from bertopic import BERTopic import pandas as pd from sentence_transformers import SentenceTransformer import sklearn.manifold import umap import numpy as np import pandas as pd import random from nltk.corpus import stopwords
random.seed(42)
from bokeh.io import output_file, show from bokeh.models import ColumnDataSource, HoverTool, LinearColorMapper from bokeh.palettes import plasma, d3, Turbo256 from bokeh.plotting import figure from bokeh.transform import transform import bokeh.io bokeh.io.output_notebook()
import bokeh.plotting as bpl import bokeh.models as bmo bpl.output_notebook()
读取数据
1 2 3 4 5 6 7 8 9 10 11 12
test = pd.read_csv('test.csv') train = pd.read_csv('train.csv')
# def preprocess_tweet_data(data,name): # # Lowering the case of the words in the sentences # data[name]=data[name].str.lower() # # Code to remove the Hashtags from the text # data[name]=data[name].apply(lambda x:re.sub(r'\B#\S+','',x)) # # Code to remove the links from the text # data[name]=data[name].apply(lambda x:re.sub(r"http\S+", "", x)) # # Code to remove the Special characters from the text # data[name]=data[name].apply(lambda x:' '.join(re.findall(r'\w+', x))) # # Code to substitute the multiple spaces with single spaces # data[name]=data[name].apply(lambda x:re.sub(r'\s+', ' ', x, flags=re.I)) # # Code to remove all the single characters in the text # data[name]=data[name].apply(lambda x:re.sub(r'\s+[a-zA-Z]\s+', '', x)) # # Remove the twitter handlers # data[name]=data[name].apply(lambda x:re.sub('@[^\s]+','',x))
defpreprocess(data): excerpt_processed=[] for e in data['excerpt']: # find alphabets e = re.sub("[^a-zA-Z]", " ", e) e = re.sub(r'\s+', ' ', e, flags=re.I)
