NLG常用评价指标
NLG常用评价指标
客观评价指标 – BLEU – ROUGE – METEOR – CIDEr
主观评价指标 – 流畅度 – 相关性 – 助盲性
这些指标原先都是用来度量机器翻译结果质量的,并且被证明可以很好的反应待评测翻译结果的准确性,并且与人类对待评测翻译结果的评价存在强相关
BLEU
只看中准确率的指标,就是说更加关心候选译文里的多少 n-gram 是对的(即在参考译文里出现了),而不在乎召回率(参考译文里有哪些 n-gram 在候选译文中没出现)
基于准确率,BLEU 得分越高越好
BLEU 是最早提出的机器翻译评价指标,是所有文本评价指标的源头。BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。
BLEU 的大意是比较候选译文和参考译文里的 n-gram(实践中从 unigram 取到 4-gram) 重合程度,重合程度越高就认为译文质量越高。选不同长度的 n-gram 是因为,unigram 的准确率可以用于衡量单词翻译的准确性,更高阶的 n-gram 的准确率可以用来衡量句子的流畅性。
BLEU 原论文建议大家的测试集里给每个句子配备 4 条参考译文,这样就可以减小语言多样性带来的影响(然而现在很多机器翻译的测试集都是只有 1 条译文,尴尬= =)
brevity penalty 来惩罚候选译文过短的情况(候选译文过短在机器翻译中往往意味着漏翻,也就是低召回率)
现在还是普遍认为 BLEU 指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强)
优点很明显:方便、快速、结果有参考价值
缺点也不少,主要有:
- 不考虑语言表达(语法)上的准确性;
- 测评精度会受常用词的干扰;
- 短译句的测评精度有时会较高;
- 没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
1 | |
只能做到个大概判断,它的目标也只是给出一个快且不差自动评估解决方案
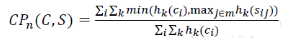
- Hk(Ci) 表示Wk翻译选译文Ci中出现的次数,
- Hk(Sij) 表示Wk在标准答案Sij中出现的次数,
- maxi∈mhk(sij)表示某n-gram在多条标准答案中出现最多的次数,
- ∑i∑kmin(hk(ci),maxj∈mhk(sij))表示取n-gram在翻译译文和标准答案中出现的最小次数。
i为candidate的index;j为reference的index;k为n-gram的index

ROUGE
ROUGE 和 BLEU 几乎一模一样,区别是 BLEU 计算准确率,而 ROUGE 计算召回率。
在 SMT(统计机器翻译)时代,机器翻译效果稀烂,需要同时评价翻译的准确度和流畅度;等到 NMT (神经网络机器翻译)出来以后,神经网络脑补能力极强,翻译出的结果都是通顺的,但是有时候容易瞎翻译,遗漏翻译
不看流畅度只看召回率(参考译文里的 n-gram 有多少出现在了候选译文中)就好了,这样就能知道 NMT 系统到底有没有漏翻(这会导致低召回率)。
所以,ROUGE 适合评价 NMT,而不适用于 SMT,因为它不管候选译文流不流畅。
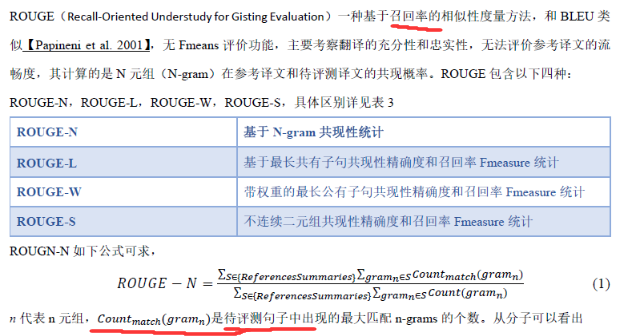
分母是n-gram的个数,分子是参考摘要和自动摘要共有的n-gram的个数。ROUGE 得分越高越好
召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)
精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是对的。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP)
Rough-L: L即是LCS(longest common subsequence,最长公共子序列)的首字母,因为Rough-L使用了最长公共子序列。
METEOR
METEOR 大意是说有时候翻译模型翻译的结果是对的,只是碰巧跟参考译文没对上(比如用了一个同义词),于是用 WordNet 等知识源扩充了一下同义词集,同时考虑了单词的词形(词干相同的词也认为是部分匹配的,也应该给予一定的奖励,比如说把 likes 翻译成了 like
在评价句子流畅性的时候,用了 chunk 的概念(候选译文和参考译文能够对齐的、空间排列上连续的单词形成一个 chunk,这个对齐算法是一个有点复杂的启发式 beam serach),chunk 的数目越少意味着每个 chunk 的平均长度越长,也就是说候选译文和参考译文的语序越一致
缺点:
- 有四个超参数 alpha, beta, gamma, delta,这些都是对着某个数据集调出来的(让算法的结果和人的主观评价尽可能一致,方法我记得是 grid search),参数一多听起来就不靠谱.
