浅涉知识图谱
基本概念
“A knowledge graph consists of a set of interconnected typed entities and their attributes.”
知识图谱由一些相互连接的实体和他们的属性构成的。 是由一条条知识组成,每条知识表示为一个 SPO 三元组
技术体系简图:
SPO相关
SPO三元组:(实体,关系,实体),(实体,属性,字面量)
构建的难点之一就是,Schema设计。
设计知识图谱的结构,要构建哪些类别的实体,实体有什么属性,实体间有什么关系,关系有什么属性
SPO的背后
RDF(Resource Description Framework),即资源描述框架,其本质是一个数据模型(Data Model)。RDF形式上表示为SPO三元组。
RDF由节点和边组成,节点表示实体/资源、属性,边则表示了实体和实体之间的关系以及实体和属性的关系。
RDF的表达能力有限,无法区分类和对象,也无法定义和描述类的关系/属性。就是不能反映一个 类 的特征信息。
RDFS/OWL
用来描述RDF数据。RDFS/OWL序列化方式和RDF没什么不同,其实在表现形式上,它们就是RDF。
RDFS,即“Resource Description Framework Schema”,是最基础的模式语言。定义了类,将类进行抽象。
RDFS的表达能力还是相当有限,因此提出了OWL,Web Ontology Language。我们也可以把OWL当做是RDFS的一个扩展,其添加了额外的预定义词汇。
owl区分数据属性和对象属性(对象属性表示实体和实体之间的关系)。
OWL 使用场景:本体结构中有大量相互链接的类和属性,设计者想用自动推理机得到里面复杂的关系。需要结合基于规则的推理引擎(rule-based reasoning engine)的场合。
命名实体识别
概率图方法
有向图
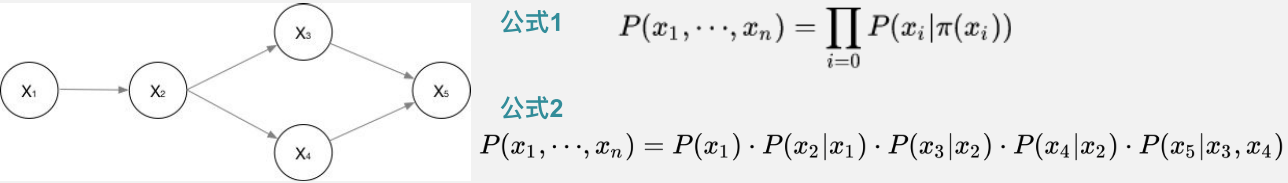
⽆向图
概率⽆无向图模型,⼜称为⻢马尔可夫随机场
它假设随机场中任意⼀一个结点的赋值,仅仅和它的邻结点的取值有关,和不不相邻的结点的取值无关。⽆向图G中任何两个结点均有边连接的结点⼦集称为团。
若C是⽆向图的⼀个团,且不能再加进任何一个G的结点使其成为更大的⼀个团,则此C为最⼤团。
联合概率可以表示为其最大团C 随机变量的函数的乘积。
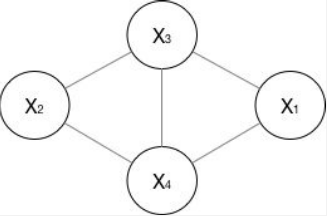
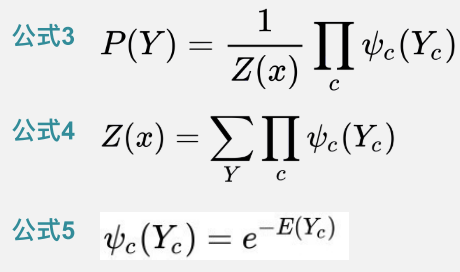
成对⻢马尔可夫性:没有直连边的任意两个节点是独立的。
局部⻢马尔可夫性:给定直连节点时,中心节点和其他节点条件独立。
全局⻢马尔可夫性:给定一个节点集合将全集划分为两个独立集合时,两个点集的任意子集,是相互独立的。
HMM
HMM是⽤用于描述由隐藏的状态序列列和显性 的观测序列列组合⽽而成的双重随机过程。
