Fairseq Notes
1.基于CNN的翻译系统模型结构
在自然语言处理中,大部分流行的seq2seq模型都是基于RNN结构去构建encoder和decoder,但是RNN对于下一个状态的预测需要依赖前面的所有历史状态,使得并行化操作难以充分进行,难以发挥完全发挥GPU并行的效率。相反CNN通过在固定窗口内的计算,使得计算的并行化变得更加简单,而且通过多层CNN网络可以构建层级结构(hierarchical structure),可以达到利用更短的路径去覆盖更长范围内的信息。
Facebook提出了基于CNN的机器翻译模型,并开源了CNN的机器翻译工具Fairseq
1.1 Pooling Encoder
最简单的non-recurrent encoder就是把k个连续的单词的词向量求平均值,通过在句子左右两边都添加额外的空单词(paddings),可以使得encoder输出跟原来句子同等长度的hidden embeddings。
- 假设原来的句子的词向量(word embedding)表示为 \(w=[w_1,\cdots,w_m],~\forall~w_j\in R^f\)
- absolute position embeddings用于编码位置信息 \(p=[p_1,\cdots,p_m],~\forall~p_j\in R^f\) \[e_j = w_j + p_j,~~ z_j = {1\over k} \sum_{t=-k/2}^{k/2}e_{j+t} \]
- 传统的attention机制 \[ c_i = \sum_{j=1}^m a_{ij} e_j\]
1.2 卷积编码器Convolutional Encoder NMT
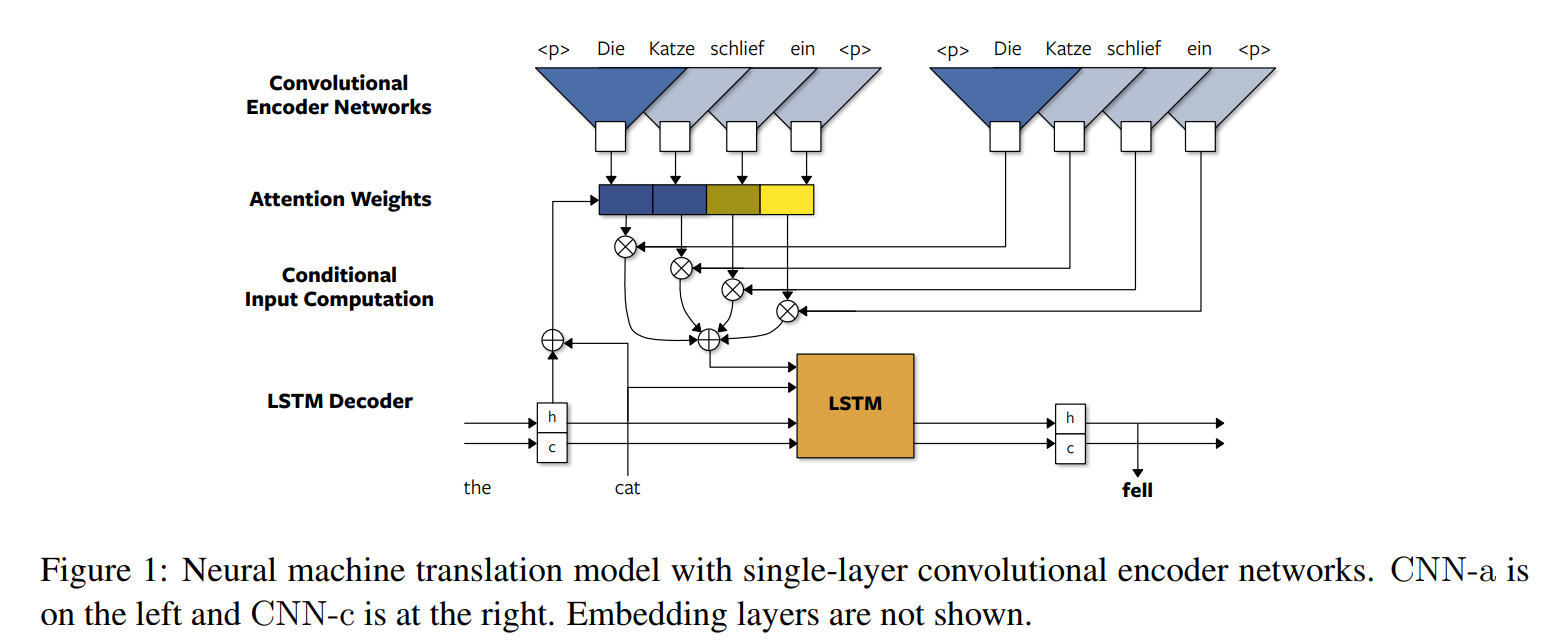
- 卷积编码器在pooling encoder的基础上进行改进,使用一个CNN-a 卷积层来进一步编码源语言句子中的词。输出原句长度的第一层卷积结果Z。
\[z_j = CNN\_a(e)_j \]
- 注意attention的时候,使用了另一个CNN-c卷积层来编码源语言句子中的单词,还是输出原句长度的第一层卷积结果,作为计算atttention weight的encoder hidden states。然后计算atttention weight,再进行加权求和。
\[c_i = \sum_{j=1}^m a_{ij} CNN\_c(e)_j\]
该模型的encoder 采用的是CNN,但其decoder还是采用了传统的RNN模型
1.3 全卷积神经翻译模型 Convolutional NMT
该模型的encoder和decoder都采用的是卷积核CNN,动图演示

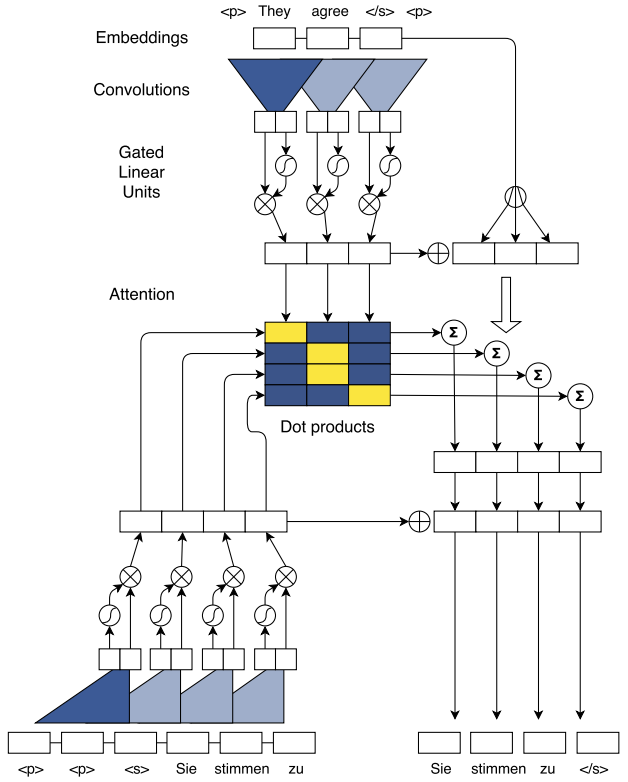
卷积核结构
假设有1D的卷积核的窗口大小是k(比如k=5),每个卷积核都可以用一个权重矩阵\(W\in \mathbb{R}^{2d\times kd}\)和 bias \(b_w\in \mathbb{R}^{2d}\)。对于窗口内的词向量 \(X\in \mathbb{R}^{k\times d}\)把所有单词拼接成一个长向量 \(X'\in \mathbb{R}^{kd}\). \[Y=WX'+b_w = [A B] \in \mathbb{R}^{2d} \\ A,B\in \mathbb{R}^{d} \]
