Self-supervised methods note
JEM
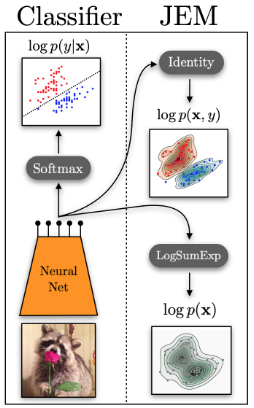
建模联合概率,factorize为监督部分和非监督部分。同时论文指出从y开始factorize的话,效果会下降。
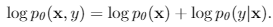
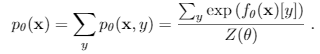
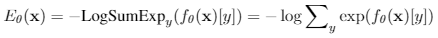
energy部分使用 Stochastic Gradient Langevin Dynamics (SGLD)对生成数据采样,最小化其energy
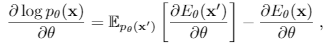
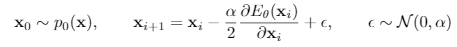
framework:
达到效果:提高了 calibration(输出与真实分布具有一致性), robustness, 和out-of-distribution detection方面的性能。
问题:训练自然会变慢(CIFAR10一个epoch为半个小时),另外就是不稳定,SGLD采样使用随机数据开始。
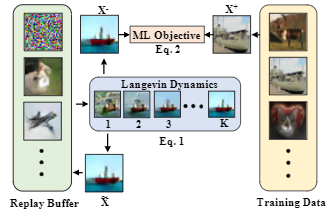
JEM采样方式来自 Implicit Generation and Modeling with EBM
Buffer Sample
igebm-pytorch, link,Google
先比于VAE和GAN,是一种根据energy采样的隐式采样,使用一个主网络,可以将生成的限制和目标构建成损失函数。但是生成样本分布需要更多的计算迭代次数。
energy based采样主要是高维数据采样困难。真实图片分布在high energy区域,噪声图片分布在low energy区域。
方法:
- 随机输入开始
- 使用模型输出 + SGLD迭代采样出sample i
- 将更新过的sample i重新写入buffer
- 2、3步迭代 K 次。K不能太小。论文中60,JEM 20
SGLD:
SupContrast
contrastive learning一般的方式是,先数据增广,然后通过模型识别出来自同一张图的输入,将不是来自同一张图的输入的相似度变小。
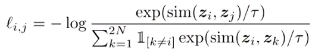
Supervised Contrastive Learning将识别对象变为同一类图片,而不是同一张图片。
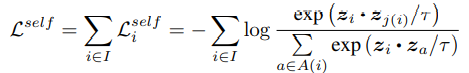
损失函数定义为:
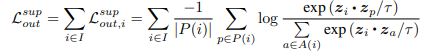
论文中还有另一种形式的L,但是效果不好。
通过引入标签数据,计算同一类图片的相似度。在计算损失时,处理同一类图片方法如下
1 | |
模型训练分为两个阶段。如果只是训练一个encoder,只需要第一阶段。若是要进行分类任务,需要固定encoder训练第二阶段分类器。
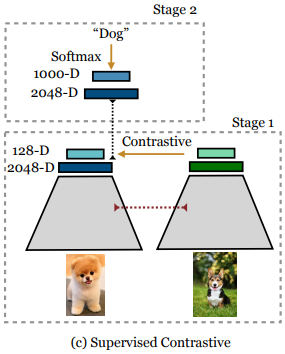
实验结果:模型对超参数的敏感性降低,使用Supervised Contrastive Loss能够提升分类准确率(论文中在Imagenet等多个数据集上进行了实验)。
Hybrid Discriminative-Generative
通过对比学习contrastive learning,混合监督与非监督一起训练。和Supervised Contrastive Learning中的encoder框架不同,没有两个编码的 contrastive 计算。从
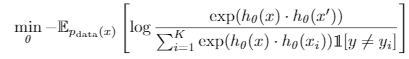
变为:
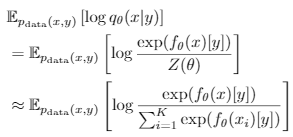
只有一个f(x)编码,和 label y。
这个和 cross entropy 有点像。但是数据来源不同,这里数据是来自K大小的 normalization samples,也是来自SGLD方法中设计的buffer。
这个方法也是针对loss进行变化:
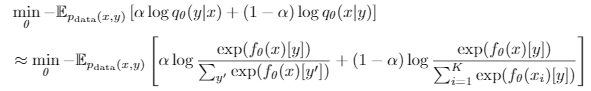
计算两个部分的cross entropy loss。

