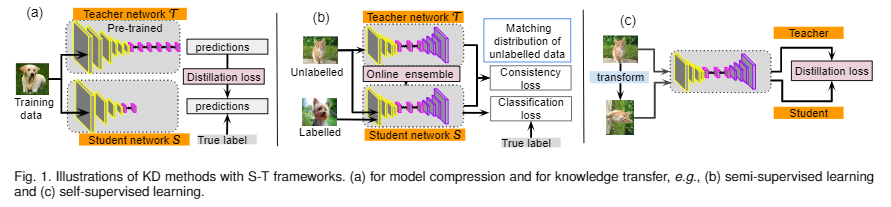
方法分类:
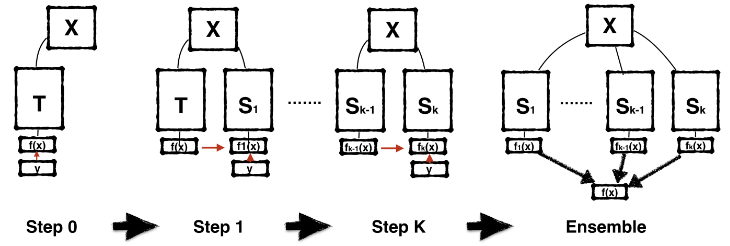
模型传递训练集成算法:训练学生模型,使其参数和教师模型一样,而不是压缩模型。如图,从教师训练学生1,以此由学生i训练学生i+1,最后集成所有的学生模型。
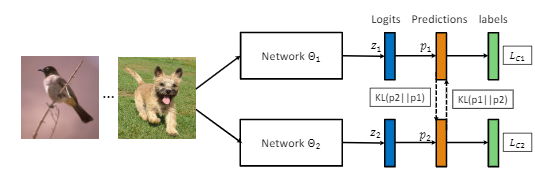
交替式训练模型算法:采用多个网络同时进行训练,每个网络在训练过程中不仅接受来自真值标记的监督,还参考同伴网络的学习经验来进一步提升泛化能力。在整个过程中,两个网络之间不断分享学习经验,实现互相学习共同进步。两个网络的优化是迭代进行的,直到收敛。
特征表示训练:使用回归模块来配准部分学生网络和部分教师网络的输出特征,并且对输出特征进行处理,可以将网络处理的重点放在得到相似的特征层。
自注意力蒸馏算法:Self Attention Distillation,称为SAD。对于多通道的主力意图有三种方法:1.绝对值求和;2.绝对值指数求和,指数大于1;3.绝对值指数求最大值。让浅层特征来学习高层特征的表达,从而加强网络的整体特征表达能力。这种底层特征模仿高层特征的学习过程,属于自注意力蒸馏(Self Attention Distillation)。
此处更关注特征表示训练这一类。NLP中用的最多的一些方法也来自这一类。比如:DistilBERT学习最后一层的表示。PKDBERT(Patient Knowledge Distillation)同时学习中间层的表示。TinyBERT将embedding层也纳入学习的范畴。同时关注新的基于对比学习的方法。
Contrastive Representation Distillation
基本假设,知识蒸馏应该要迁移的是表征representation,而不是概率分布(不管是使用KL散度还是L2距离)。同时之前的不是基于对比学习的方法,会丢失Teacher模型输出表征representation的结构信息,即忽略了维度间有很复杂的依赖关系。
因为KL散度或者L2距离计算将每个维度认为是独立的,在表征学习中,很难保证这里的独立假设是完成成立的。
符号定义:

这里 \(Z^T=W_T(T), Z^S=W_S(S)\), \(\sigma\) 为 softmax 函数。
损失函数:
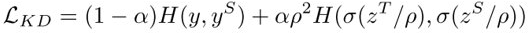
两个H表示不同的函数,第一个表示交叉熵(标签),第二个表示KL散度(表征)。
对比学习引入
S和T的输入是相同的时,表征应该相似。S和T的输入是不同的时,表征应该不同。
同时衡量表征差异的方法,变为NCE,从而引入的负例,即
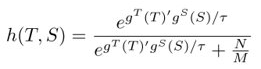
