RPC笔记
问题场景
一个完整的大型服务会被打散成很多很多独立的小服务,每个小服务会由独立的进程去管理来对外提供服务,也就是
微服务
。用户请求的分发和处理,子服务子系统间结果的通信,向用户返回结果,都是RPC应对的场景。
简介
RPC (Remote Procedure Call)即远程过程调用,是分布式系统常见的一种通信方法。当两个物理分离的子系统需要建立逻辑上的关联时,RPC 是通信的技术手段之一。除 RPC 之外,常见的多系统数据交互方案还有分布式==消息队列==、==HTTP 请求调用==、==数据库==和==分布式缓存==等。
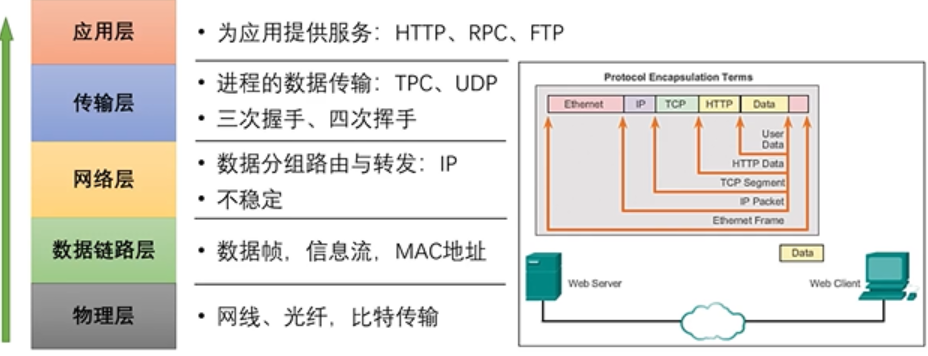
RPC 和 HTTP 调用是没有经过中间件的,它们是端到端系统的直接数据交互。HTTP 调用其实也可以看成是一种特殊的 RPC。知名应用有 Nginx/Redis/MySQL/Dubbo/Hadoop/Spark/Tensorflow 等产品。
Nginx 与 RPC
Ngnix 可以为后端分布式服务提供负载均衡的功能,它可以将后端多个服务地址聚合为单个地址来对外提供服务。 Nginx 和后端服务之间的交互在本质上也可以理解为 RPC 数据交互。除了HTTP,Nginx 和后端服务之间还可以走其它的协议,比如 uwsgi 协议、fastcgi 协议等,这两个协议都是采用了比 HTTP 协议更加节省流量的二进制协议。 uWSGI 是著名的 Python 容器,使用它可以启动 uwsgi 协议的服务器对外提供服务。
Hadoop 与 RPC
大数据需要通信的量比业务系统更加庞大,所以在数据通信优化上做的更深。 Hadoop 文件系统 hdfs,一般包括一个 NameNode 和多个 DataNode,NameNode 和 DataNode 之间就是通过一种称为 Hadoop RPC 的二进制协议进行通讯。
TensorFlow 与 RPC
当多个分布式节点需要集群计算时,就必须引入 RPC 技术进行通讯。Tensorflow Cluster 的 RPC 通讯框架使用了 Google 内部自研的 gRPC 框架。
基于Socket的RPC和基于HTTP的RPC

基于Socket的RPC性能可以达到基于HTTP的RPC的 4 到 10 倍。
HTTP VS RPC
HTTP 调用其实也是一种特殊的 RPC。 HTTP1.0 协议时,HTTP 调用还只能是短链接调用,一个请求来回之后连接就会关闭。HTTP1.1 引入了 KeepAlive 特性可以保持 HTTP 连接长时间不断开,以便在同一个连接之上进行多次连续的请求,进一步拉近了 HTTP 和 RPC 之间的距离。 HTTP2.0 之后,Google 开源了一个建立在 HTTP2.0 协议之上的通信框架直接取名为 gRPC,也就是 Google RPC。
HTTP API虽然效率不高,但是通用,没有太多沟通的学习成本。 RPC 更加高效,经过对应的设计,进行高效率的交流,要比通用的 HTTP 协议来交流更加节省资源。比如 开源 RPC 协议中 Protobuf 和 Thrift 就是方言中的两种。
运行在同一个操作系统实的两个进程通信时,还有共享内存、信号量、文件系统、内核消息队列、管道等,本质上都是通过操作系统内核机制来进行数据和消息的交互。但在现代企业服务中,这种单机应用已经非常少见了。
开源资源与资料
- Remote procedure call - Wikipedia
- gRPC - Wikipedia