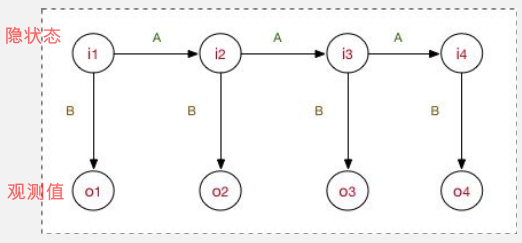
通过可观测到的数据,预测不不可观测到的状态数据。
HMM的假设⼀:⻢马尔可夫性假设。当前时刻的状态值,仅依赖于前 ⼀时刻的状态值,⽽不依赖于更早时刻的状态值。
HMM的假设⼆:⻬次性假设。状态转移概率矩阵与时间⽆关。即所 有时刻共享同⼀个状态转移矩阵。
HMM的假设三:观测独⽴立性假设。当前时刻的观察值,仅依赖于当 前时刻的状态值。
此处的问题是,预测隐状态序列(假设模型参数已经学习得到)。实例演示:
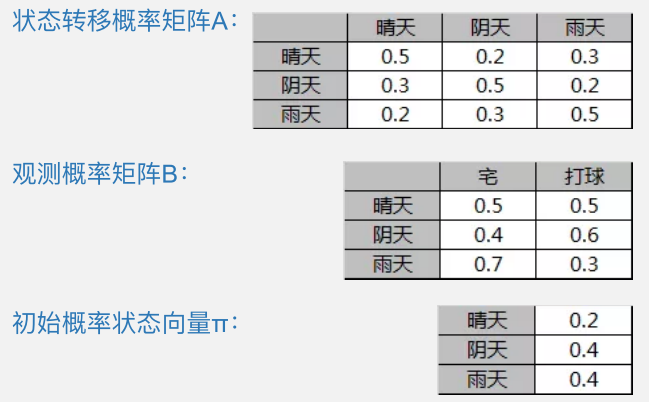
已知:
状态值集合:{晴天,阴天,⾬雨天};观测值集合:{宅,打球};
过去状态值序列:{晴晴晴阴⾬雨晴};对应观测值序列:{球宅宅球宅宅};
从历史数据学习,已得到模型参数为:
求当观测序列是{宅球宅},最有可能的天⽓状况序列?(动态规划求解概率最⼤大路路径)
求解过程:
定义:
定义在时刻t状态为i的所有单个路径(i1,i2,... it )中的概率最大值为
t+1时刻的最大概率:
再定义⼀个变量,⽤来回溯最⼤路径:在时刻t状态i的所有单个路径(i1,i2,,, it-1,it)中,概率最⼤的路路径第t-1个节点为(在t时刻选出上一个时刻的最优路径):
计算第一天
\(\delta_1\)(雨天)= \(\pi\)(雨天) * B(雨天,宅) = 0.28
\(\delta_1\)(阴天)= \(\pi\)(阴天) * B(阴天,宅) = 0.16
\(\delta_1\)(晴天)= \(\pi\)(晴天) * B(晴天,宅) = 0.1
第二天
\(\delta_2\)(雨天)= \(\max\)( [\(\delta_1\)(雨天) * A(雨天,雨天), \(\delta_1\)(阴天) * A(阴天,雨天), \(\delta_1\)(晴天) * A(晴天,雨天)]) * B(雨天,打球) = 0.042
前一时刻选择,雨天
\(\delta_2\)(阴天)= \(\max\)( [\(\delta_1\)(雨天) * A(雨天,阴天), \(\delta_1\)(阴天) * A(阴天,阴天), \(\delta_1\)(晴天) * A(晴天,阴天)]) * B(阴天,打球) = 0.0504
前一时刻选择,雨天
\(\delta_2\)(晴天)= \(\max\)( [\(\delta_1\)(雨天) * A(雨天,晴天), \(\delta_1\)(阴天) * A(阴天,晴天), \(\delta_1\)(晴天) * A(晴天,晴天)]) * B(晴天,打球) = 0.028
前一时刻选择,雨天
第三天
\(\delta_3\)(雨天)= \(\max\)( [\(\delta_2\)(雨天) * A(雨天,雨天), \(\delta_2\)(阴天) * A(阴天,雨天), \(\delta_2\)(晴天) * A(晴天,雨天)]) * B(雨天,打球) = 0.0147
