defcomplain_about(substring): print('Please talk to me!') try: whileTrue: # 执行到此处,控制点返回shell,直到外部send数据到yield处,传递给text text = (yield) if substring in text: print('Oh no: I found a %s again!' % (substring)) except GeneratorExit: print('Ok, ok: I am quitting.')
1 2 3 4 5 6 7 8 9 10 11
>>> c = complain_about('Ruby') >>> next(c) Please talk to me! >>> c.send('Test data') >>> c.send('Some more random text') >>> c.send('Test data with Ruby somewhere in it') Oh no: I found a Ruby again! >>> c.send('Stop complaining about Ruby or else!') Oh no: I found a Ruby again! >>> c.close() Ok, ok: I am quitting. 复制ErrorOK!
defcoroutine(fn): @wraps(fn) defwrapper(*args, **kwargs): c = fn(*args, **kwargs) next(c) return c
return wrapper
defcat(f, case_insensitive, child): if case_insensitive: line_processor = lambda l: l.lower() else: line_processor = lambda l: l for line in f: child.send(line_processor(line))
@coroutine defgrep(sub_str, case_insensitive, child): if case_insensitive: sub_str = sub_str.lower() whileTrue: text = (yield) # 等待send发送的数据 child.send(text.count(sub_str))
@coroutine defcount(sub_str): n = 0 try: whileTrue: n += (yield) except GeneratorExit: print(sub_str, n)
@coroutine deffanout(children): # 多个目标同时输入,计数 whileTrue: data = (yield) for child in children: child.send(data)
from threading import Thread from queue import Queue import urllib.request URL = 'http://finance.yahoo.com/d/quotes.csv?s={}=X&f=p'
defget_rate(pair, outq, url_tmplt=URL): with urllib.request.urlopen(url_tmplt.format(pair)) as res: body = res.read() outq.put((pair, float(body.strip())))
if __name__ == '__main__': import argparse parser = argparse.ArgumentParser() parser.add_argument('pairs', type=str, nargs='+') args = parser.parse_args() outputq = Queue() for pair in args.pairs: t = Thread(target=get_rate, kwargs={'pair': pair, 'outq': outputq}) t.daemon = True# 结束时,会自行回收线程资源 t.start() for _ in args.pairs: pair, rate = outputq.get() print(pair, rate) outputq.task_done() outputq.join()
deffib(n): if n <= 2: return1 elif n == 0: return0 elif n < 0: raise Exception('fib(n) is undefined for n < 0') return fib(n - 1) + fib(n - 2)
if __name__ == '__main__': import argparse parser = argparse.ArgumentParser() parser.add_argument('-n', type=int, default=1) parser.add_argument('number', type=int, nargs='?', default=34) args = parser.parse_args() assert args.n >= 1, 'The number of threads has to be > 1'
with cf.ProcessPoolExecutor(max_workers=args.n) as pool: results = pool.map(fib, [args.number] * args.n)
deffib(n): if n <= 2: return1 elif n == 0: return0 elif n < 0: raise Exception('fib(n) is undefined for n < 0') return fib(n - 1) + fib(n - 2)
defworker(inq, outq): "inq 任务队列, outq 输出队列" whileTrue: data = inq.get() if data isNone: # 检测 哨兵值 return fn, arg = data outq.put(fn(arg))
if __name__ == '__main__': import argparse parser = argparse.ArgumentParser() parser.add_argument('-n', type=int, default=1) parser.add_argument('number', type=int, nargs='?', default=34) args = parser.parse_args() assert args.n >= 1, 'The number of threads has to be > 1'
tasks = mp.Queue() results = mp.Queue() for i in range(args.n): tasks.put((fib, args.number)) for i in range(args.n): mp.Process(target=worker, args=(tasks, results)).start() for i in range(args.n): print(results.get()) for i in range(args.n): # 输入哨兵值,停止worker tasks.put(None)
# 连接到服务器,也就是运行task_master.py的机器: server_addr = '127.0.0.1' print('Connect to server %s...' % server_addr)
# 端口和验证码注意保持与task_master.py设置的完全一致: m = QueueManager(address=(server_addr, 5000), authkey=b'abc') # 从网络连接: m.connect()
# 获取Queue的对象: task = m.get_task_queue() result = m.get_result_queue()
# 从task队列取任务,并把结果写入result队列: for i in range(10): try: n = task.get(timeout=1) print('run task %d * %d...' % (n, n)) r = '%d * %d = %d' % (n, n, n * n) time.sleep(1) result.put(r) except queue.Queue.Empty: print('task queue is empty.')
