模型 FLAT FLAT部分Blog原文:https://mp.weixin.qq.com/s/6aU6ZDYPWPHc3KssuzArKw
论文:FLAT: Chinese NER Using Flat-Lattice Transformer
将Lattice图结构无损转换为扁平的Flat结构的方法,并将LSTM替换为了更先进的Transformer
Encoder,更好地建模了序列的长期依赖关系 ;
提出了一种针对Flat结构的相对位置编码机制 ,使得字符与词汇信息交互更直接,在基于词典的中文NER模型中取得了SOTA。
由于中文词汇的稀疏性和模糊性,基于字符的序列标注模型往往比基于词汇的序列标注模型表现更好,但在基于字符的模型中引入分词信息 往往能够带来性能的提升,尤其是对于NER任务来说,词汇能够提供丰富的实体边界信息。
Lattice
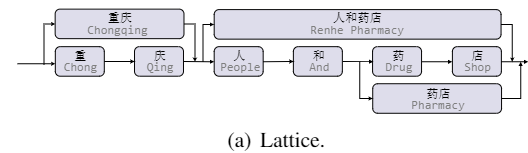
LSTM首次提出使用Lattice结构在NER任务中融入词汇信息,如图所示,一个句子的Lattice结构是一个有向无环图,每个节点是一个字或者一个词。
设计适应Lattice结构的模型
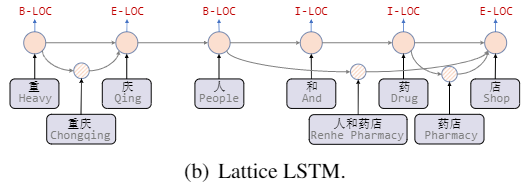
Lattice LSTM (ACL 2018):
将词汇信息引入中文NER的开篇之作,作者将词节点编码为向量,并在字节点以注意力的方式融合词向量。
Lexicon Rethink CNN(IJCAI 2019):
作者提出了含有rethink机制的CNN网络解决Lattice LSTM的词汇冲突问题。
RNN和CNN难以建模长距离的依赖关系,且在Lattice
LSTM中的字符只能获取前向信息,没有和词汇进行足够充分的全局交互
FLAT Git
Repo
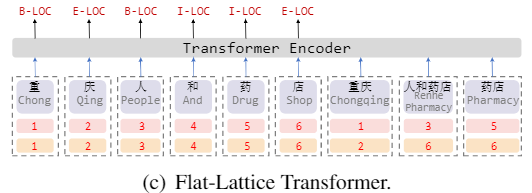
从Transformer的position
representation得到启发,作者给每一个token/span(字、词)增加了两个位置编码,分别表示该span在sentence中开始(head)和结束(tail)的位置
扁平的结构允许我们使用Transformer
Encoder,其中的self-attention机制允许任何字符和词汇进行直接的交互
Relative Position Encoding
of Spans span是字符和词汇的总称,span之间存在三种关系:交叉、包含、分离,然而作者没有直接编码这些位置关系,而是将其表示为一个稠密向量。作者用
和 表示span的头尾位置坐标,并从四个不同的角度来计算 和 的距离:
使用\(A^{*}_{i,j}\) 代替 tranformer
的self attention 中的 \(A_{i,j}\) :
通过FLAT模型后,取出token的编码表示,将其送入CRF层进行解码得到预测的标签序列。
论文中给出的结果显示,FLAT相较于一众NER模型,取得了SOTA的效果。同时,使用较大规模数据时,效果更好。在对比实验中发现,字符与包含它的词汇之间的充分交互是很重要的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 class MultiHeadAttention (nn.Module) :def __init__ (self, hidden_size, num_heads, scaled=True, attn_dropout=None) :assert (self.per_head_size * self.num_heads == self.hidden_size)True )True )def forward (self, key, query, value, pos, flat_mask) :"pos 为 自定义的 postion embedding,对应公式的 Rij" 0 )-1 , self.num_heads, self.per_head_size])-1 , self.num_heads, self.per_head_size])-1 , self.num_heads, self.per_head_size])3 ]) + [self.num_heads, self.per_head_size])1 , 2 )1 , 2 )1 , 2 )-1 , -2 )0 ).unsqueeze(-2 )0 , 3 , 1 , 4 , 2 )2 ), 1 , self.per_head_size])1 , self.num_heads, 1 , 1 , self.per_head_size)-2 )if self.scaled:1 - flat_mask.long().unsqueeze(1 ).unsqueeze(1 )-1e15 )-1 )1 , 2 ).contiguous().reshape(batch, -1 , self.hidden_size)return result
BERT 教程博客很多,比如 http://jalammar.github.io/illustrated-bert/
CRF 参考 note1
note2
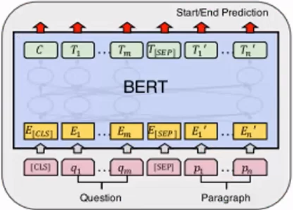
MRC 论文:A Unified MRC Framework for Named Entity Recognition
Git
Repo
转换为阅读理解(MRC)任务,来解决NER问题。似乎有很多搞研究的,都在尝试将NLP问题转换到MRC框架下,解决问题。