前一时刻选择,雨天
\(\delta_3\)(阴天)= \(\max\)( [\(\delta_2\)(雨天) * A(雨天,阴天), \(\delta_2\)(阴天) * A(阴天,阴天), \(\delta_2\)(晴天) * A(晴天,阴天)]) * B(阴天,打球) = 0.01008
前一时刻选择,阴天
\(\delta_3\)(晴天)= \(\max\)( [\(\delta_2\)(雨天) * A(雨天,晴天), \(\delta_2\)(阴天) * A(阴天,晴天), \(\delta_2\)(晴天) * A(晴天,晴天)]) * B(晴天,打球) = 0.00756
前一时刻选择,阴天
最后,选择t3时刻最大路径,雨天。回溯结果为,{雨天,雨天,雨天}
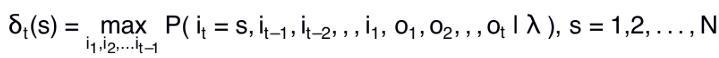

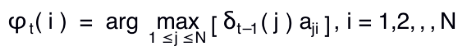
HMM的缺陷
- ⻢尔可夫性(有限历史性):实际上在NLP领域的文本数据,很多词语都是有⻓依赖的。
- 齐次性:序列列不同位置的状态转移矩阵可能会有所变化,即位置信息会影响预测结果。
- 观测独立性:观测值和观测值(字与字)之间是有相关性的。
- 单向图:只与前序状态有关,和后续状态无关。在NLP任务中,上下文的信息都是必须的。
- 标记偏置Label Bias:若状态A能够向N种状态转移,状态B能够向M种状态转移。若N<<M,则预测序列更有可能选择状态A,因为A的局部转移概率较大
MEMM最大熵马尔可夫模型
解决了观测独立问题,但是依然存在标记偏置。
最大熵(熵:分布的不确定性):
“无知比错误更可取,一个什么都不相信的人比一个相信错误的人离真理更近”
找到最优分布中,最偏向 uniform 的结果,即为最大熵的目标。
H(x)=–∑x log x是凸函数
最大熵模型的likeliihood形式为:
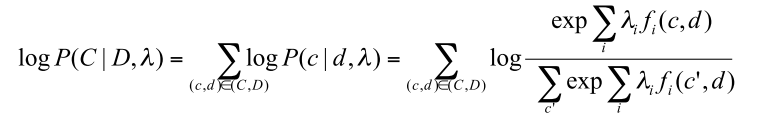
求导之后可以发现:
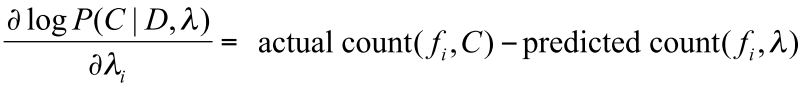
MEMM:
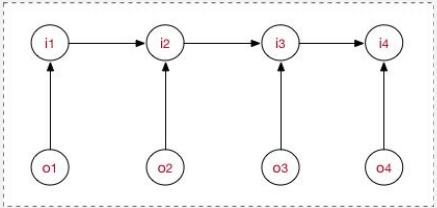
根据历史状态序列,预测当前状态,每一时间步,预测一个状态。
CRF
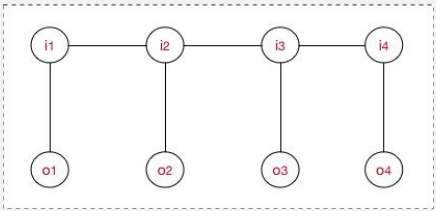
在给定随机变量序列X的情况下,随机变量Y的条件概率分布P(Y|X)构成条件随机场,即满⾜足马尔可夫性:
P(Yi| X,Y1,Y2,...Yn) = P(Yi| X,Yi−1,Yi+1)
则称P(Y|X)为线性链条件随机场。
传统的CRF定义如下:
特征函数分为两类
- 只和当前节点有关
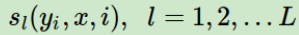
- 只和当前节点和上⼀个节点有关,局部特征函数
