CPU-bound 与 Memory-bound
CPU并行能加速计算,并不能加速内存读写。
常见读写和计算的时间花费对比:
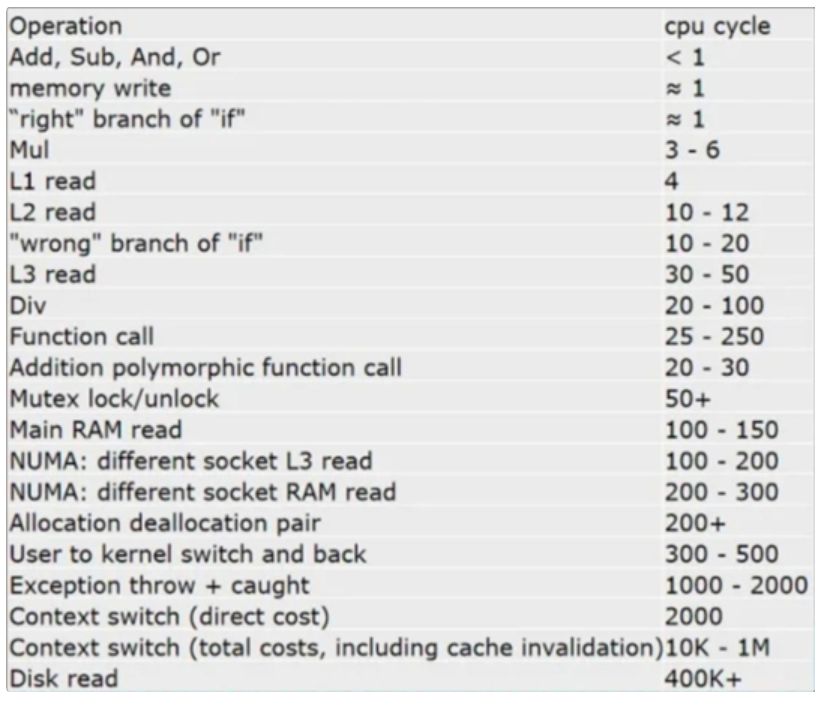
L1/2/3 read和Main RAM
read的时间指的是读一个缓存行(64字节)所花费的时间。
若从主存读取一个float,大约花费时间 125 / 64 * 4 = 8
个时钟周期。(125:从主存读取一个缓存行的时间,64:一个缓存行64字节,4:一个浮点数4字节)
也就是说想要避免 mem-bound
充分利用CPU核心的计算能力,就需要在计算任务部分有足够的计算量,使得计算花费时间不小于内存读写花费的时间。
另外,如果数据能够充分在高速缓存中读取,也能够起到避免 mem-bound
的作用。
缓存机制
读
缓存会查找和该地址匹配的条目。如果找到,则给CPU返回缓存中的数据。如果找不到,则向主内存发送请求,等读取到该地址的数据,就创建一个新条目。
在 x86 架构中每个条目的存储 64
字节的数据,这个条目又称之为缓存行(cacheline)。当访问 0x0048~0x0050 这
4 个字节时,实际会导致 0x0040~0x0080 的 64
字节数据整个被读取到缓存中。
为了不浪费缓存行的存储空间,可以把数据结构的起始地址和大小对齐到 64
字节。
设计数据结构时,应该把数据存储的尽可能紧凑,不要松散排列。最好每个缓存行里要么有数据,要么没数据,避免读取缓存行时浪费一部分空间没用。
写
缓存会查找和该地址匹配的条目。如果找到,则修改缓存中该地址的数据。如果找不到,则创建一个新条目来存储CPU写的数据,并标记为脏(dirty)。
当读和写创建的新条目过多,缓存快要塞不下时,他会把最不常用的那个条目移除,这个现象称为失效(invalid)。如果那个条目是被标记为脏的,则说明是当时打算写入的数据,那就需要向主内存发送写入请求,等他写入成功,才能安全移除这个条目。
有多级缓存,则一级缓存失效后会丢给二级缓存。
随机访问
例如对float进行访问,随机访问一个float值,而这导致他附近的64字节都被读取到缓存了,但实际只用到了其中4字节,之后又没用到剩下的60字节,导致浪费了94%的带宽。
解决方法就是,把数据按64字节大小分块。随机访问时,只随机块的位置,而块的内部仍然按顺序访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| #include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <omp.h>
constexpr size_t n = 1<<27;
std::vector<float> a(n);
static uint32_t randomize(uint32_t i) {
i = (i ^ 61) ^ (i >> 16);
i *= 9;
i ^= i << 4;
i *= 0x27d4eb2d;
i ^= i >> 15;
return i;
}
void BM_random_64B(benchmark::State &bm) {
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n / 16; i++) {
size_t r = randomize(i) % (n / 16);
for (size_t j = 0; j < 16; j++) {
benchmark::DoNotOptimize(a[r * 16 + j]);
}
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_random_64B);
BENCHMARK_MAIN();
|
prefetch
当程序顺序访问 a[0], a[1] 时,CPU会智能地预测到你接下来可能会读取
a[2],于是会提前给缓存发送一个读取指令,让他读取
a[2]、a[3]。
这样等 a[0], a[1] 处理完以后,缓存也刚好读取完 a[2]
了,从而CPU不用等待,就可以直接开始处理
a[2],避免等待数据的时候CPU空转浪费时间。
一般来说只有线性的地址访问规律(包括顺序、逆序;连续、跨步(按固定间隔跳跃))能被识别出来,而如果你的访存是随机的,那就没办法预测。
对于不得不随机访问很小一块的情况,可以通过 _mm_prefetch
指令手动预取一个缓存行。
如果 prefetch
成功,就可以在计算的同时,提前准备好下一次计算的数据,不至于CPU空转,同时将较短的CPU计算时间消耗,隐藏在内存读写的过程中。
