Pointer review
回顾一下Pointer network
Pointer ? What ?
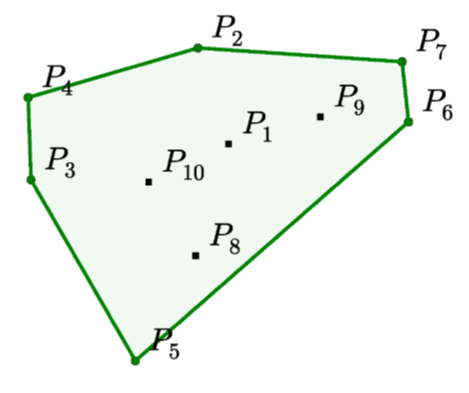
从一堆点中,找出 凸包 边界点。
convex hull:一条圈住所有点的橡皮筋
Seq generation bad
seq2seq,在处理生成任务时,无法处理 OOV 问题。可以理解为,在decode时映射的词表vocabulary是变化的。
How to solve?
假如,将输入text中每个word当做一个点,seq2seq任务转换为在输入的文本中找到一个 “convex hull” 可以summarize整个输入的语义内容,是否可行?
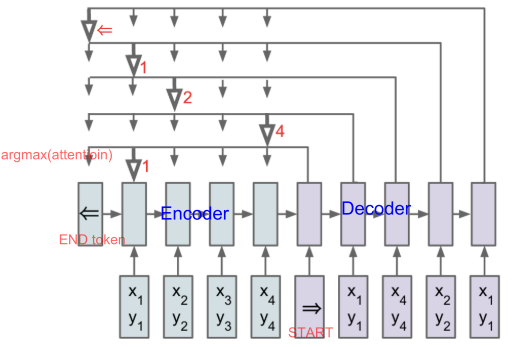
输出全都从 输入 中 copy。
根据输入的语义表示,用一个language model输出生成文本。
假如要保持 decoder 的language model的泛化生成能力,同时copy一些输入中的重要信息。模型被修改为下面这样
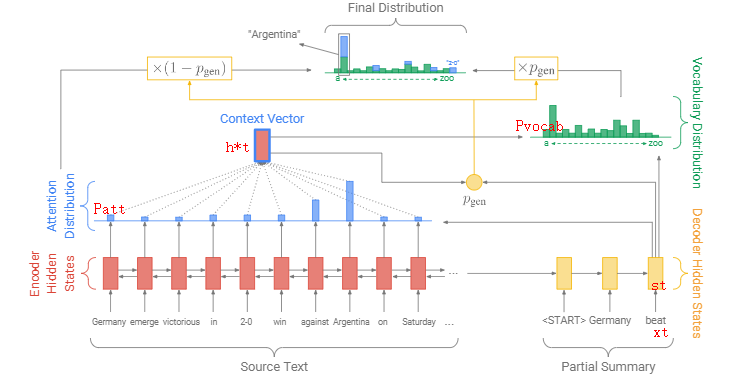
输出为:联合 source text 中的attention distribution 和 decoder在vocabulary上的预测分布,以 Pgen 加权的结果。
Final distribution的分布中是包含了 source text 和 vocabulary 中的所有词的。
同时,\(P_{gen}\)设计为可学习的参数。
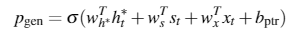
Reduce repeats?
将 attention distribution 进行历史累计,在下一步计算attention时输入。即,Coverage Mechanism。
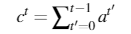
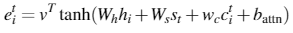
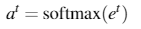
同时,添加新的损失项。让模型不要过分关注某些词。:
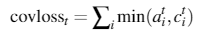
最终损失为:
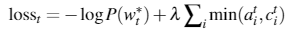
More
注意事项:
(1)在模型训练到一定程度后,再使用Coverage Mechanism。
(2)在模型的训练环节,刚开始的时候,大约有70%的输出序列是由Pointer Network产生的,随着模型逐渐收敛,这个概率下降到47%。然而,在测试环节中,有83%的输出序列是由Pointer Network产生的。作者猜测这个差异的原因在于:训练环节的decoder使用了真实的目标序列。
(3)作者曾尝试使用一个15万长度的大词表,但是并不能显著改善模型效果。
其他同类模型:
- 将LM部分也变为 attention ,进行多个 source text 的输入的生成任务。Multi-Source Pointer Network
- 不计算 \(P_{gen}\) ,而直接分成多种 情况,进行不同的 生成过程。CopyNet
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!