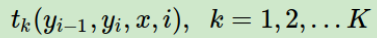
linear-CRF由 tk, λk, sl, µl 共同决定
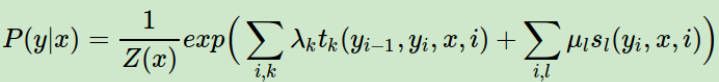
i -- 表示从0到T的序列位置;k, l -- 表示自定义的特征函数编号。
在深度学习中使用时,用深度模型代替特征函数:
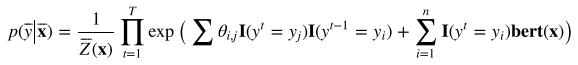
CRF相对于HMM的优点
- 规避了马尔可夫性,能够获取长文本的远距离依赖的信息
- 规避了齐次性,并且序列的 位置信息会影响预测出的状态序列
- 规避了观测独立性,观测值之间的相关性信息能够被提取
- 不是单向图,而是无向图,能够充分提取上下文信息作为特 征
- 改善了标记偏置Label Bias问题
- CRF的思路是利用多个特征,对状态序列进行预测。HMM 的表现形式使他无法使⽤多个复杂特征
CRF的缺点
- CRF训练代价大、复杂度高
- 需要人为构造特征函数,特征工程对CRF模型的影响很大
实体连接
候选实体生成: 根据输入文本中检测出的实体mention集合M,从给定知识图谱中找到可能属于M的候选实体集合m
候选实体排序: 负责对候选实体集合m中多个候选实体打分的排序, 并输出得分最高的候选实体,作为实体链接结果
关系分类简介
关系抽取: 从一个句子中判断两个entity是否有关系,一般是一个二分类问题,指定某种关系 关系分类: 一般是判断一个句子中两个entity是哪种关系,属于多分类问题。
标注工具: BRAT
BRAT是一个基于web的文本标注工具,主要用于对文本的结构化标注,用BRAT生成的标注结果能够把无结构化的原始文本结构化,供计算机处理。利用该工具可以方便的获得各项NLP任务需要的标 注语料。
方法:
- 基于规则的方法——人工模板
- 基于规则的方法——基于统计的方法
- 基于监督学习的方法——CNN/RNN
- 基于监督学习的方法——PCNN
- 半监督学习的方法——自举
- 半监督学习的方法——远程监督
基于统计的方法
- 输入关系集合中的一个
- 搜索一组实体对,满足关系
- 输入实体对,搜索包含实体对的句子,保存
- 将保存句子中的实体对,使用同一类关系模版替换
- 计算成功替换,模版匹配正确的比例,即概率,作为模版的得分(置信度)。留下得分高的模版
神经网络方法
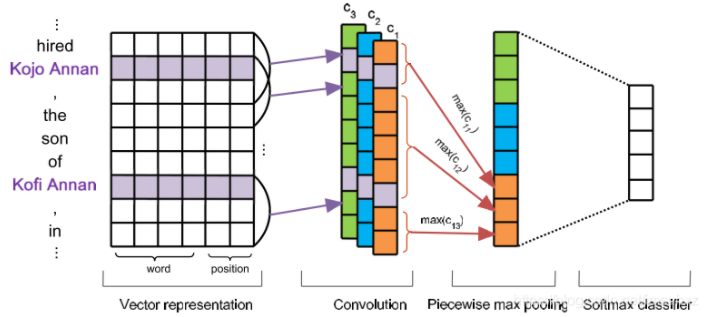
输入embedding,可加上相对位置embedding,训练分类器。
PCNN的Piecewise Convolutional,只是使用Piecewise max pooling,从实体所在位置处,分段进行pooling。
半监督
Bootstrapping
创建空的列表;
使用精心选择的种子初始化列表;
利用列表中的内容从训练语料库中查找更多内容;
给那些新发现的内容打分;把得分最高的内容加到列表中。