内存页
现在操作系统管理内存是用分页(page),程序的内存是一页一页贴在地址空间中的,有些地方可能不可访问,或者还没有分配,则把这个页设为不可用状态,访问他就会出错,进入内核模式。
prefetch不能跨越页边界,否则可能会触发不必要的 page fault。
可以用 _mm_alloc
申请起始地址对齐到页边界的一段内存。
当随机访问数据时,可以按4KB大小的块随机访问,在块内部就可以顺序访问,发挥prefetch的优势。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| #include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <omp.h>
constexpr size_t n = 1<<27;
std::vector<float> a(n);
void BM_random_4KB_aligned(benchmark::State &bm) {
float *a = (float *)_mm_malloc(n * sizeof(float), 4096);
memset(a, 0, n * sizeof(float));
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n / 1024; i++) {
size_t r = randomize(i) % (n / 1024);
for (size_t j = 0; j < 1024; j++) {
benchmark::DoNotOptimize(a[r * 1024 + j]);
}
}
benchmark::DoNotOptimize(a);
}
_mm_free(a);
}
BENCHMARK(BM_random_4KB_aligned);
BENCHMARK_MAIN();
|
为什么写入比读取慢?
因为缓存和内存通信的最小单位是缓存行:64字节。当CPU试图写入4字节时,因为剩下的60字节没有改变,缓存不知道CPU接下来会不会用到那60字节,因此他只好从内存读取完整的64字节,修改其中的4字节为CPU给的数据,之后再择机写回。
写入少于64字节的数据时,虽然没有用到全部的读取数据,但实际上缓存还是从内存读取了,从而浪费了2倍带宽。
_mm_stream_si32
绕过缓存,直接写入。用 _mm_stream_si32
指令代替直接赋值的写入,他能够绕开缓存,将一个4字节的写入操作,挂起到临时队列,等凑满64字节后,直接写入内存,从而完全避免读的带宽。只支持int做参数,要用float还得转换一下指针类型。
_mm 系列指令出自 <xmmintrin.h> 头文件。指令的文档
Intel Intrinsics Guide。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| #include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <omp.h>
constexpr size_t n = 1<<27;
std::vector<float> a(n);
void BM_write_stream_then_read(benchmark::State &bm) {
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
float value = 1;
_mm_stream_si32((int *)&a[i], *(int *)&value);
benchmark::DoNotOptimize(a[i]);
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_write_stream_then_read);
BENCHMARK_MAIN();
|
因为 _mm_stream_si32
会绕开缓存,直接把数据写到内存,之后读取的话,反而需要等待
stream 写回执行完成,然后重新读取到缓存,反而更低效。
因此,仅当这些情况:
- 该数组只有写入,之前完全没有读取过。
- 之后没有再读取该数组的地方。
才应该用 stream 指令。
另外,_mm_stream_ps 可以一次性写入 16
字节到挂起队列,更加高效。不过,_mm_stream_ps 写入的地址必须对齐到 16
字节,否则会产生段错误等异常。
注意,stream
系列指令写入的地址,必须是连续的,中间不能有跨步(固定间隔),否则无法合并写入,会产生有中间数据读的带宽。
为什么对数组写入全1比全0慢?