目的,解决NER中的实体重叠、嵌套关系问题。这是序列建模方式,比较难处理的问题。
数据,处理为三元组形式:(问题,答案,上下文)
其中,问题:一段对 实体类型
的描述文字,多种实体,就有多个问题;答案:为 实体的起始
index;上下文就是待识别的整个文本。
模型,使用BERT:
每个token预测输出有两个,是否为实体开始字,是否为实体结束字。
输出为 2
维,是和不是的预测概率。分别对每个位置判断,是否为开始字或者结束字。
但是这个两个集合,在有监督数据条件下,即训练时,并没有必要,只在预测推断时使用(推断需要通过下式计算所有组合的概率
P)。因为下式:
直接根据标注数据的 i, j 对标注部分计算 P。而不用对所有 i, j
组合算一次 P。
损失,多个预测损失之和:
权重为超参数。
Simple-Lexicon 论文:Simple-Lexicon:Simplify the Usage of Lexicon in Chinese
NER
Git
Repo
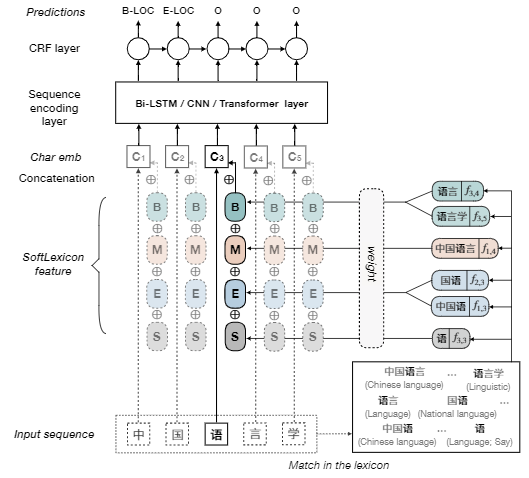
在Embedding信息的输入上进行改进,尝试了多种方式。
Softword:使用分词工具,标记词的
BMESO,结合字向量和标记向量输入。存在误差传播问题,无法引入一整个词汇对应word
embedding
ExtendSoftword:组合所有字的所有BME,得到可能的词,但是无法复原原始的词汇信息是怎样
Soft-lexicon:对当前字符,依次获取BMES对应所有词汇集合。
根据词频加权词向量,与字向量求和。
该模型比Lattice LSTM,
WC-LSTM等,在输入embedding上进行改进的模型,效果更好,更容易使用和迁移。
策略 Positive-unlabeled
learning -- PU Learning
在只有正类和无标记数据的情况下,训练二分类器
Method 1 Directly
将正样本和部分筛选出的未标记样本分别看作是positive samples和negative
samples
训练一个分类器,输出样本属于正、负类的概率
使用训练好的分类器。分类未标注数据,若正类的概率 大于
负类的概率,则该未标注样本的更可能为正类
Method 2 PU bagging
将所有正样本和未标记样本进行随机组合 bootstrap 来创建训练集;
将正样本和未标记样本视为positive和negative,训练一个分类器;
将分类器应用于不在训练集中的未标记样本 OOB(“out of
bag”),并记录其分数;
重复上述三个步骤,最后每个未标记样本的分数为每一轮 OOB分数
的平均值。
Method 3
人工标注一部分确认为负类的数据,训练分类器识别这些 确认为
负类的数据。
示例
示例
论文:Distantly Supervised Named Entity Recognition using
Positive-Unlabeled Learning,将PU Learning应用在NER任务上 Git Repo :
首先有 未标记数据 Du,实体字典 Dict;
使用最大匹配方法,标记一部分
Du,是NE则为正类,不是NE则为负类;
对每一种NE类型(比如,Loc,Nane)训练一个PU
分类器(自定义的神经网络模型);
使用多个PU 分类器,对剩余的
Du,进行预测,每一个词,取预测概率最大的那一类标记;
若某些 词 多次被预测为
实体,且每次出现都被预测为同一类实体,那么,将这个词,加入Dict;
重复以上步骤,直到Dict不再改变。
FGM 引用Blog原文
对抗可以作为一种防御机制,并且经过简单的修改,便能用在NLP任务上,提高模型的泛化能力。对抗训练可以写成一个插件的形式,用几行代码就可以在训练中自由地调用。
在原始输入样本
其中,
其中,
Goodfellow还总结了对抗训练的两个作用:
提高模型应对恶意对抗样本时的鲁棒性;
作为一种regularization,减少overfitting,提高泛化能力。
从优化的视角,问题重新定义成了一个找鞍点的问题,Min-Max:内部损失函数的最大化,外部经验风险的最小化:
内部max是为了找到worst-case的扰动,也就是攻击,其中,
外部min是为了基于该攻击方式,找到最鲁棒的模型参数,也就是防御,其中
CV任务的输入是连续的RGB的值,而NLP问题中,输入是离散的单词序列,一般以one-hot
vector的形式呈现,如果直接在raw
text上进行扰动,那么扰动的大小和方向可能都没什么意义。Goodfellow在17年的ICLR 中提出了可以在连续的embedding上做扰动。在CV任务,根据经验性的结论,对抗训练往往会使得模型在非对抗样本上的表现变差,然而神奇的是,在NLP任务中,模型的泛化能力反而变强了。
因此,在NLP任务中,对抗训练的角色不再是为了防御基于梯度的恶意攻击,反而更多的是作为一种regularization,提高模型的泛化能力 。
对抗训练,FSGM的修改版本,取消了符号函数,对梯度计算进行scale,而不是只使用
+1 或者 -1 代替。
原网络进行一次,前向反向传播,得到梯度g
计算embedding矩阵的修正梯度 r:
\(r=\frac{\epsilon
g}{\|g\|_{2}}\)
输入 embedding + r ,计算对抗梯度 ga
将 ga 累加到 g 中,得到 gf
恢复原网络的embedding数值,使用 gf 对参数进行更新
Projected Gradient
Descent(PGD) :“小步走,多走几步” ,如果走出了扰动半径为
其中
PGD模型能够得到一个非常低且集中的loss分布 。