论文结果,相比于JEM,在CIFAR10上的效果,有一定提升
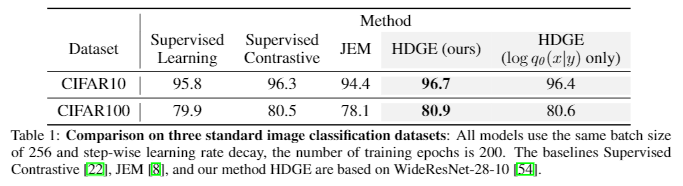
提高了 calibration, robustness, 和out-of-distribution detection方面的性能。
同时K越大,效果越好。“有钱人的游戏”。
Momentum Contrast
PyContrast:pytorch implementation of a set of (improved) SoTA methods using the same training and evaluation pipeline.
首先contrastive loss 计算的一般框架:
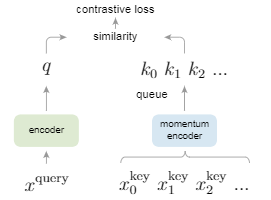
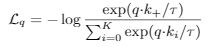
就是 k+1个softmax分类器。
目前的训练方式:
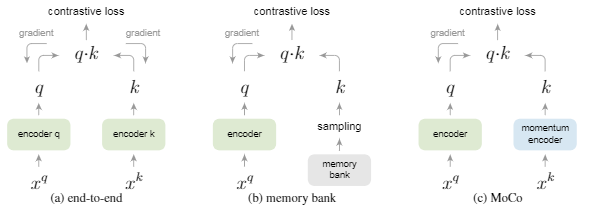
- end to end:输入一个batch,进行数据增广,然后优化来自同一张图片的相似度。如果有多个类,那么一个batch的数据,覆盖的类是有限的。
- memory bank: 使用一个encoder,构建memory bank(样本的vector表示集合),随机抽取batch size个数据,与query正例计算loss。然后再更新memory bank中的样本表达数据。如此循环。
- MoCo:使用一个大小为k的queue,出队batch size个数据经过 momentum encoder,与query正例计算loss。然后使用 encoder的参数,以一定 momentum 更新 momentum encoder参数。重新入队batch size个样本。
momentum 更新,论文实验发现,m应该设置为一个很接近1的数,比如0.9999:
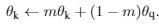
MoCo伪代码:

经过MoCo得到一个预训练模型 encoder,使用就类似 BERT 之类的模型。
接一个简单 Linear classifier 就可以达到接近监督训练模型的效果。
SimCLR
在MoCo之上的改进。两个点:
- 数据增广加一倍,一个图片会有两个 aug(x) 。
- 计算NCE时,使用Cosine Similarity,而不是MoCo中的 inner product。
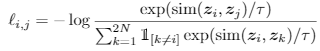
增广方法使用了:

framework:
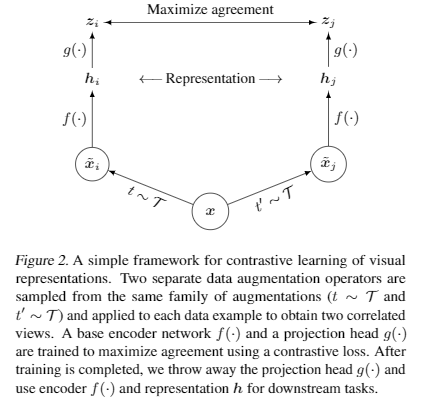
模型结构:
使用encoder时,如果使用预训练的Resnet之类在ImageNet训练的模型,输出部分重新设计,不需要转到1000类,直接输出模型表征经过avgpool + fc 之后的结果,即 图中 h。
h 之后还增加 g(x) DNN层变换。