重复步骤3和4,直到达到最大迭代次数或者其它停止条件为止。
Snowball优化了部分的细节
定义pattern 成为<left, tag1, middle, tag2, right>; tuples 为 <tag1 , tag2>
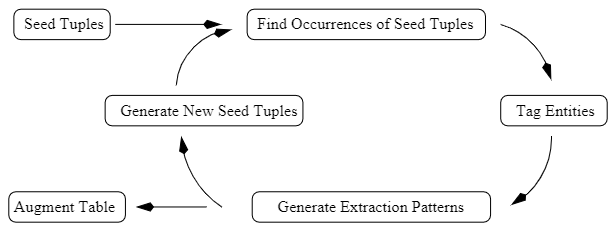
生成新pattern时,评估其与已有pattern的相似性,取一个阈值之上的,加入pattern集合。
tuples要经过可信度计算,选择可信度高的留下,计算方法看论文或者blog吧。
远程监督
将已有的知识对应到丰富的非结构化语料中从而生成大量的训练数据。知识来源:人工标注、现有的知识库、特定的语句结构。
Distant supervised 会产生有大量噪音或者被错误标注的数据,直接使用supervised的方法进行关系分 类,效果很差。
知识表示Embedding
TransE
TransE,⼀种将实体与关系嵌⼊到低维向量空间中的简单模型 。该模型已经成为了知识 图谱向量化表示的 baseline,并衍⽣出不同的变体。原理简述:

h,t为实体向量,r为关系向量。
以L2 距离为例,梯度的计算相对⽐较简单,⽬标函数变为
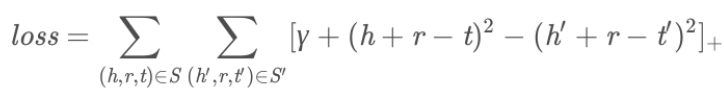
求解导数:
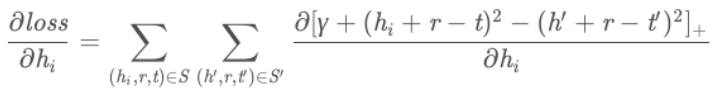
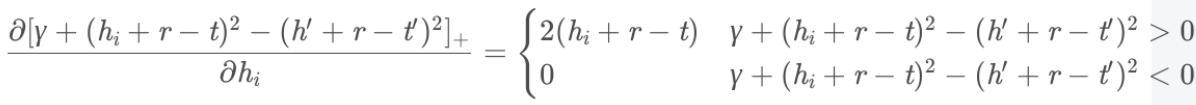
完整算法:

评测方法:
在测试时,以⼀个三元组为例,⽤语料中所有实体替换当前三元组的头实体计算距离d(h ′+l,t),将结果按升序排序,⽤正确三元组 的排名情况来评估学习效果(同理对尾实体这样做)。(若替换到在训练集中的三元组,可以选择 删掉)
度量标准选择hits@10和mean rank,前者代表 命中前10的次数/总查询次数,后者代表 正确结果排名之和/总查询次数
训练速度快、易于实现。另外,可以将word2vec和TransE一起融合训练,此处不作展开。
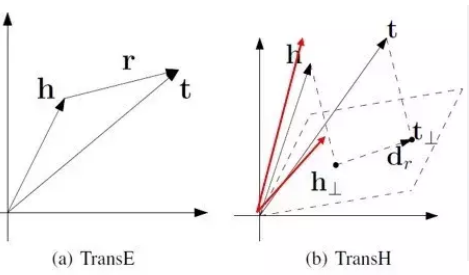
TransH
虽然 TransE 模型具有训练速度快、易于实现等优点,但是它不能够解决多对⼀和⼀对多关系的问题。以 多对⼀关系为例,固定 r 和 t,TransE 模型为了满⾜三⻆闭包关系,训练出来的头节点的向量会很相似。⽽TransH是⼀种将头尾节点映射到关系平⾯的模型,能够很好地解决这⼀问题。
对于多对⼀关系,TransH 不在严格要求 h+r-l=0,⽽是只需要保证头结点和尾节点在关系平 ⾯上的投影在⼀条直线上即可。
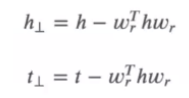
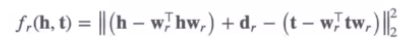
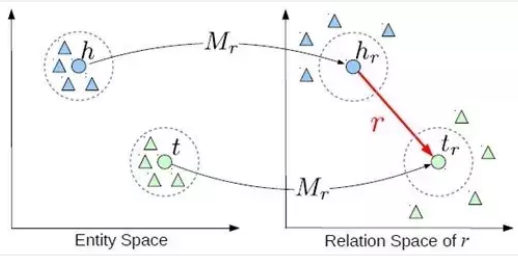
TransR