- Home · hprose/hprose Wiki (github.com)
- Home · baidu/sofa-pbrpc Wiki (github.com)
- buttonrpc
RPC交互过程
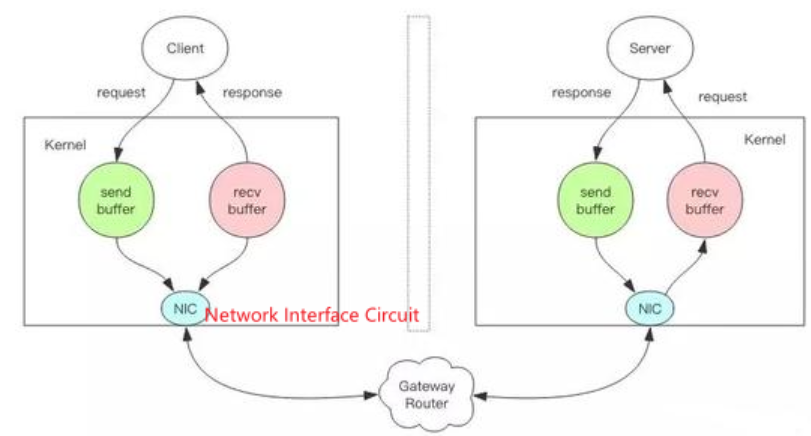
消息协议设计
首先,需要区分每个独立的消息数据,考虑消息数据如何组织表示,如何设计消息数据的格式。
边界
RPC 需要在一条 TCP 链接上进行多次消息传递。网络协议传输过程中,可能存在拆包、粘包问题。需要设计边界区分方法。 比如,使用特殊符号分割不同消息(\r\n)(常用于文本格式消息),或者直接在消息中附加消息数据长度信息(常用于二进制消息)。
结构
显示结构
json 是一种显式结构的消息协议。可读性好,但是冗余信息多。 其中标准格式使用很多标记符号 "、:、{} 等。连续的多条 json 消息即使结构完全一样,仅仅只是 value 的值不一样,也需要发送同样的 key 字符串信息。
一种优化方法:RPC建立连接时,就确定消息的结构,之后只需要根据结构发送 value 值,自动和 key 相对应。比如,Hadoop的 avro 协议。
隐式结构
结构信息由代码来约定的消息协议。在 RPC 交互的消息数据中只是二进制数据,由代码来确定相应位置的二进制是属于哪个字段。 隐式消息的优点就在于节省传输流量,不需要传输结构信息。
压缩
对消息进行压缩处理,可以减轻网络带宽压力,但也会加重 CPU 的负担。
比如 Google 的 snappy 算法,运行性能非常好,压缩比例接近最优。阿里的 SOFA RPC 就使用了 snappy 作为协议层压缩算法。
压缩相关优化
使用变长 varint 表示整数,最高bit位不再表示符号,而是下一个byte是否和当前byte是同一个int的一部分。 对负数,使用zigzag编码,就是将 0 映射到 0,-1 映射到 1,1 映射到 2,-2 映射到 3... 将负数编码成正奇数,正数编码成偶数。解码的时候遇到偶数直接除 2 就是原值,遇到奇数就加 1 除 2 再取负就是原值。
协议例子
Redis 文本协议
Redis 设计了一套专用的文本通讯协议 RESP。Redis设计者认为数据库系统的瓶颈一般不在于网络流量,而是数据库自身内部逻辑处理上。所以使用浪费流量的文本协议,依然可以取得极高的访问性能。 Redis 将所有数据都放在内存,用一个单线程对外提供服务,单个节点跑满一个 CPU 核心时可以达到了 10w/s 的 QPS。
RESP(Redis Serialization Protocol)
协议设计为:
- 单行字符串 以 + 符号开头;
- 多行字符串 以 $ 符号开头,后跟字符串长度;
- 整数值 以 : 符号开头,后跟整数的字符串形式;
- 错误消息 以 - 符号开头;
- 数组 以 * 号开头,后跟数组的长度;
- 单元结束时统一加上回车换行符号
\r\n。 另外,NULL 表示为 $-1,空串 表示为 $0,两个\r\n之间隔的是空串。
示例
客户端向服务器发送 set 指令set author codehole:
1 | |
服务器向客户端回复的响应要支持多种数据结构。比如 OK 响应:
1 | |
错误响应:
1 | |
整数响应:
1 | |
数组响应,这里将hash表的key和value作为数组传递:
1 | |
Redis协议的缺陷
首先,RPC 是建立在 TCP 协议基础上进行消息传递,而 TCP