- 另外需要有外部知识源(WordNet 等)来进行单词对齐,所以对于 WordNet 中不包含的语言,就没法用 METEOR 来评价了。
使用 WordNet 计算特定的序列匹配,同义词,词根和词缀,释义之间的匹配关系,改善了BLEU的效果,使其跟人工判别共更强的相关性。
同时考虑了准确率和召回率,METEOR 得分越高越好

CIDEr
Consensus-based image description evaluation,通过度量待评测语句与其他大部分人工描述之间的相似性来评价。
这个指标的motivation之一是刚才提到的BLEU的一个缺点,就是对所有匹配上的词都同等对待,而实际上有些词应该更加重要。
CIDEr-D 是修改版本,为的是让 CIDEr 对于 gaming 问题更加鲁棒。什么是 Gaming 问题?它是一种现象,就是一个句子经过人工判断得分很低,但是在自动计算标准中却得分很高的情况。为了避免这种情况,CIDEr-D 增加了截断(clipping)和基于长度的高斯惩罚
CIDEr 是 BLEU 和向量空间模型的结合。它把每个句子看成文档,然后计算 TF-IDF 向量(只不过 term 是 n-gram 而不是单词)的余弦夹角,据此得到候选句子和参考句子的相似度,同样是不同长度的 n-gram 相似度取平均得到最终结果。优点是不同的 n-gram 随着 TF-IDF 的不同而有不同的权重,因为整个语料里更常见的 n-gram 包含了更小的信息量。
SPICE
SPICE 是专门设计出来用于 image caption 问题的。全称是 Semantic Propositional Image Caption Evaluation。前面四个方法都是基于 n-gram 计算的,SPICE 则不是。
SPICE 使用基于图的语义表示来编码 caption 中的 objects, attributes 和 relationships。它先将待评价 caption 和参考 captions 用 Probabilistic Context-Free Grammar (PCFG) dependency parser parse 成 syntactic dependencies trees,然后用基于规则的方法把 dependency tree 映射成 scene graphs。最后计算待评价的 caption 中 objects, attributes 和 relationships 的 F-score 值。
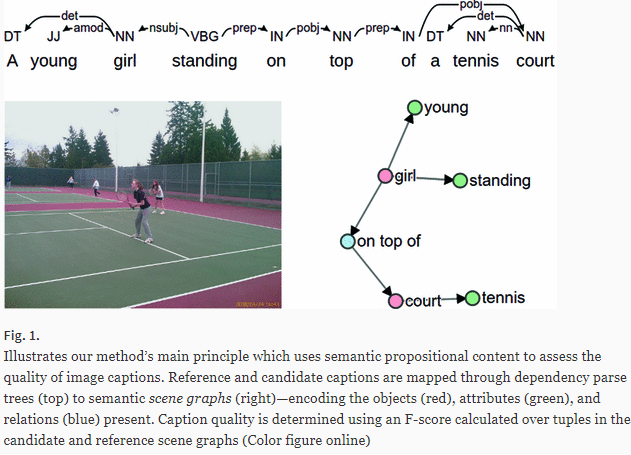
翻译和图像描述的区别
在机器翻译中,译文应该忠实于原文,所以同一句话的多条译文应该互为转述,包含同样的信息;而同一幅图的多条字幕则不一定互为转述,因为不同的字幕可以包含不同数量的图像细节,不管描述得比较详细还是比较粗糙都是正确的字幕。
简单总结
NLG常用metrics:
- BLEU: ngram precision;长度类似
- ROUGE: ngram recall
- NIST/CIDEr: 降低频繁词的权重
- METEOR: 考虑同义词的F score;鼓励连续词匹配
- SPICE:匹配语法树与图像特征的F1
其他:
- STM: 匹配语法树子树
- TER: 编辑的距离
- TERp: TER+同义替换
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!