对比学习的目标函数为:
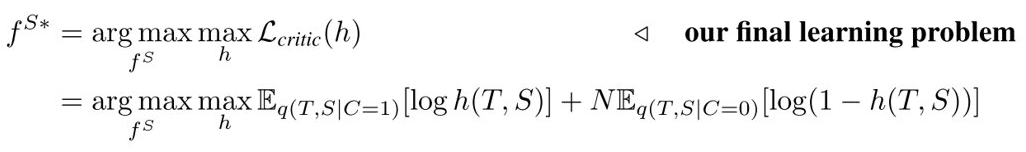
如果只是使用该方法,那到此已经可以用了。
目标函数推导
假设,S和T的输入是相同时,C=1(T, S同分布),否则C=0(T, S不同分布)。有1个相关输入对,N个无关输入对,M为数据集的大小。
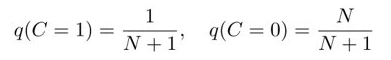
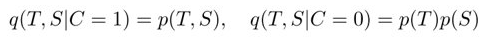
计算\(q(C=1|T,S)\):
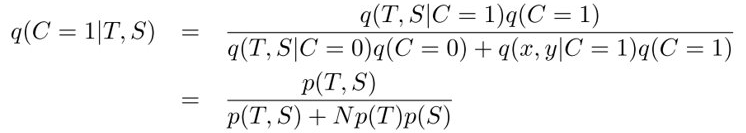
取对数,同时乘上-1:
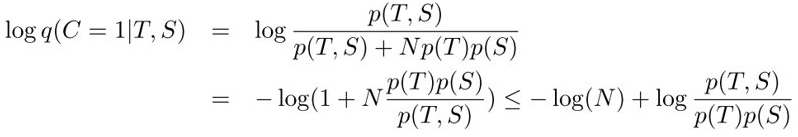
交换 log(N) 项,两边按p(T,S)求积分:
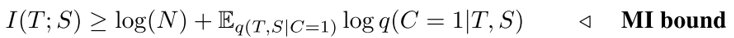
定义:
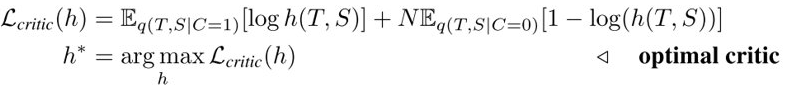
引入NCE,不等式右边写成:
设 \(h^*(T, S)=q(C=1|T,S), h^*=argmax\ L_{critic}(h)\)
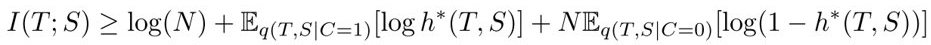
由于 \(h^*\) 是极大值点,所以,一般性的 \(h\) 都有下式成立:
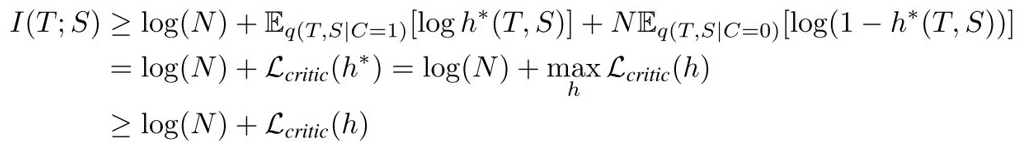
其中h为:
所以方法就是先找到 T和S 表征的互信息的上界,然后,优化student模型,使得互信息关于S的下界最大,得到最优的学生模型。
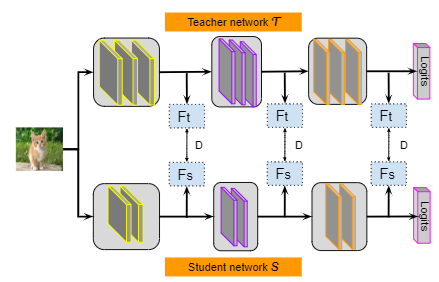
Softmax Regression Representation Distillation
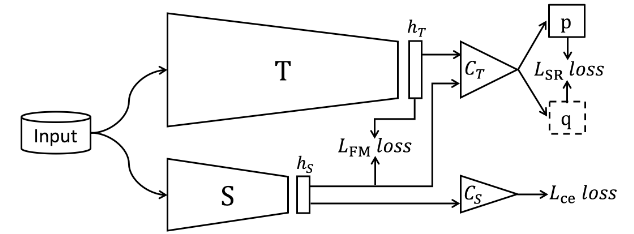
方法基本如图所示,就是设计了三种损失相加。

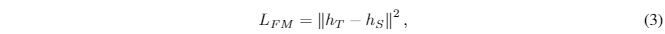
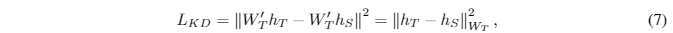
works slightly better than the cross-entropy loss.
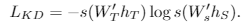
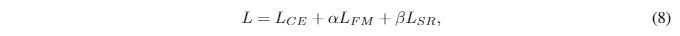
相对而言,没有设计对比学习,但是论文实验结果还是不错的,相比上一节CRD方法,简单不少,但是效果也不错。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!