连接并不总是稳定的。如果因为某些原因断开连接,客户端需要判断服务器是否已经处理了消息还是根本就没收到,没收到的话就需要重新发送请求。如果服务器已经在处理请求了,再重发就会重复执行请求,造成无效的服务器负载。
一种方法,是给每个请求一个全局唯一ID,服务器负责在处理请求时,将ID和处理结果缓存。如果收到重复请求,就直接返回缓存结果。
Redis并没有采用以上方法。Redis的方法显得随意。
Redis只是提供retry_on_timeout选项来让用户自己决定要不要在TimeoutError时进行重试,而不管是否出现重复请求。
稍微分析redis给出的两种错误,就会发现redis在处理逻辑上缺陷。
- 对于ConnectionError,指在建立连接时就出了错,直接进行重新请求。
- 对于TimeoutError,分为读超时,写超时。
写超时
写超时是指内核为当前套接字开辟的写缓存空间已经满了,三种情况导致client缓冲区装满:
- client写方的消息因为网络原因迟迟达到不了读方。无法确定是否server在未来会收到,不可随意重试;
- server老是不读消息,所以没有及时给 client 发送 ack。无法确定是否server在未来会处理,不可随意重试;
- client因为网络原因没有收到 ack。由于server已经处理了请求,再重发请求会重复处理请求。且可能再次出现ack包丢失。
读超时
读超时是指发送完请求,recv迟迟收不到响应,或者只收到部分响应消息。redis并没有进行处理请求是否送达的逻辑。所以不能确定是否有必要重试。
Protobuf 二进制协议
Protobuf 提供了一种描述通讯协议的接口描述语言 IDL,通过编写接口协议,Protobuf 可以自动生成多种语言的 RPC 通讯代码。
Protobuf
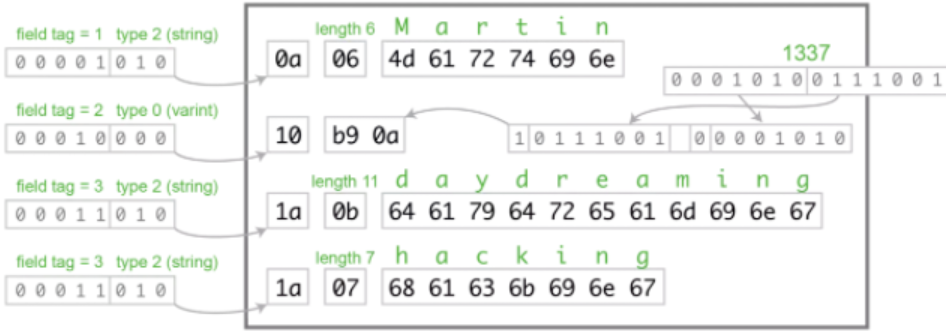
消息被转化为二进制的 key - value 。key 由两部分组成,tag(默认4bits)其值对应 .proto 代码中 message 消息体中字段编号;type(3bits)其值对应8种参数类型。当 message 消息体中字段数超过 16,varint编码也可以处理,只需增加一个byte。
1 | |
最高位的 0 和 1 ,标志着下一个byte是否和当前byte共同表示一个值。
type
- 数值 Protobuf 的整数数值使用 zigzag 编码。浮点数 float 和 double,分别使用 4 个字节和 6 个字节序列化,没有特殊处理。
zigzag:对负数,使用zigzag编码,就是将 0 映射到 0,-1 映射到 1,1 映射到 2,-2 映射到 3... 将负数编码成正奇数,正数编码成偶数。解码的时候遇到偶数直接除 2 就是原值,遇到奇数就加 1 除 2 再取负就是原值。
- 字符串 字符串值使用长度前缀编码 (length-delimited) 。第一个字节是字符串的长度(varint),后面相应长度的字节串就是字符串的内容。
- 可选选项(optional) 二进制流里面可没有使用任何标志为来表示字段是否可选,只是在运行时做了检查。3.0之前,设置 required 选项可以强制检查是否填写某字段,并抛出异常。但3.0之后,所有类型都变成了 optional,移除了 required。
- 列表(repeated) 在消息体中,重复当前 key,得到不同 value 的列表。
示例
定义 proto 文件
1 | |
protoc 编译之后,在cpp中使用:
1 | |
其二进制表示如下图:
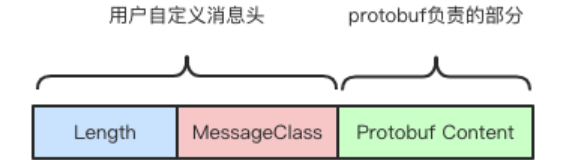
