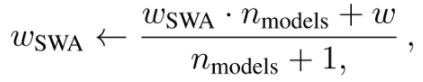defforward(self, all_hidden_states): hidden_states = torch.stack([all_hidden_states[layer_i][:, 0].squeeze() for layer_i in range(1, self.num_hidden_layers+1)], dim=-1) hidden_states = hidden_states.view(-1, self.num_hidden_layers, self.hidden_size) out = self.attention(hidden_states) out = self.dropout(out) return out
defattention(self, h): v = torch.matmul(self.q, h.transpose(-2, -1)).squeeze(1) v = F.softmax(v, -1) v_temp = torch.matmul(v.unsqueeze(1), h).transpose(-2, -1) v = torch.matmul(self.w_h.transpose(1, 0), v_temp).squeeze(2) return v
# torch.qr is slow on GPU (see https://github.com/pytorch/pytorch/issues/22573). So compute it on CPU until issue is fixed all_layer_embedding = all_layer_embedding.cpu()
attention_mask = features['attention_mask'].cpu().numpy() unmask_num = np.array([sum(mask) for mask in attention_mask]) - 1# Not considering the last item embedding = []
# One sentence at a time for sent_index in range(len(unmask_num)): sentence_feature = all_layer_embedding[sent_index, :, :unmask_num[sent_index], :] one_sentence_embedding = [] # Process each token for token_index in range(sentence_feature.shape[1]): token_feature = sentence_feature[:, token_index, :] # 'Unified Word Representation' token_embedding = self.unify_token(token_feature) one_sentence_embedding.append(token_embedding)
no_decay = ["bias", "LayerNorm.weight"] optimizer_grouped_parameters = [{ "params": [p for n, p in model.named_parameters() ifnot any(nd in n for nd in no_decay)], "weight_decay": weight_decay, "lr": lr}, {"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0, "lr": lr} ]
for layer in model.roberta.encoder.layer[-reinit_layers:]: for module in layer.modules(): if isinstance(module, nn.Linear): print(module.weight.data)
重新初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
reinit_layers = 2 # TF version uses truncated_normal for initialization. This is Pytorch if reinit_layers > 0: print(f'Reinitializing Last {reinit_layers} Layers ...') encoder_temp = getattr(model, _model_type) for layer in encoder_temp.encoder.layer[-reinit_layers:]: for module in layer.modules(): if isinstance(module, nn.Linear): module.weight.data.normal_(mean=0.0, std=config.initializer_range) if module.bias isnotNone: module.bias.data.zero_() elif isinstance(module, nn.Embedding): module.weight.data.normal_(mean=0.0, std=config.initializer_range) if module.padding_idx isnotNone: module.weight.data[module.padding_idx].zero_() elif isinstance(module, nn.LayerNorm): module.bias.data.zero_() module.weight.data.fill_(1.0) print('Done.!')
if reinit_layers > 0: print(f'Reinitializing Last {reinit_layers} Layers ...') for layer in model.model.decoder.layers[-reinit_layers :]: for module in layer.modules(): model.model._init_weights(module) print('Done.!')