因为写入0被编译器自动优化成了memset,而memset内部利用了stream指令得以更快写入。而全1并不会调用stream指令。
可以手动调用stream指令写入全1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
| #include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <omp.h>
constexpr size_t n = 1<<27;
std::vector<int> a(n);
void BM_write0(benchmark::State &bm) {
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
a[i] = 0;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_write0);
void BM_write1(benchmark::State &bm) {
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
a[i] = 1;
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_write1);
void BM_write1_streamed(benchmark::State &bm) {
for (auto _: bm) {
#pragma omp parallel for
for (size_t i = 0; i < n; i++) {
_mm_stream_si32(&a[i], 1);
}
benchmark::DoNotOptimize(a);
}
}
BENCHMARK(BM_write1_streamed);
BENCHMARK_MAIN();
|
循环代码优化
当对同一个数组,执行两种操作,在不影响逻辑时,将两个循环写成一个循环可以加速
mem-bound 的程序执行。
在主存看来,
CPU做的事情相当于:读+写+读+写,每个元素都需要访问四遍内存,变成了:读+写,从而每个元素只需要访问两遍内存。
同时,可以利用SIMD优化(编译器优化笔记部分),比如 gcc
unroll、局部变量并行批处理。
内存的分配
当调用 malloc
时,操作系统并不会实际分配那一块内存,而是将这一段内存标记为“不可用”。当用户试图访问(写入)这一片内存时,硬件就会触发所谓的缺页中断(page
fault),进入操作系统内核,内核会查找当前进程的 malloc 历史记录。
如果发现用户写入的地址是他曾经 malloc
过的地址区间,则执行实际的内存分配,并标记该段内存为“可用”,下次访问就不会再产生缺页中断了;而如果用户写入的地址根本不是他
malloc 过的地址,那就说明他确实犯错了,就抛出段错误(segmentation
fault)。
当执行代码 std::vector、new intn
会初始化数组为0,实际分配内存。
malloc(n * sizeof(int))、new int[n]
不会初始化数组为0,不会实际分配内存。
第一次往malloc的数组里面赋值时,因为这时操作系统还没有给这个数组分配内存,所以会触发缺页中断,进入操作系统内核给数组分配内存,是内核执行内存分配的这个动作,会花费额外的时间。
按页分配
当一个尚且处于“不可用”的 malloc
过的区间被访问,操作系统不是把整个区间全部分配完毕,而是只把当前写入地址所在的页面(4KB
大小)给分配上。
也就是说用户访问 a[0] 以后只分配了 4KB 的内存。等到用户访问了
a[1024],也就是触及了下一个页面,他才会继续分配一个 4KB
的页面,这时才实际分配 8KB 。
比如malloc申请 16GB 内存,但是只访问了他的前
4KB,这样只有一个页被分配,所以非常快。
内存重复利用
即使第二次分配的是同一段差不多大小的内存(第一次分配内存不会再使用),也是会产生缺页中断,花费分配时间的。
这就需要改动STL容器的allocator。tbb::cache_aligned_allocator
可以提升一定的性能。最大好处在于他分配的内存地址,永远会对齐到缓存行(64字节)。
标准库的 new 和 malloc 可以保证 16 字节对齐。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include <iostream>
#include <vector>
#include "ticktock.h"
#include <cstdlib>
constexpr size_t n = 1<<20;
int main() {
std::cout << std::boolalpha;
for (int i = 0; i < 5; i++) {
std::vector<int> arr(n);
bool is_aligned = (uintptr_t)arr.data() % 16 == 0;
std::cout << "std: " << is_aligned << std::endl;
}
for (int i = 0; i < 5; i++) {
auto arr = (int *)malloc(n * sizeof(int));
bool is_aligned = (uintptr_t)arr % 16 == 0;
std::cout << "malloc: " << is_aligned << std::endl;