Protobuf传递消息,还需要通过消息头的Length字段确定消息边界,同时传递消息解析需要的 message 消息类型定义。完整消息体如下图:
RPC 客户端
实现 RPC 客户端核心难点在于客户端往往并不是单线程的,我们需要考虑多线程下如何流畅使用客户端而不出现并发问题。 客户端和数据库之间会维护一个连接池,并严格控制有效连接的数量。
锁
每个线程都会访问线程池对象,使用锁来控制数据结构的安全。 考虑到连接都是用来进行相对缓慢的 IO 操作,锁的耗时相比 IO 操作耗时可以忽略不计。所以,在性能许可的前提下,可以为了代码的简洁性,设计粗粒度的锁。
惰性连接
如果一个系统非常闲置,而提前开辟了太多的连接池那是对资源的浪费。使用惰性连接,在需要的时候才会去向数据库申请新的连接。 惰性连接的问题,也是冷启动常见的问题:
- 如果数据库连接参数不正确,需要在收到用户的请求进行显示的数据访问时才能发现。
- 服务器需要热身,早来的请求需要额外付出一次建立连接的代价。
连接健康检查
连接池中管理的连接可能会因为网络原因而损坏断连。连接池需要保持内部管理的连接是可用的。常见检查时机是:
- 线程从连接池中申请连接,在返回连接之前进行检查;
- 线程将连接归还给连接池时,对连接进行检查;
- 线程池定时对连接进行检查。 常见检查方法:
- ping
- 心跳检查 处理问题连接:
- 抛弃连接,连接池的连接数量减一,必要时,重新申请一个连接;
- 重连当前连接。
心跳检测
当客户端长期空闲时,服务器往往会自动关闭连接已减轻资源消耗。 当客户端再次请求时,就会遇到连接已断开的错误。为了避免这种错误,一般有两种方法:
- 遇到连接错误时进行重连重试;
- 通过心跳方式告知服务器不要关闭连接,每间隔一定时间发送心跳检测包,并确认服务端响应。
处理超时
当连接池内连接不够用,造成线程等待空闲连接,产生超时。处理方法一般有三种:
- 永不超时,等不到就接着等,不是一种好的选择。
- 设定超时时限,超时后,就向外部跑出超时异常,中断业务逻辑。
- 申请一个新的连接给调用方。归还连接的时候,若连接池不满就纳入连接池,若连接池满了,就直接销毁。
性能监控
对客户端连接池进行执行时间等信息监控,并提供监听接口,方便输出监控统计信息。
连接多路复用 (multiplexing)
传统的 RPC 客户端,同一个连接上连续的两个请求必须按先后顺序排队获取结果。多路复用的 RPC客户端,同一个链接上可以同时进行多个请求,并且可以乱序执行。 HTTP2.0 就具备了多路复用的连接, gRPC 正是基于 HTTP2.0 的多路复用的连接封装的一款高性能 RPC 框架。 多路复用的连接往往都是线程安全的,它支持多个线程同时写入请求而不会出现并发问题。但是其实现难度和工作量都比较大。
单向请求
有些不是特别重要的请求可以不需要服务器进行响应,客户端在发送完请求之后也不需要等待结果直接返回,这就是 oneway 单向请求,比如日志信息。
Redis-py
1 | |
RPC服务端
主线沿着:单线程同步 -- 多线程同步 -- 多进程同步 -- Preforking同步 -- 单进程异步 -- PreForking异步,进行逐步分析。
单线程同步模型
单线程同步模型的服务器,每次只能处理一个客户端连接,其它连接必须等到前面的连接关闭了才能得到服务器的处理。
多线程同步模型
服务器可以并行处理多个客户端,每一个新连接开启一个新的线程单独进行处理。每个线程都是同步读写(会等待IO阻塞)客户端连接。
多进程同步模型