TransE 和 TransH 都假设实体和关系嵌⼊在相同的空间中。然⽽,⼀个实体是多种属性的综合体,不同关 系对应实体的不同属性,即头尾节点和关系可能不在⼀个向量空间中。
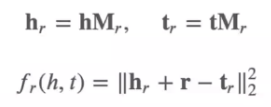
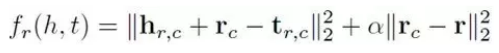
TransD
TransR同样有它的问题,首先对于一种关系,它的头实体和尾实体使用同样的变换矩阵映射到关系空间,而头实体和尾实体往往是完全不同类的实体,也应该使用不同的方法进行映射。
TransD模型对每个实体或关系使用两个向量进行表示,一个向量表示语义,另一个(用下表p表示)用来构建映射矩阵。
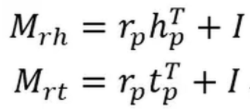
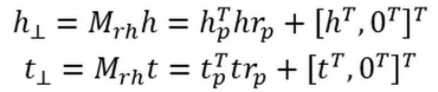
问答应用
基于知识图谱的问答KBQA
基本流程:
⾃然语⾔查询-->意图识别(Intention Recognition)-->实体链指(Entity Linking)+关系识别(Relation Detection) --> 查询语句拼装(Query Construction)-->返回结果选择(Answering Selection)
意图识别(Intention Recognition):预先准备好意图模板,可以通过相似度来匹配,也可以通过机器学习⾥的 分类问题来解决,这个是所有问答系统都要⾯临的问题。
实体链指(Entity Linking)+关系识别(Relation Detection):将查询语句中出现的实体和关系映射到知识图谱⾥,本质是⼀个NER问题,只是需要将NER结果进⼀步链接到图谱。
查询语句拼装(Query Construction):需要根据底层知识图谱的查询语⾔,拼装成对应的query来查询(sparq 等),最简单的⽅法就是预先定义好查询模板,根据之前解析出来的(意图,实体,关系)填进模板查询即可。
返回结果选择(Answering Selection):图谱查询之后的结果可能存在多个,需要选择⼀个最合适的答案,可 以预先指定排序规则去选择答案。
参考:
实例:NL2SQL比赛第三名方案,待学习
基于知识表示的问答KEQA
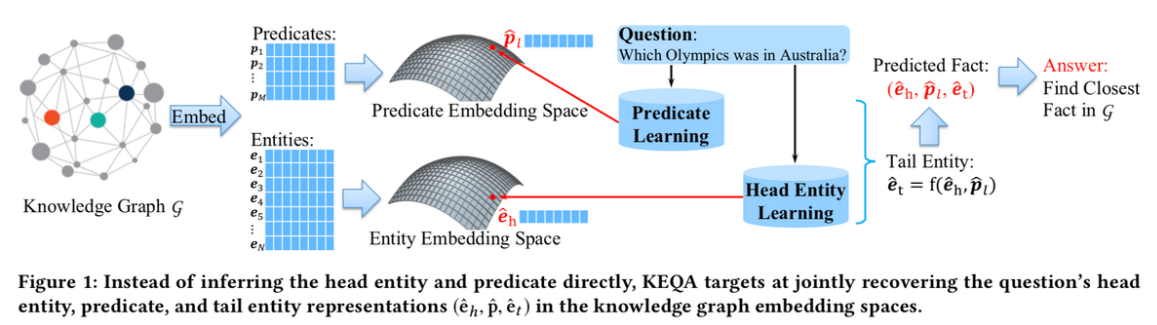
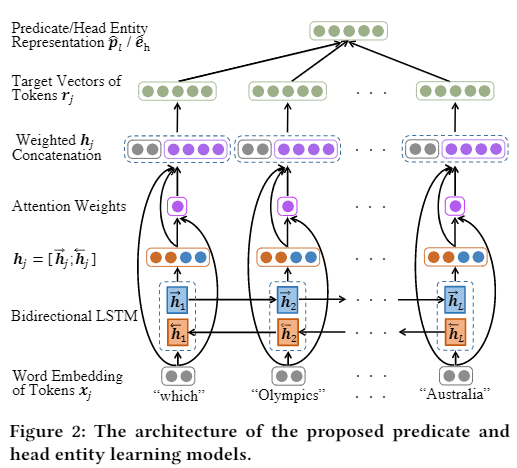
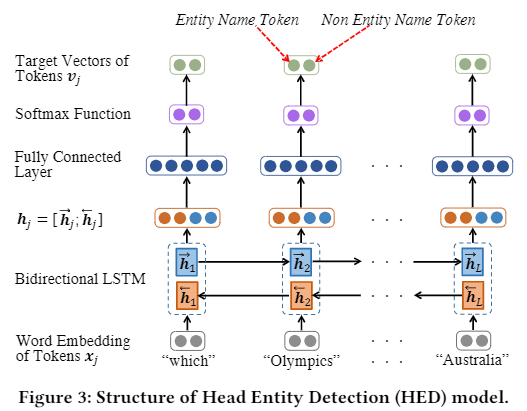
KEQA的目标不是直接推断头部实体和谓词,而是联合恢复知识图嵌入空间中问题的头部实体、谓词和尾部实体表示(eh, p, et)。分别训练两个模型,一个学习 谓词p 和 实体e 的表示,一个识别问题中到的Head实体。如下面两个图所示。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!