Joint Extraction of Entities and Relations 2020
CasRel
实体识别和关系分类一体化,使用一个model解决两个问题。优势在于,通过两个任务的相关性,设计model,减少两阶段预测中的级联误差。虽然,也有两阶段模型实际效果可以很好。
除了解决级联误差,还需要解决什么问题?
- Overlapping relations:一个实体可以出现则同一文本中的多个关系中。
- Nested relations:不同的三元组可能包含或共享嵌套实体。
| Texts | Triplets | |
|---|---|---|
| Normal | [The United States] President [Trump] will meet [Xi Jinping], the president of [China]. | (The United States, president,
Trump) (China, president, Xi Jinping) |
| Single Entity Overlapping | Two of them, [Jeff Francoeur] and [Brian McCann], are from [Atlanta]. | (Jeff Francoeur, live in,
Atlanta) (Brian McCann, live in, Atlanta) |
| Entity Pair Overlapping | The new mayor of [New York City] [De Blasio] is native-born. | (New York City,
mayor, De Blasio) (De Blasio, born in, New York City) |
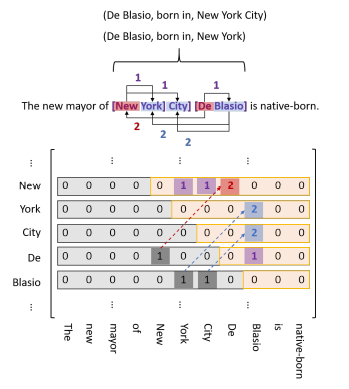
| Nested | The new mayor of [[New York] City] [De Blasio] is native-born. | (De Blasio, live in, New
York City) (De Blasio, live in, New York) (New York, contains, New York City) |
同时,还存在的问题有:预测标签的不平衡,相同实体出现不同关系时model难以拟合。
framework
CasRel是一种framework,将关系预测从标注分类转化为一个隐式变换,参与模型训练: \[ f(s, o) \rightarrow r \] 本来是subject + object推断relation,变化为: \[ f_r(s) \rightarrow o \] 将relation建模成一种function。
将likelihood变成以下形式:
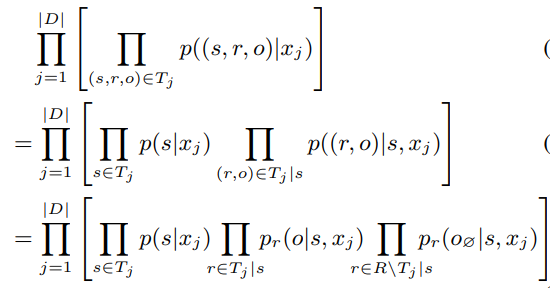
模型整体架构
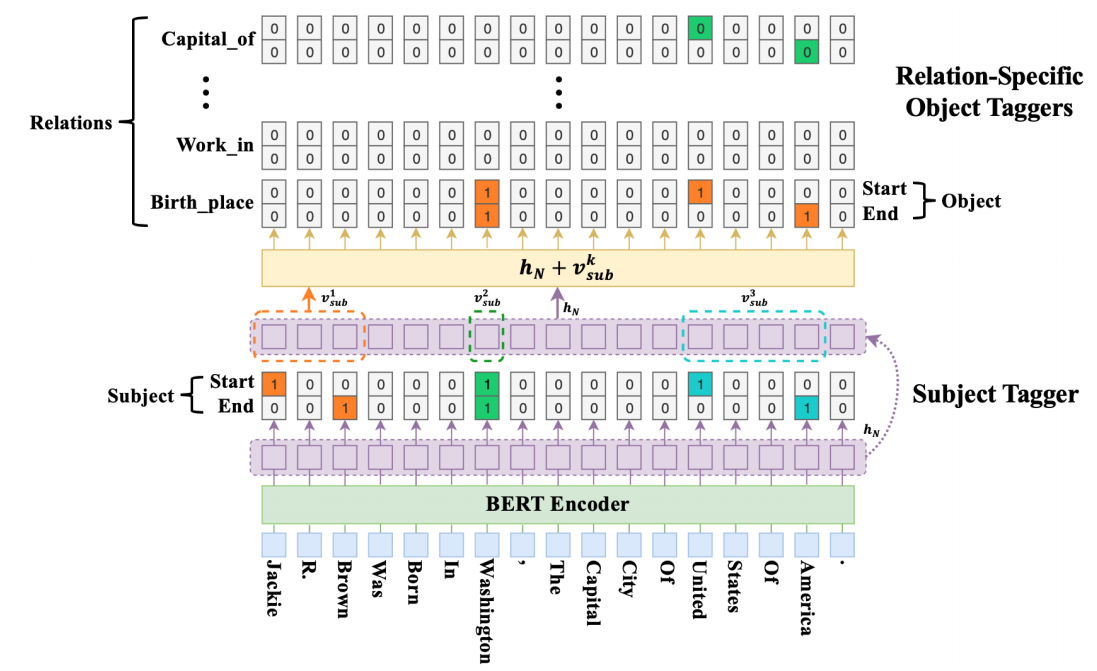