其他变化:
- 放弃 MoCo的 queue,也不用 memory bank,直接用很大的batch size....
- 使用LARS优化器
- 32到128个GPU训练
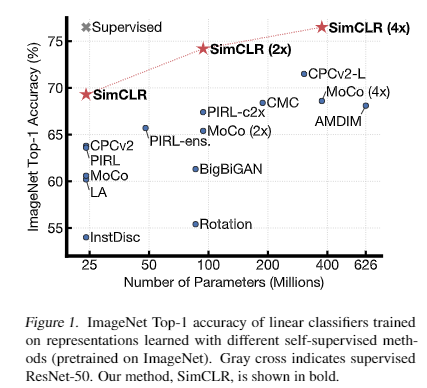
论文给出的self-supervised模型+linear classifier在ImageNet上的Top-1 accuracy.
Bootstrap your own latent
结合SimCLR和MoCo:
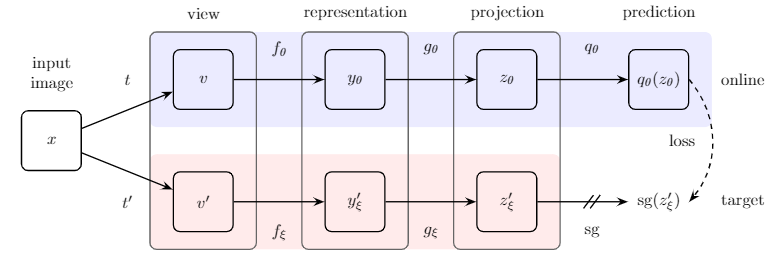
结构还是SimCLR的结构,只是一个分支在这里称为online,一个称为target。
使用MoCo的 momentum 更新 momentum encoder参数的方法,更新target网路参数。
target部分不计算bp。
重新定义损失为mean squared error形式,不需要构造负样本对:
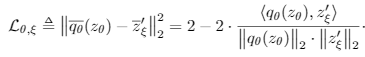
结构:
当然,又是一次提升:
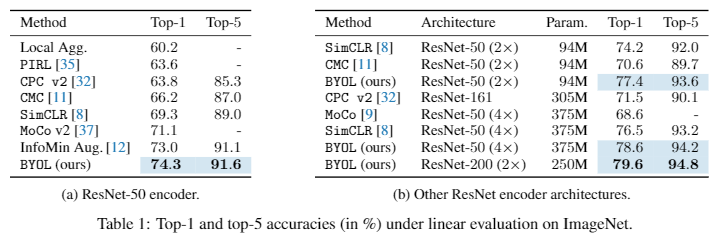
同时,BYOL对batch的敏感性比SimCLR低一些。
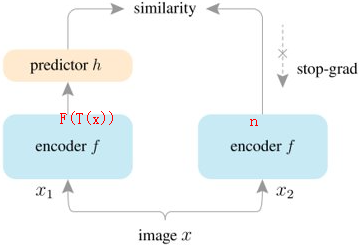
Simple Siamese: simpler & better
结合了BOYL和SimCLR,将Siamese结构加入模型,得到一个更neat的设计。
- 删掉BOYL的 momentum encoder。
- 不用构造SimCLR中的negative pairs。
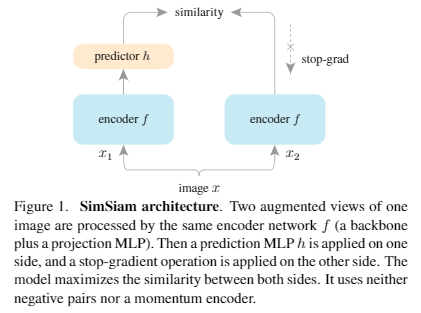
encoder对两个aug(x)计算hidden representation:
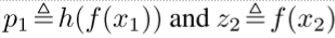
计算损失函数:
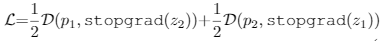
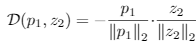
伪代码:

stopgrad部分视为一个constant输入。
其他设计:
- 优化器SGD + 0.9 momentum动量 + 0.0001 的 weight decay
- 不再需要很大的batch size,batch size 512即可
消融实验结果:
- lr不要要decay,效果最好
- batch size最大512即可
- loss设计为 cosine 形式更好,在hidden层和predict层之前使用BN效果最好
- Loss的对称计算形式提升了效果。
SimSiam不再需要negative sample pairs ,large batches ,和momentum encoders。终于找到一个简洁而有效的model。当然,后浪依然会有。
Why stop-gradient?
论文假设只是一个EM模型:
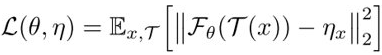
那么问题转化为:
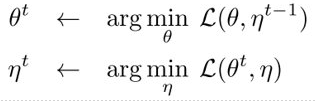
假设从 \(\eta\) 网络输出就假设为当前期望估计。更新\(\theta\)就是在计算最优化损失。所以,计算期望时,自然是不更新\(\theta\)的。
这里predictor的作用也是假设loss是在两侧 expectation 上进行计算的,这只是假设,严格证明没有。
这因为EM显示的合理性,所以在 stop-gradient 时,模型能够收敛到一个好的结果。而如果不进行 stop-gradient,训练反而会变得不稳定。
Contrastive Learning with Adversarial Examples
理论偏研究,没有开源实现。
基于SimCLR框架,选择能最大化差异的样本,然后再使之相似性损失最小化。
将SimCLR损失写成:
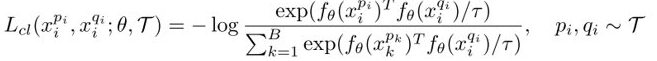
然后固定一个增广样本输入,然后找差异最大的另一个:
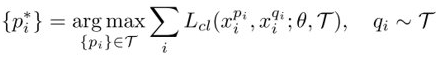
计算扰动:
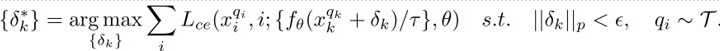
得到对抗样本:
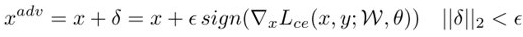
计算损失(16):
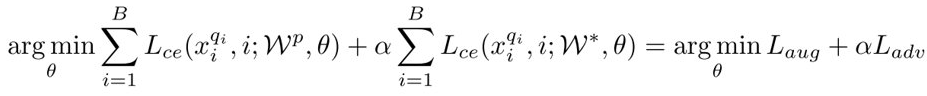
算法设计:

计算 \(W^*\)(15):
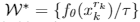
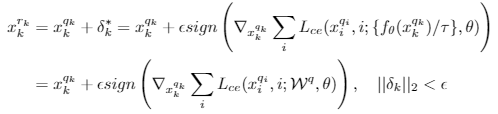
More
Adversarial Examples Improve Image Recognition
提升的基本思想,加入对抗样本,联合原数据进行训练
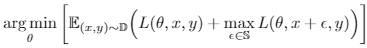
max部分为求得最大化差异的对抗样本损失。
但是,实际效果并不好,因为原数据与对抗样本的分布不匹配。所以提出,两个BN分布处理原数据和对抗样本。
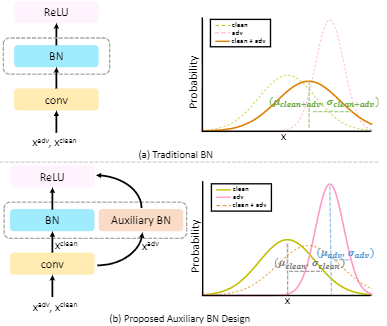

然后,在预测时,只使用主BN层。
当模型越大,效果提升越明显。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!