实验表明, Re-initialization 对 random seed 更
robust。不建议初始化超过6层的layer,不同任务需要实验找到最好的参数。
# initialize lr for task specific layer optimizer_grouped_parameters = [ { "params": [p for n, p in model.named_parameters() if"classifier"in n or"pooler"in n], "weight_decay": 0.0, "lr": learning_rate, }, ]
# initialize lrs for every layer num_layers = model.config.num_hidden_layers layers = [getattr(model, model_type).embeddings] + list(getattr(model, model_type).encoder.layer) layers.reverse()
lr = learning_rate for layer in layers: lr *= layerwise_learning_rate_decay optimizer_grouped_parameters += [ { "params": [p for n, p in layer.named_parameters() ifnot any(nd in n for nd in no_decay)], "weight_decay": weight_decay, "lr": lr, }, { "params": [p for n, p in layer.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0, "lr": lr, }, ] return optimizer_grouped_parameters
import torch import torch.nn as nn import torch.nn.init as init import torch.nn.functional as F from torch.nn import Parameter from torch.autograd.function import InplaceFunction
@classmethod defforward(cls, ctx, input, target=None, p=0.0, training=False, inplace=False): if p < 0or p > 1: raise ValueError("A mix probability of mixout has to be between 0 and 1,"" but got {}".format(p)) if target isnotNoneand input.size() != target.size(): raise ValueError( "A target tensor size must match with a input tensor size {}," " but got {}".format(input.size(), target.size()) ) ctx.p = p ctx.training = training
if ctx.p == 0ornot ctx.training: return input
if target isNone: target = cls._make_noise(input) target.fill_(0) target = target.to(input.device)
if inplace: ctx.mark_dirty(input) output = input else: output = input.clone()
classPriorWD(Optimizer): def__init__(self, optim, use_prior_wd=False, exclude_last_group=True): super(PriorWD, self).__init__(optim.param_groups, optim.defaults) self.param_groups = optim.param_groups self.optim = optim self.use_prior_wd = use_prior_wd self.exclude_last_group = exclude_last_group self.weight_decay_by_group = [] for i, group in enumerate(self.param_groups): self.weight_decay_by_group.append(group["weight_decay"]) group["weight_decay"] = 0
# w pretrained self.prior_params = {} for i, group in enumerate(self.param_groups): for p in group["params"]: self.prior_params[id(p)] = p.detach().clone()
defstep(self, closure=None): if self.use_prior_wd: for i, group in enumerate(self.param_groups): for p in group["params"]: if self.exclude_last_group and i == len(self.param_groups): p.data.add_(-group["lr"] * self.weight_decay_by_group[i], p.data) else: # w - w pretrained p.data.add_( -group["lr"] * self.weight_decay_by_group[i], p.data - self.prior_params[id(p)], ) loss = self.optim.step(closure)
return loss
defcompute_distance_to_prior(self, param): assert id(param) in self.prior_params, "parameter not in PriorWD optimizer" return (param.data - self.prior_params[id(param)]).pow(2).sum().sqrt()
for epoch in range(100): for input, target in loader: optimizer.zero_grad() loss_fn(model(input), target).backward() optimizer.step() if epoch > swa_start: swa_model.update_parameters(model) swa_scheduler.step() else: scheduler.step()