模型在多个关系抽取任务上,效果提升明显。
TPlinker
TPlinker是不同于现有模型的一种一体式关系抽取模型。解码方式独特。
- 通过实体边界词,区分嵌套实体:New York City -> (New, City), New York -> (New, York)
- 通过实体边界,分解三元组:(De Blasio, live in, New York City) -> (De, live in, New) and (Blasio, live in, City)
两种常见的处理 relation overlapping 的模式:
都同时存在两个问题:
- 暴漏偏差(exposure bias) :指在训练阶段是gold实体输入进行关系预测,而在推断阶段是上一步的预测实体输入进行关系判断;导致训练和推断存在不一致
- 嵌套实体(nested entities):并没有有效处理嵌套实体关系。
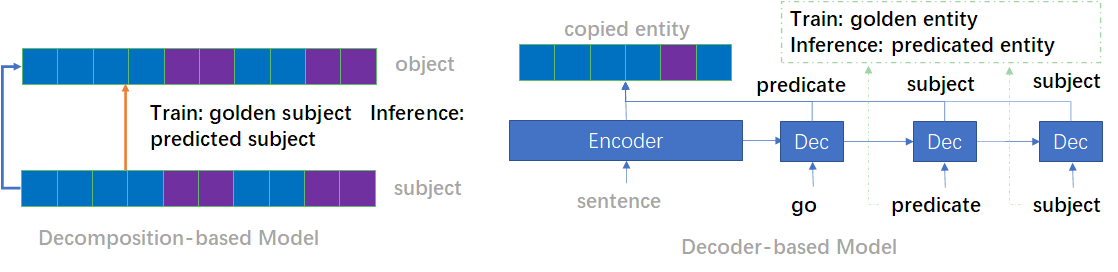
TPlinker的标注方式
首先对不同的关系,分别进行标注。每种关系的标注方式相同。
三类标记:
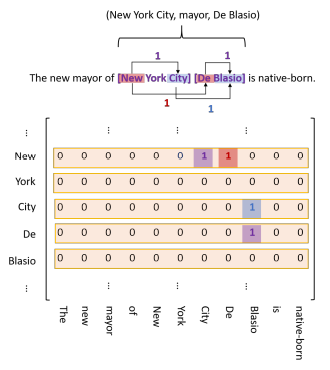
紫色标记:单个实体的头尾对应关系。和关系类型无关。shape: len(text) * len(text)
红色标记:对应 subject和object 的 start对应标记。每种关系一个单独标记矩阵。shape: R * len(text) * len(text)
蓝色标记:对应 subject和object 的 end对应标记。每种关系一个单独标记矩阵。shape: R * len(text) * len(text)
同时,红色标记和蓝色标记,在len(text) * len(text)的矩阵中,存在两个对称的标记,比如(New, De)与 (De, New)。为了提高效率,将下三角部分映射到上三角部分,同时值变成2。
模型为:
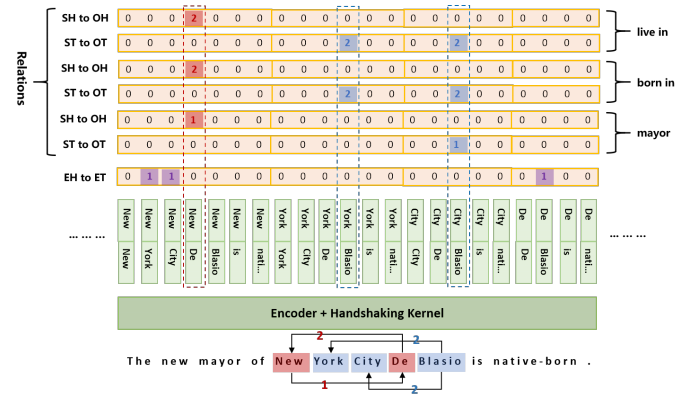
图中 Handshaking Kernel,就是将 标记矩阵展开得到的一维编码。token pair 遍历了所有可能的 对应关系。图中S -- subject;O -- object; H -- head; T -- tail; E -- entity
通过这些标记,训练模型计算损失,token pair的encoder output拼接在一起,输入softmax,每个关系类型都有一个softmax。
解码过程
- 预测模型计算结果
- 结果EH-to-ET可以得到句子中所有的实体,EH的 token idx作为key,EH-to-ET的entity作为value,存入 D 中,得到可选实体;
- 开始遍历 不同关系;
- 结果SH-to-OH可以得到某种关系可选的 head 对应关系,取这些head index,从 D 中,取出对应实体对 token pair 存于 D2;
- 结果ST-to-OT可以得到某种关系可选的 tail 对应关系,将这个对应关系的 token pair 存入 E;