Python 的 GIL 致使单个进程只能占满一个 CPU 核心,多线程并不能充分利用多核的优势。所以多数 Python 服务器推荐使用多进程模型。 本质就是使用单独进程处理每个新连接。
1 | |
Preforking同步模型
进程要比线程更加吃资源,当连接增加,进程数量增加,操作系统的调度压力也就会增大。 采用 PreForking 模型可以对子进程的数量进行了限制。 PreForking 是通过预先产生多个子进程,当一个连接到来时,每个子进程都有机会拿到这个连接,但是最终只会有一个进程能 accept 。 Prefork 之后,父进程创建的服务套接字引用,每个子进程也会继承一份,它们共同指向了操作系统内核的套接字对象,共享了同一份连接监听队列。 子进程和父进程一样都可以对服务套接字进行 accept 调用,从共享的监听队列中摘取一个新连接进行处理。 子进程拿到连接后,该进程内部可以继续使用单线程或者多线程同步的形式对连接进行处理。
1 | |
单进程异步模型
非阻塞IO
操作系统提供的文件读写操作默认都是同步的,它必须等到数据就绪后才能返回,如果数据没有就绪,它就会阻塞当前的线程。 非阻塞选项意味着,内核套接字的 ReadBuffer 有多少字节,read 操作就返回多少字节;内核套接字的 WriteBuffer 有多少剩余字节空间,write 操作就写多少字节。然后线程可以继续干别的事,稍后再继续进行读写。
事件轮询
select、 poll、epoll 等系统调用API,可以监听查询相关套接字是否有相应的读写事件。而不用轮询每一个套接字文件描述符,反复read和write来检查是否有数据。 事件驱动的方式,比轮询更高效。没有事件时, API 会阻塞,服务器进程无事可做,不需要一直轮询。
读写缓冲区
读
非阻塞 IO 要求用户程序为每个套接字维持一个 ReadBuffer,它和操作系统内核区的 ReadBuffer 不是同一个东西。用户态的 ReadBuffer 是由用户代码来进行控制。 因为读是非阻塞的。当我们想要读取 100 个字节时,我们可能经历了多次 read 调用,第一次读了 10 个字节,第二次 30 个字节,然后又读了 80 个字节。凑够了 100 个字节时,可以解码出一个完整的请求,剩余的 20 个字节又是后面请求消息的一部分。这就是所谓的半包问题。 用户态的 ReadBuffer 就是来保存半包消息的,直到可以解码出一个完整的消息内容。
写
非阻塞写,意味着当我们想要写 100 个字节时,我们可能经历了多次 write 调用,第一次 write 了 10 个字节,第二次 write 了 30 个字节,最后才把剩余的 60 个字节写出去了。 用户态WriteBuffer就是保存第一没写完的90字节、第二次没写完的60字节的,让下一次 write 可以继续写完剩余的部分。
PreForking异步
将 PreForking 机制和事件轮询异步读写结合起来,可以进一步提升系统高并发的能力。 开源框架 Tornado 和开源代理服务器 Nginx 正是采用了多进程 PreForking 异步模型。
Nginx 并发模型
Nginx 的并发模型是一个多进程并发模型,它的 Master 进程在绑定监听地址端口后 fork 出了多个 Slave 进程共同竞争处理这个服务端套接字接收到的很多客户端连接。 Slave 进程会共享同一个处于操作系统内核态的套接字队列。 这是一个生产者消费者模型,生产者是操作系统的网络模块,消费者是多个 Slave 进程,队列中的对象是与客户端连接的套接字。 这种模型在负载均衡上有一个缺点,那就是套接字分配不均匀,「闲者愈闲,忙者愈忙」的状态。 因为当多个进程竞争同一个套接字队列时,操作系统采用了 LIFO 的策略,最后一个来 accept 的进程最优先拿到套接字。越是繁忙的进程越是有更多的机会调用 accept,它能拿到的套接字也就越多。