# # convert to lower case # e = e.lower()
# tokenize words e = nltk.word_tokenize(e) # remove stopwords e = [word for word in e ifnot word.lower() in set(stopwords.words("english"))] # lemmatization lemma = nltk.WordNetLemmatizer() e = [lemma.lemmatize(word) for word in e] e=" ".join(e)
excerpt_processed.append(e)
return excerpt_processed
使用sentence bert计算文档向量
1
model = SentenceTransformer('stsb-distilbert-base')
id
1
embeddings = model.encode(texts)
降维 t-SNE 与 umap
t-SNE保留数据中局部结构。
UMAP保留数据中的本地和大部分全局结构。
UMAP比tSNE要快得多,当面对更多数据、更高维数据时
1 2
color_mapper = LinearColorMapper(palette='Plasma256', low=min(targets), high=max(targets)) out = sklearn.manifold.TSNE(n_components=2).fit_transform(embeddings)
p = figure(plot_width=800, plot_height=800, tools=[hover], title="First Look at the Data") p.scatter('x', 'y', size=10, source=source, legend='dset', color={'field': 'targets', 'transform': color_mapper}, marker=bokeh.transform.factor_mark('dset', MARKERS, SETS),)
bpl.show(p)
Kmeans 观察数据
1 2 3 4 5
from sklearn.decomposition import PCA from sklearn.cluster import MiniBatchKMeans from sklearn.metrics import silhouette_samples, silhouette_score import matplotlib.pyplot as plt import matplotlib.cm as cm
idx = np.random.choice(range(pca.shape[0]), size=320, replace=False) label_subset = labels[max_items] label_subset = [cm.hsv(i/max_label) for i in label_subset[idx]]
model = BERTopic(language="english", min_topic_size=20) topics, probs = model.fit_transform(texts)
1 2 3 4 5 6 7 8
topic_words = ['-1: outlier'] for i in range(len(set(topics))-1): tpc = model.get_topic(i)[:8] words = [x[0] for x in tpc] tw = ' '.join([str(i) + ':'] + words) topic_words.append(tw)