接下来采用Gated Linear Unites(GLU)的方式来进行编码, \(\sigma()\)是一个非线性的激活函数, \(\otimes\)是element-wise mulitiplication \[v([A B] = A \otimes \sigma(B) \in \mathbb{R}^d\]
残差连接 Residual Connection: 把这一层的输入也累加到下一层的输出 \[h_i^l = v(W^l [h_{(i-k)/2}^{l-1},\cdots,h_{(i+k)/2}^{l-1}]+b_w^l)+h_i^{l-1} \in \mathbb{R}^d\]
编码器 Encoder:
假设原来的句子的词向量(word embedding)表示为 \(w=[w_1,\cdots,w_m],~\forall~w_j\in \mathbb{R}^f\)
absolute position embeddings用于编码位置信息 \(p=[p_1,\cdots,p_m],~\forall~p_j\in \mathbb{R}^f\) \[e_j = w_j + p_j \\ \]
encoder 先用一个线性函数\(f:\mathbb{R}^f\rightarrow \mathbb{R}^d\),把词向量映射到d维空间中
接下来encoder会将词向量通过一层层卷积核,得到每一层的单词的隐式表达(hidden state), 其中 \(z_j^u\) 代表的是第u层CNN中第j个单词的表达
Multi-step Attention机制
假设已经翻译的单词的词表达是 \(g=[g_1,\cdots, g_n]\),跟源语言的词表达一样,这里也是word embeddings加上positional embeddings
假设decoder的卷积核的hidden state \(h_i^l\), 可以进一步计算decoder已经生成的单词的每一层的单词表达 \[d_i^l = W_d^l h_i^l + b_d^l + g_i \]
假设encoder 最顶层(假设是第u层)中,每个单词的表达是\(z_j^u\)。可以计算decoder第l层中第i个已经生成的单词\(h_i^l\)与源语言句子中最顶层(也即是第u层)的第j个单词 \(z_j^u\)的权重:
\[a_{ij}^l = {\exp(d_i^l \cdot z_j^u) \over \sum_{t=1}^m \exp(d_i^l \cdot z_t^u) } \]可以进一步计算在decoder第l层,在第i个时刻的上下文向量(也即是context vector)如以下公式,其中将encoder最顶层(第u层)的词向量\(z_j^u\)与最底层的词向量\(e_j\)相加。
\[c_i^l = \sum_{j=1}^m a_{ij}^l (z_j^u + e_j) \]
- 将\(c_i^l\)加到\(h_i^l\)中,作为decoder 的下一层的输入
解码器 decoder
- 把decoder最顶层的hidden state \(h_i^L\) 通过一个线性的函数映射到词表空间上\(d\rightarrow |V|\),之后在通过一个softmax函数 归一化成一个条件概率向量: \[p(y_{i+1}|y_1,\cdots, y_i, x)= softmax(W_o h_i^L + b_0) \in \mathbb{R}^{|V|} \]
模型的结构图
1.4 全卷积神经翻译模型对比RNN神经翻译模型
- 全卷积神经网络使用层级结构,可以充分地并行化
- 对于一个窗口大小为\(k\)的CNN,编码一个特征向量可以总结一个窗口为n个单词的信息,只需要做\(O(n/k)\)个卷积核操作。对比RNN,RNN编码一个窗口为n个单词的信息,需要做\(O(n)\)个操作,跟句子的长度成正比