- 遍历D2,并检查 每一个 D2中的 token pair 的 tail 是否存在于 E 中,若存在,那么输出 该关系下的该三元组信息。
More
实体对输出的embedding表示是直接 concatenate,那么如果两个实体的context相似,那么理论上会影响预测效果。
由于要预测 N 个词中选 2 的排列个 pair,所以对于长文本,代价会很大。
Two-are-better-than-one
统一NER和RE任务到一个表格标记预测任务。
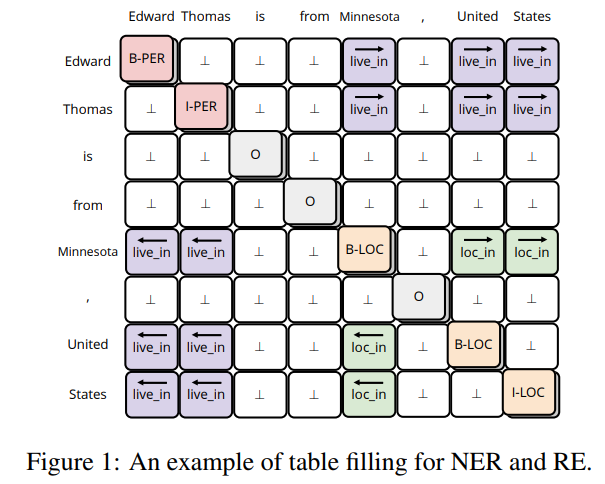
标记形式很直观。只是这在14年就已经有这种方法的尝试了。这篇论文作者是对其进行了改进。
除了一些关系抽取任务常见的问题,这种标记方式还有一个问题:
- 现有的基于Table-Filling方法,会将表结构转化成一个序列结构,表结构的标记方式直接退化。
结构设计
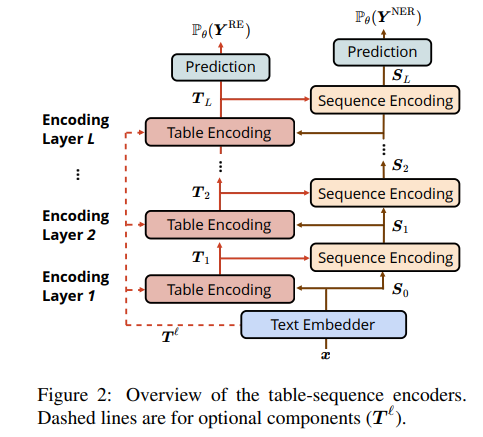
首先是 Text Embedding:Glove词向量、LSTM字符向量和BERT词向量的共同构成。
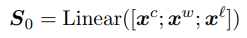
Table Encoder:学习表格中每个位置的向量表达,shape: len(text) * len(text)。表格第 i 行第 j 列的向量表示,与句子中的第 i 个和第 j 个词相对应。
使用 MD-RNN 融合表格中上下左右的信息。接收 Sequence Encoder 编码的 当前 第 i 、第 j 个词的向量表示。
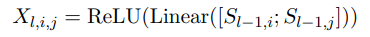
但是,论文实验发现,不必计算四组,只需要两组,就能达到几乎无损的效果。只计算 a 和 c。
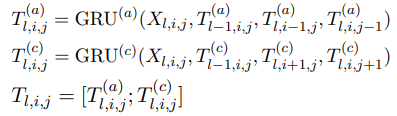
Sequence Encoder:Sequence Encoder的结构与Transformer类似,不同之处在于将Transformer中的scaled dot-product attention 替换为 table-guided attention。
原 transformer 的 attention :
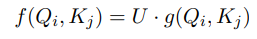
变为:
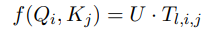
直接使用 \(T_{l,i,j}\)节省了计算量,同时交互两个部分信息。
Pre-trained Attention Weights:利用预训练的 BERT 中每一层的 attention 信息,得到 \(T^l\) ,联合 S 构成MD-RNN的初始输入 。

预测结果表示为:
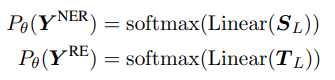
表格中对称位置,在预测时直接求和,得到一个关系的得分。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!