SimCSE-文本对比学习
文本对比学习不同于图像的一点,就是增广方式。文本随机删除、乱序、替换,好像都可以,但是有没有道理,效果能有多大提升,都不那么清楚。这方面也没有比较公认处理方法流程。
论文 SimCSE (Git),提出一种简单的对比学习方法,直接在BERT类模型之上,使用设计的对比学习损失进行fine tune,取得了比较好的效果。
方法
首先在图像领域使用的对比学习损失公式是
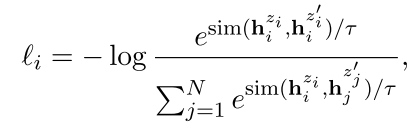
本文提出的方法,不使用文本增广生成对比样本,而是通过随机Dropout模型的intermediate representations,得到一组不同mask下的对比学习样例,作为正样本。而不是来自同一个原文本的 intermediate representations 组成多组负样本。
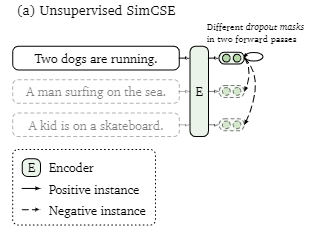
两个绿圈正是不同dropout下的一组正样本。思路确实挺简单的,但是别人做出来了,还整理得有条理。唉,我又搞得了什么鬼贡献呢。
论文结果,在取0.1 dropout rate时,无监督句子向量的效果最好。STS-B任务的Spearman`s correlation 达到 79.1。
论文还在有监督条件下,进程了实验。在NLI数据集上,加入两个源文本 同义(entailment)、中立(neutral)、反义(contradiction) 三种情况的监督信息。
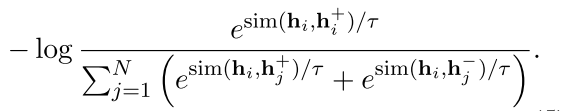
正例来自同义的句子对,负例来自不同含义的句子。同时使用严格反义的句子对作为负例时,效果会有提升。
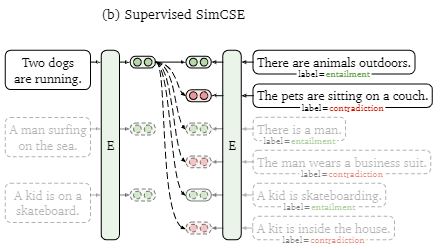
这里没有使用不同dropout,毕竟已经有正负样本标签了。作者也做了实验,使用dropout增广并没有带来提升。
对比学习效果评价
在看Bert Flow时,了解到向量表示的各向异性很重要,尤其在语义相似性任务中,对相似性指标影响很大。另外,直觉来讲,对比学习目的就是将同类相似的聚在一起,同时将向量分布尽量保持均匀,以保留更可能多的信息。
好的学习效果,应该保证 结果的对齐性和均匀性(Alignment and uniformity)。原论文推导较多,结论就是,对比学习的损失,可以转换为对齐损失和均匀损失之和。过程挺复杂的,这里并不关心(挺麻烦的)。
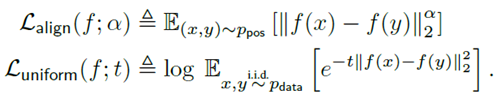
论文给出了代码:

注意,以上计算中的x和y都是经过 L2 normalize 的向量。
原论文做了很多实验,发现要同时将对齐损失和均匀损失达到最优,很难,至少在作者的实验中,是达不到的。
SimCSE中,将这两个损失,作为metrics使用,评价sentence embedding的对比学习效果。两个指标,都是尽量小更好,但是很难保证同时最优。
经验
无监督句向量训练,只使用随机Dropout,得到两个representations 作为正例,比在源文本上进行随机删除替换等操作的效果更好。
有监督条件下,不需要随机Dropout生成样本表达,利用监督信息就能得到很好的学习效果。
训练BERT base时,使用256或者512 batch size效果相对较好。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!