free(arr);
}
return 0;
}
|
还有 _mm_malloc(n, aalign) 可以分配对齐到任意 aalign 字节的内存。他在
<xmmintrin.h> 这个头文件里。是 x86 特有的,并且需要通过 _mm_free
来释放。 还有一个跨平台版本(比如用于 arm 架构)的 aligned_alloc(align,
n),他也可以分配对齐到任意 align 字节的内存,通过 free 释放。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| #include <iostream>
#include <vector>
#include "ticktock.h"
#include <cstdlib>
#include <x86intrin.h>
constexpr size_t n = 1<<20;
int main() {
std::cout << std::boolalpha;
for (int i = 0; i < 5; i++) {
auto arr = (int *)_mm_malloc(n * sizeof(int), 4096);
bool is_aligned = (uintptr_t)arr % 4096 == 0;
std::cout << "_mm_malloc: " << is_aligned << std::endl;
_mm_free(arr);
}
for (int i = 0; i < 5; i++) {
auto arr = (int *)aligned_alloc(4096, n * sizeof(int));
bool is_aligned = (uintptr_t)arr % 4096 == 0;
std::cout << "aligned_alloc: " << is_aligned << std::endl;
free(arr);
}
return 0;
}
|
利用 aligned_alloc 可以实现任意对齐的allocator。stackoverflow链接。
使用这个allocator,可以改变容器的内存分配布局。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| #include <iostream>
#include <vector>
#include "ticktock.h"
#include "alignalloc.h"
constexpr size_t n = 1<<20;
int main() {
std::cout << std::boolalpha;
for (int i = 0; i < 5; i++) {
std::vector<int, AlignedAllocator<int>> arr(n);
bool is_aligned = (uintptr_t)arr.data() % 64 == 0;
std::cout << "64: " << is_aligned << std::endl;
}
for (int i = 0; i < 5; i++) {
std::vector<int, AlignedAllocator<int, 4096>> arr(n);
bool is_aligned = (uintptr_t)arr.data() % 4096 == 0;
std::cout << "4096: " << is_aligned << std::endl;
}
return 0;
}
|
临时数组优化
如果一个经常调用的函数中,申请了临时数组,可以优化,使得不用每次都重新分配一段内存,浪费时间。
- 声明为 static 变量,这样第二次进入 func
的时候还是同一个数组,不需要重复分配内存;
- thread_local 表示如有多个线程,每个线程保留一个 tmp
对象的副本,防止多线程调用 func 出错。
- 返回时(或者进入时)调用 tmp.clear() 清除已有数据。由于 vector
的特性,他只会把 size() 标记为 0
并调用其成员的解构函数,而不会实际释放内存(free)。
第二次进入的时候,如果 n
不超过上一次的大小,就还是用的第一次分配的内存,避免了重新分配的开销。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #include <iostream>
#include <vector>
#include <cmath>
#include <algorithm>
#include "ticktock.h"
float func(int n) {
static thread_local std::vector<float> tmp;
for (int i = 0; i < n; i++) {
tmp.push_back(i / 15 * 2.718f);
}
std::reverse(tmp.begin(), tmp.end());
float ret = tmp[32];
tmp.clear();
return ret;
}
int main() {
constexpr int n = 1<<25;
std::cout << func(n) << std::endl;
return 0;
}
|
二维数组
C++/C
对二维数组分配内存是一维的,并没有二级指针的必要,时间和空间效率都比较低(没有冒犯
java 的意思)。