# Update bn statistics for the swa_model at the end torch.optim.swa_utils.update_bn(loader, swa_model) # Use swa_model to make predictions on test data preds = swa_model(test_input)
defget_optimizer_params(model, type='unified'): # differential learning rate and weight decay param_optimizer = list(model.named_parameters()) learning_rate = 5e-5 no_decay = ['bias', 'gamma', 'beta'] if type == 'unified': optimizer_parameters = filter(lambda x: x.requires_grad, model.parameters()) elif type == 'module_wise': optimizer_parameters = [ {'params': [p for n, p in model.roberta.named_parameters() ifnot any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.01}, {'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay_rate': 0.0}, {'params': [p for n, p in model.named_parameters() if"roberta"notin n], 'lr': 1e-3, 'weight_decay_rate':0.01} ] elif type == 'layer_wise': group1=['layer.0.','layer.1.','layer.2.','layer.3.'] group2=['layer.4.','layer.5.','layer.6.','layer.7.'] group3=['layer.8.','layer.9.','layer.10.','layer.11.'] group_all=['layer.0.','layer.1.','layer.2.','layer.3.','layer.4.','layer.5.','layer.6.','layer.7.','layer.8.','layer.9.','layer.10.','layer.11.'] optimizer_parameters = [ {'params': [p for n, p in model.roberta.named_parameters() ifnot any(nd in n for nd in no_decay) andnot any(nd in n for nd in group_all)],'weight_decay_rate': 0.01}, {'params': [p for n, p in model.roberta.named_parameters() ifnot any(nd in n for nd in no_decay) and any(nd in n for nd in group1)],'weight_decay_rate': 0.01, 'lr': learning_rate/2.6}, {'params': [p for n, p in model.roberta.named_parameters() ifnot any(nd in n for nd in no_decay) and any(nd in n for nd in group2)],'weight_decay_rate': 0.01, 'lr': learning_rate}, {'params': [p for n, p in model.roberta.named_parameters() ifnot any(nd in n for nd in no_decay) and any(nd in n for nd in group3)],'weight_decay_rate': 0.01, 'lr': learning_rate*2.6}, {'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) andnot any(nd in n for nd in group_all)],'weight_decay_rate': 0.0}, {'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group1)],'weight_decay_rate': 0.0, 'lr': learning_rate/2.6}, {'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group2)],'weight_decay_rate': 0.0, 'lr': learning_rate}, {'params': [p for n, p in model.roberta.named_parameters() if any(nd in n for nd in no_decay) and any(nd in n for nd in group3)],'weight_decay_rate': 0.0, 'lr': learning_rate*2.6}, {'params': [p for n, p in model.named_parameters() if"roberta"notin n], 'lr':1e-3, "momentum" : 0.99}, ] return optimizer_parameters
Strategies: 对于小数据集,复杂的learning rate scheduling
strategies(linear with warmup or
cosine with warmup
etc.)在预训练和finetuning阶段都没什么效果。小数据集,使用简单的scheduling
strategies就行。
optimizer.zero_grad() # Reset gradients tensors for i, (inputs, labels) in enumerate(training_set): predictions = model(inputs) # Forward pass loss = loss_function(predictions, labels) # Compute loss function loss = loss / accumulation_steps # Normalize our loss (if averaged) loss.backward() # Backward pass if (i+1) % accumulation_steps == 0: # Wait for several backward steps optimizer.step() # Now we can do an optimizer step optimizer.zero_grad() # Reset gradients tensors if (i+1) % evaluation_steps == 0: # Evaluate the model when we... evaluate_model() # ...have no gradients accumulated
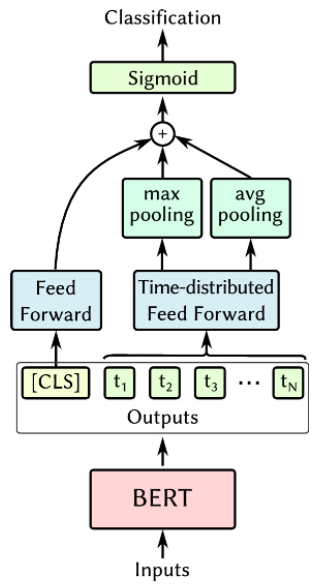
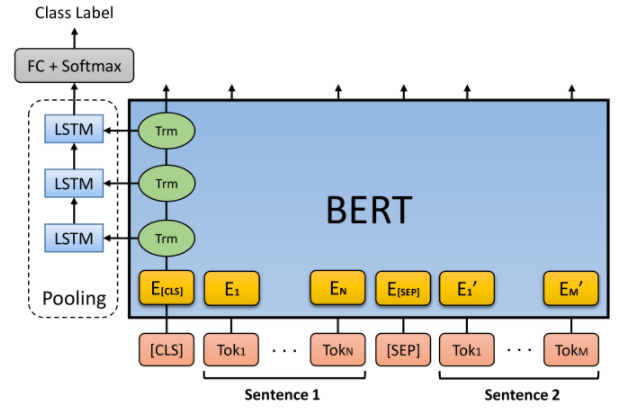 \[
o = h^L_{LSTM} =LSTM(h^i_{CLS}), i ∈ [1, L]
\] CLS token输入LSTM,得到最终表示
\[
o = h^L_{LSTM} =LSTM(h^i_{CLS}), i ∈ [1, L]
\] CLS token输入LSTM,得到最终表示