defget_new_article(self): article = self.content_stream.next() # Count the words and store the result. self.word_counts.append(Counter(article.split(" "))) self.num_articles_processed += 1
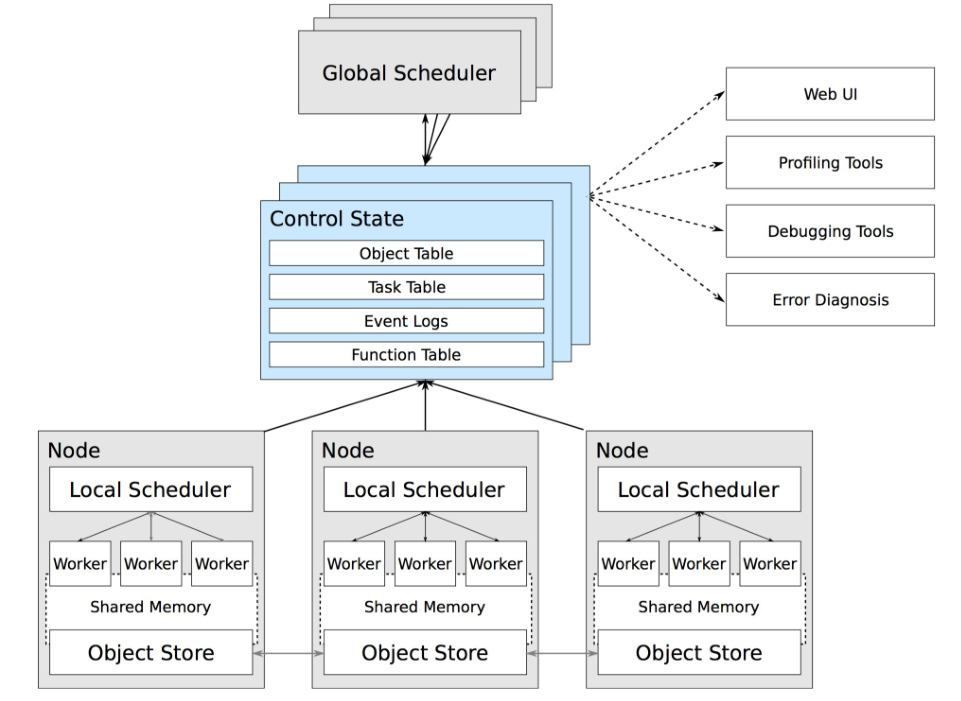
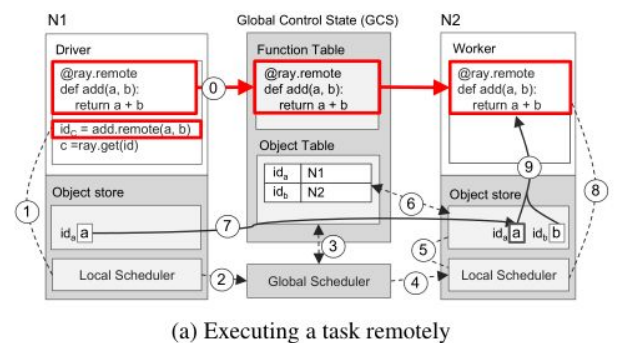
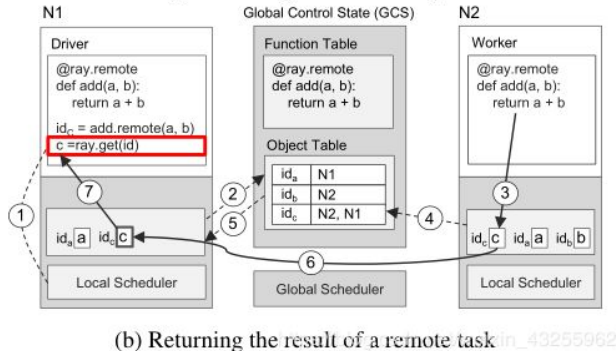
defget_range(self, article_index, keys): """keys: list of 2 chars article_index:当前mapper处理的文章index,需要与GlobalScheduler中任务参数进行通信, 保证当前article在整个处理序列中处于article_index的位置""" # Process more articles if this Mapper hasn't processed enough yet. while self.num_articles_processed < article_index + 1: self.get_new_article() # Return the word counts from within a given character range. return [(k, v) for k, v in self.word_counts[article_index].items() if len(k) >= 1and k[0] >= keys[0] and k[0] <= keys[1]]
defnext_reduce_result(self, article_index): word_count_sum = defaultdict(lambda: 0) # Get the word counts for this Reducer's keys from all of the Mappers # and aggregate the results. count_ids = [ mapper.get_range.remote(article_index, self.keys) for mapper in self.mappers ] # From many Mappers for count_id in count_ids: for k, v in ray.get(count_id): word_count_sum[k] += v return word_count_sum
if __name__ == "__main__": MAX = 10 args = parser.parse_args()
ray.init()
# Create one streaming source of articles per mapper. directory = os.path.dirname(os.path.realpath(__file__)) streams = [] folders = ['/data/AA/', '/data/AB/', '/data/AC/'] for i in range(args.num_mappers): streams.append(Stream(MAX, folders[i % len(folders)]))
# Partition the keys among the reducers. chunks = np.array_split([chr(i) for i in range(ord("a"), ord("z") + 1)], args.num_reducers) keys = [[chunk[0], chunk[-1]] for chunk in chunks]
# Create a number of mappers. mappers = [Mapper.remote(stream) for stream in streams]
# Create a number of reduces, each responsible for a different range of # keys. This gives each Reducer actor a handle to each Mapper actor. reducers = [Reducer.remote(key, *mappers) for key in keys]
# Most frequent 10 words. article_index = 0 whileTrue: print("article index = {}".format(article_index)) wordcounts = {} counts = ray.get([ reducer.next_reduce_result.remote(article_index) for reducer in reducers ]) for count in counts: wordcounts.update(count) most_frequent_words = heapq.nlargest(10, wordcounts, key=wordcounts.get) for word in most_frequent_words: print(" ", word, wordcounts[word]) article_index += 1
然后,在每个节点保存一份代码,启动worker和master节点
1 2 3 4
ray start --head--ip localhost --redis-port=6379
# 修改head_node_address为 master 节点的ip地址 ray start --address=[head_node_address]:6379