C++/C 范围是按照行主序,也就是说,a[i][j] 翻译为 a[i * num_of_column
+ j]。也就是说先遍历 j ,可以连续访问内存,缓存利用率高。而如果先访问 i
,就变成了跳跃内存地址的访问。
一个优化的ndarray封装,针对图像处理需要,增加了边界扩充设计,方便SIMD矢量化。
矩阵乘法优化
直观实现
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| #include <iostream>
#include <vector>
#include <cmath>
#include <cstring>
#include <cstdlib>
#include <array>
#include <benchmark/benchmark.h>
#include <x86intrin.h>
#include <omp.h>
#include "ndarray.h"
constexpr int n = 1<<10;
ndarray<2, float> a(n, n);
ndarray<2, float> b(n, n);
ndarray<2, float> c(n, n);
void BM_matmul(benchmark::State &bm) {
for (auto _: bm) {
for (int j = 0; j < n; j++) {
for (int i = 0; i < n; i++) {
for (int t = 0; t < n; t++) {
a(i, j) += b(i, t) * c(t, j);
}
}
}
}
}
BENCHMARK(BM_matmul);
BENCHMARK_MAIN();
|
- a(i, j)
始终在一个地址不动(一般),如果有多个i值同时处理会更好。
- b(i, t) 每次跳跃 n 间隔的访问(坏)。
- c(t, j) 连续的顺序访问(好)。
因为存在不连续的 b 和一直不动的
a,导致矢量化失败,一次只能处理一个标量,CPU也无法启动指令级并行(ILP)。
对循环进行分块,再看看访存的规律:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void BM_matmul_blocked(benchmark::State &bm) {
for (auto _: bm) {
for (int j = 0; j < n; j++) {
for (int iBase = 0; iBase < n; iBase += 32) {
for (int t = 0; t < n; t++) {
for (int i = iBase; i < iBase + 32; i++) {
a(i, j) += b(i, t) * c(t, j);
}
}
}
}
}
}
BENCHMARK(BM_matmul_blocked);
BENCHMARK_MAIN();
|
- a(i, j) 连续 32 次顺序访问(好)。
- b(i, t) 连续 32 次顺序访问(好)。
- c(t, j) 32 次在一个地址不动(一般)。
这样就消除不连续的访问了,从而内部的 i
循环可以顺利矢量化,且多个循环体之间没有依赖关系,CPU得以启动指令级并行,缓存预取也能正常工作。
甚至可以进一步将 j 也分块化:
| void BM_matmul_blocked_both(benchmark::State &bm) {
for (auto _: bm) {
for (int jBase = 0; jBase < n; jBase += 16) {
for (int iBase = 0; iBase < n; iBase += 16) {
for (int j = jBase; j < jBase + 16; j++) {
for (int t = 0; t < n; t++) {
for (int i = iBase; i < iBase + 16; i++) {
a(i, j) += b(i, t) * c(t, j);
}
}
}
}
}
}
}
BENCHMARK(BM_matmul_blocked_both);
|
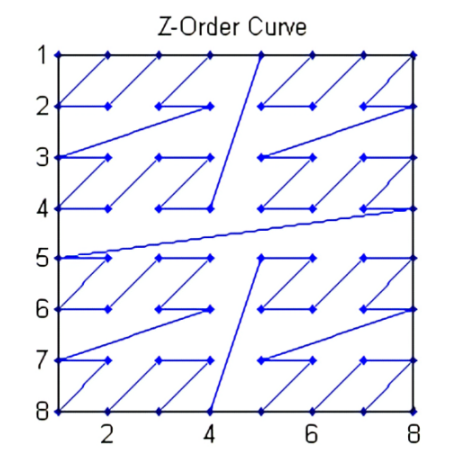
morton code
如果对矩阵进行转置,应该使用行主序还是列主序?显然必有一个矩阵读写会很不友好。
morton code 使用一个时间变量 t,生成下一个访问元素 (x, y)
坐标,尽量保证数据在时间 t 上是接近的,同时二维空间上 (x,y)
也是接近的,利用访存局域性,发挥缓存优势。
多核下的缓存
如果多个核心同时访问的地址非常接近,这时候会变得很慢。
因为 CPU 之间通信的最小单位也是 缓存行(64
字节),如果两个核心访问到了的同一缓存行,假设一个核心修改了该缓存行的前32字节,另一个修改了后32字节,同时写回,只有一个会生效。
所以CPU为了安全起见,同时只能允许一个核心写入同一地址的缓存行。从而导致读写这个变量的速度受限于三级缓存的速度,而不是一级缓存的速度。不能同时写,只有再取一次。
错误共享只会发生在写入的情况,如果多个核心同时读取两个很靠近的变量,是不会产生冲突的,也没有性能损失。
优化
只需要把每个核心写入的地址尽可能分散开了就行了。比如这里,我们把每个核心访问的地方跨越
16KB
(足够远就行),这样CPU就知道每个核心之间不会发生冲突,从而可以放心地放在一级缓存里,不用担心会不会和其他核心共用了一个缓存行了。