os.environ['MALLET_HOME'] = '/content/mallet-2.0.8' mallet_path = '/content/mallet-2.0.8/bin/mallet'# you should NOT need to change this
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
import gensim import gensim.corpora as corpora from gensim.utils import simple_preprocess from gensim.models.wrappers import LdaMallet from gensim.models.coherencemodel import CoherenceModel from gensim import similarities
import os.path import re import glob
import nltk nltk.download('stopwords')
from nltk.tokenize import RegexpTokenizer from nltk.corpus import stopwords
defpreprocess_data(doc_set,extra_stopwords = {}): # adapted from https://www.datacamp.com/community/tutorials/discovering-hidden-topics-python # replace all newlines or multiple sequences of spaces with a standard space doc_set = [re.sub('\s+', ' ', doc) for doc in doc_set] # initialize regex tokenizer tokenizer = RegexpTokenizer(r'\w+') # create English stop words list en_stop = set(stopwords.words('english')) # add any extra stopwords if (len(extra_stopwords) > 0): en_stop = en_stop.union(extra_stopwords)
# list for tokenized documents in loop texts = [] # loop through document list for i in doc_set: # clean and tokenize document string raw = i.lower() tokens = tokenizer.tokenize(raw) # remove stop words from tokens stopped_tokens = [i for i in tokens ifnot i in en_stop] # add tokens to list texts.append(stopped_tokens) return texts
defprepare_corpus(doc_clean): # adapted from https://www.datacamp.com/community/tutorials/discovering-hidden-topics-python # Creating the term dictionary of our courpus, where every unique term is assigned an index. dictionary = corpora.Dictionary(doc_clean) dictionary = corpora.Dictionary(doc_clean)