另外在半监督条件下,也可以使用对抗训练方法Virtual Adversarial
Training进行半监督训练。
示例代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 import torchdef save_grad (tensorName) :def backward_hook (grad: torch.Tensor) :return backward_hookclass PGD :def __init__ (self, model) :def attack (self, epsilon=1. , alpha=0.3 , emb_name='emb.' , is_first_attack=False) :for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:if is_first_attack:if norm != 0 and not torch.isnan(norm):def restore (self, emb_name='emb.' ) :for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:assert name in self.emb_backupdef project (self, param_name, param_data, epsilon) :if torch.norm(r) > epsilon:return self.emb_backup[param_name] + rdef backup_grad (self) :for name, param in self.model.named_parameters():if param.requires_grad:def restore_grad (self) :for name, param in self.model.named_parameters():if param.requires_grad:if __name__ == '__main__' :3 for batch_input, batch_label in data:for t in range(K):0 )) if t != K-1 :else :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import torchclass FGM :def __init__ (self, model) :def attack (self, epsilon=1 , emb_name='emb.' ) :for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:if norm != 0 and not torch.isnan(norm):def restore (self, emb_name='emb.' ) :for name, param in self.model.named_parameters():if param.requires_grad and emb_name in name:assert name in self.backupif __name__ == "__main__" :for batch_input, batch_label in data:
SWA Stochastic Weight
Averaging,方法的提出者认为,训练期间得到的局部最小值 倾向于
在损失值较低的区域的边界,而不是集中在损失更低的区域中心部分。所以,Stochastic
Weight
Averaging可以通过对边界的平均,得到更好性能和更好泛化性能的模型。Git Repo
保存两套权重w, wswa;
使用循环学习率,训练w;
达到指定轮次,更新ws,\(n_{models}\) 指更新\(w_{swa}\) 时,中间间隔的轮次:
\(w_{swa} =
\frac{w_{swa}n_{models}+w}{n_{models}+1}\)
循环以上步骤,最后使用wswa,作为最终模型
有可以直接使用的工具,比较方便。~from torchcontrib.optim
import SWA~
optimizer = torch.optim.Adam(params_lr)if ...:
参考链接:
2020CCF-NER
Flat-Lattice-Transformer
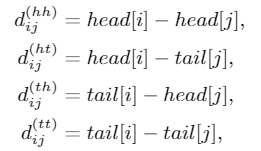
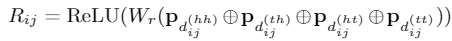
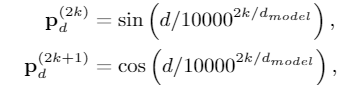
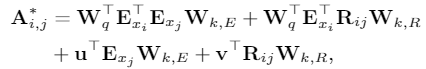
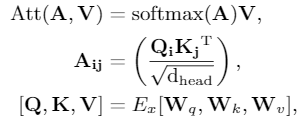
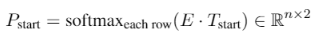
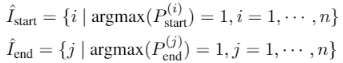
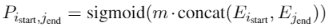
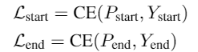
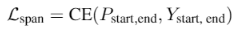
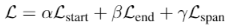


为损失函数,
为扰动的范围空间。
是输入样本的分布。