- 对于一个CNN的输入,都进行了相同数量的卷积操作及非线性操作。对比RNN,第一个输入的单词进行了n词非线性操作,而最后一个输入的单词只进行了一次非线性操作。对于每个输入都进行相同数量的操作会有利于训练。
- 训练CNN NMT需要非常小心地设置参数及调整网络中某些层的缩放。
2 使用CNN完成神经机器翻译系统的tricks
训练过程中,需要将网络中某些部分进行缩放(scaling),需要对权重初始化,需要对超参数进行设置
2.1 缩放操作(scaling)
- 将残差层的输出乘以 \(\sqrt{0.5}\), 这样会减小一半的偏差variance
- 对于attention机制产生的上下文向量 \(c_{ij}^l\) 乘以一个系数 \(m\sqrt{1/m}\), 其中m为源语言句子中单词个个数,这样做的好处也是能减小偏差。
- 对于CNN decoder有multiple atttention的情况,将encoder 每一层的gradient乘以一个系数,该系数是使用的attention的数量。注意,只对encoder中除了源语言单词的词向量矩阵以外的参数,放大gradient,源语言的词向量矩阵的gradient不进行放大。在实验中,这样的操作会使得训练能更加稳定。
2.2 参数初始化
- 所有的词向量矩阵从一个以0为中心,标准差为0.1的高斯分布中随机初始化 \(\mathcal{N}(0, \sqrt{n_l})\), 其中\(n_l\)为输入到这个神经元的输入个数,一般可以设置为0.1。这样能有助于保持一个正态分布的偏差。
- 还需要对每一层的激活函数输出进行正规化(normalization), 比如残差连接中,每一层层的输出向量需要先做正则化,再把这一层的输入加到输出的向量上。
- 对于GLU,需要对其权重 \(W\)从一个正态分布\(\mathcal{N}(0, \sqrt{4p\over n_l})\)中随机抽样,而其bias设置成0
- 对每一层网络的输入向量都进行dropout处理
2.3 超参数设置
- encoder 和decoder都是用512维的hidden units,512维的word embeddings
- 训练的时候使用Nesterov's accelerated gradient 的方法进行优化模型,momentum 设置成0.99
- 如果gradient的norm超过0.1就把gradient 重新归一化到0.1以内。
- 初始的learning rate设置成0.25,如果在每次进行valudation的时候dev数据集中的perplexity没有下降,就将learning rate乘以0.1, 一直持续到learning rate 降到\(10^{-4}\)以下停止训练
- mini-batch的大小设置成每次处理64句双语句子
3. Facebook CNN 机器翻译系统代码解析
- 相应的代码可以在github上找到 fairseq
- 安装
1 | |
https://fairseq.readthedocs.io/en/latest/command_line_tools.html
3.1 Code
1 | |
3.2 使用预训练好的模型
1 | |
3.3 Notes
- CNN NMT类 FConvModel
1 | |
- CNN encoder类
1 | |
- 解码器decoder
1 | |
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!