dictionary.filter_extremes(no_below=5, no_above=0.5) # Converting list of documents (corpus) into Document Term Matrix using dictionary prepared above. doc_term_matrix = [dictionary.doc2bow(doc) for doc in doc_clean] # generate LDA model return dictionary,doc_term_matrix
# topic_words = ldamallet.show_topics(num_topics=number_of_topics,num_words=5) # topic_words = [x[1] for x in topic_words]
topic_words = [] for i in range(number_of_topics): tpc = ldamallet.show_topic(i, topn=7, num_words=None) words = [x[0] for x in tpc] tw = ' '.join([str(i) + ':'] + words) topic_words.append(tw)
1
topic_words
1 2 3 4 5 6 7 8 9 10 11 12
# show result topics_docs = list() for m in ldamallet[doc_term_matrix[:1000]]: topics_docs.append(m)
x = np.array(topics_docs[:1000]) y = np.delete(x,0,axis=2) y = y.squeeze()
best_topics = np.argmax(y, axis=1) # 结果是一个分布 topics = list(best_topics) topics = [topic_words[x] for x in topics]
import numpy as np import pandas as pd import jieba import umap import hdbscan from sentence_transformers import SentenceTransformer from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similarity from tqdm import tqdm import matplotlib.pyplot as plt
#### c-TF-IDF defc_tf_idf(documents, m, ngram_range=(1, 1)): my_stopwords = [i.strip() for i in open('stop_words_zh.txt',encoding='utf-8').readlines()]
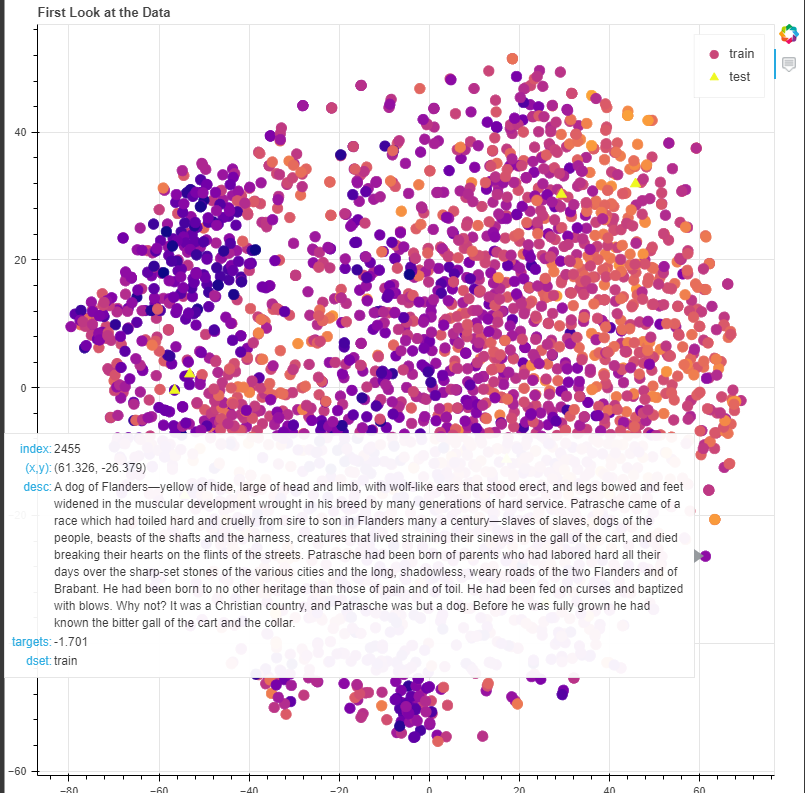
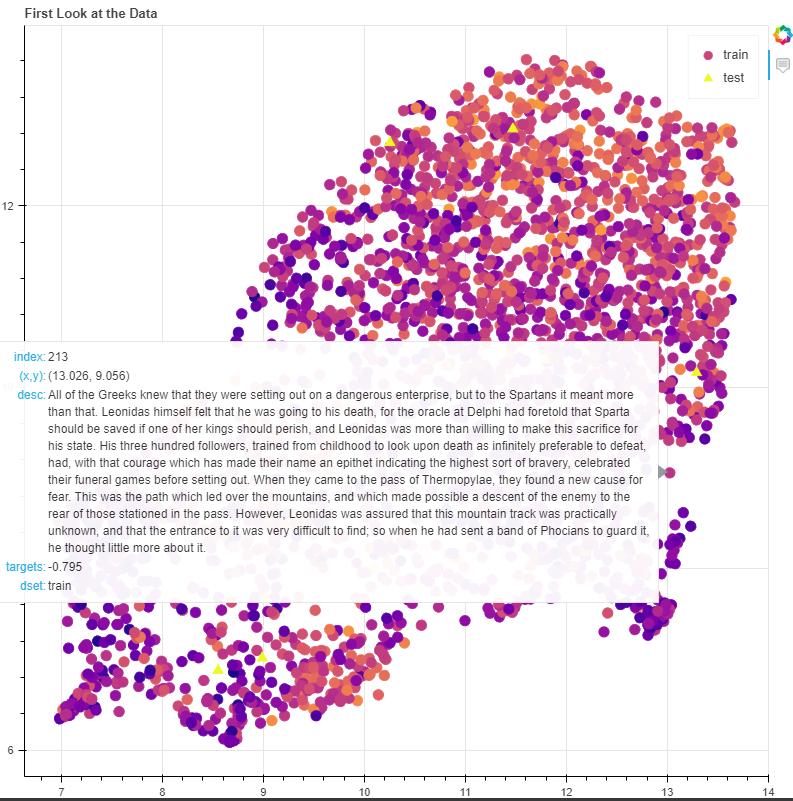
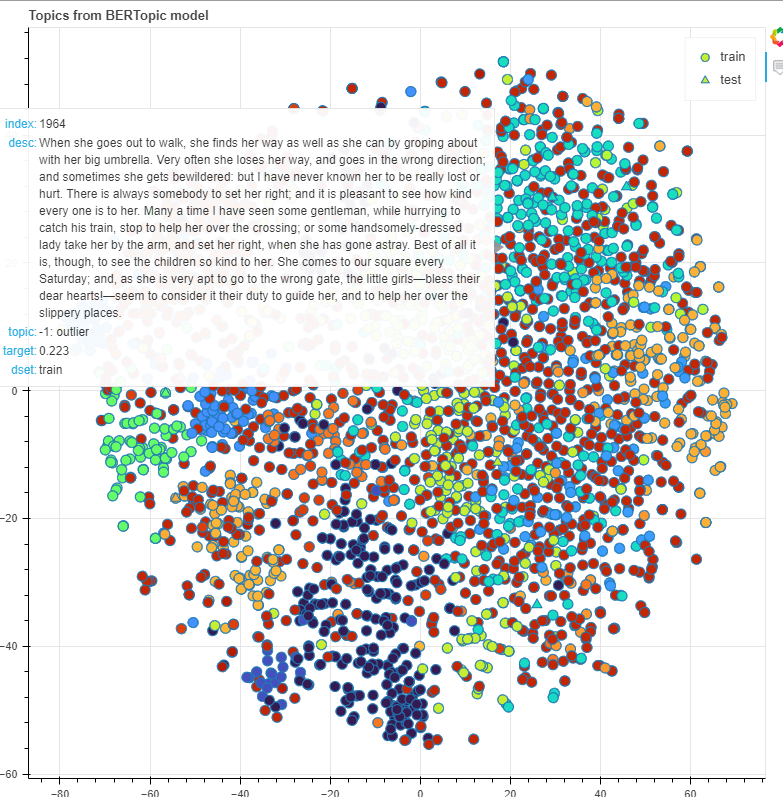
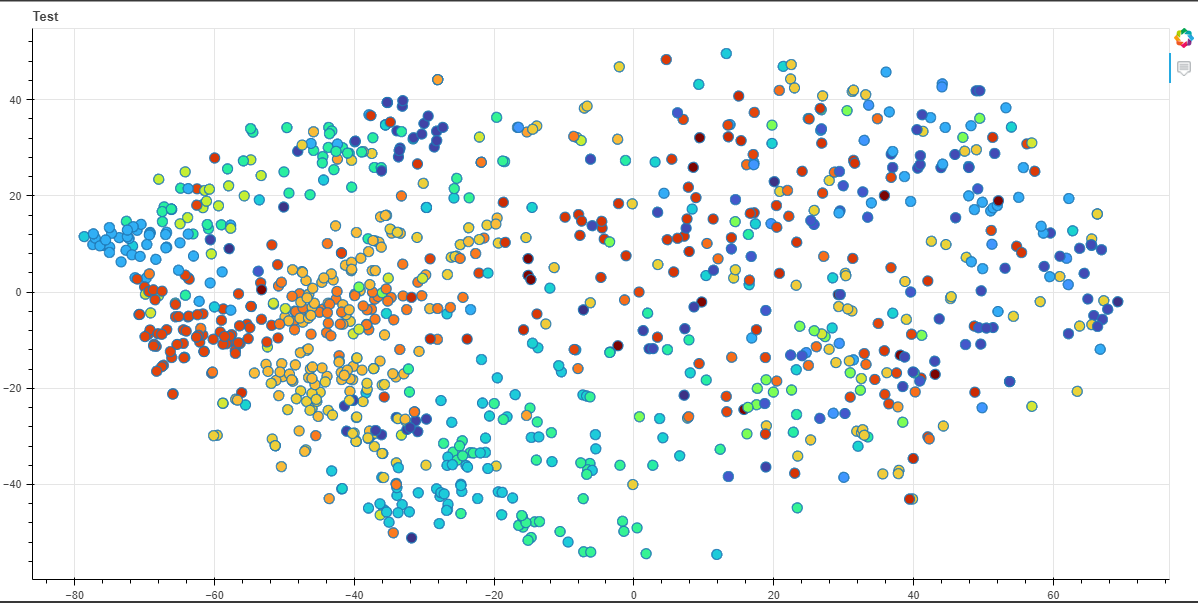 看上面的图表,由LDA重新识别的主题内文档不一定相互接近。
与BERTopic是互补的,可以得到不同的主题表示。
看上面的图表,由LDA重新识别的主题内文档不一定相互接近。
与BERTopic是互补的,可以得到不同的主题表示。