Node Cluster 并发模型
Node Cluster 为了解决负载均衡问题,规定负责 accept 套接字的只能是 Master 进程,Slave 进程只负责处理客户端套接字请求。父进程就可以将 accept 到的客户端套接字轮流传递给多个 Slave 进程,负载均衡的目标就可以顺利实现了。 使用本地套接字进行进程间通信,将 Master 中完成 accept 的套接字发送到 Slave 子进程中。这里的传递描述符,本质上不是传递,而是复制。子进程收到的描述符和父进程的描述符也不是同一个值。但是父子进程的描述符都会指向同一个内核套接字对象。 本地套接字分为两种,有名套接字和无名套接字。有名套接字会在文件系统指定一个路径名,进程之间都可以通过这个路径来访问本地套接字。无名套接字一般用于父子进程之间,父进程中创建本地套接字,子进程中持有这个套接字的引用。
1 | |
分布式系统中的RPC
当 RPC 服务部署在多个节点上时,客户端得到的是一个服务列表,有多个 IP 端口对。客户端的连接池可以随机地挑选任意的 RPC 服务节点进行连接。 设置服务节点权值,可以控制每个节点被客户端选中的概率。
系统容灾
客户端发起请求,当收到请求的节点挂掉时,将失效节点摘除,放置到失效节点列表中。每隔一段时间检查失效节点是否恢复了,如果恢复了,那就从失效节点中移除,再将节点地址重新加入到有效节点列表中。 判断节点是否失效的方法是,统计在一定时间窗口里出现的错误数量。如果这个数量过大,那就意味着失效了。之所以使用一个时间窗口,主要是防止由于网络的瞬间波动导致的请求异常,造成失效的误判。
请求重试策略
当请求失败时,客户端还要进行重试,但是也不可以无限重试,要有一定的重试策略。降权法是一种策略。 客户端会改变服务节点权值。如果某个节点出现了一次调用错误,可以对该节点进行降权(比如权值减半),直到达到一个最小值。 之所以不应该降到零,那是为了给节点提供一个恢复的机会。被降权的节点后来只要有一次调用成功,那么 weight 值就应该尽快被还原,快速恢复为正常节点。 考虑到网络波动的影响,降权不应太快,导致流量分配波动过快。
服务发现
即,增加物理机器节点时,可以动态变更当前节点列表,而不用手动配置,也不用重启系统。 服务发现技术依赖于服务之间的特殊中间节点。这个节点的作用就是接受服务的注册,提供服务的查找,以及服务列表变更的实时通知功能。它一般使用支持高可用的分布式配置数据库,如 zookeeper/etcd 等。 主要包括三个内容:
- 服务注册:服务节点在启动时将自己的服务地址注册到中间节点
- 服务查找:客户端启动时去中间节点查询服务地址列表
- 服务变更通知:当服务列表变更时,中间节点负责将变更信息实时通知给客户端。
ZooKeeper
ZooKeeper 使用节点存储服务器的地址信息。ZooKeeper 的节点信息以树状结构存储在内存中。使用临时节点机制,支持短时间内断开重连,直到过期时间,若没有向临时节点发送指令,其将被删除。 ZooKeeper 提供了 watch 功能,在节点变动时,客户端可以收到通知,进而重加载服务列表。
一个分布式RPC简介
- 实现出一个 PreForking 异步模型的单机 RPC 服务器,单机服务器对子进程进行管理,信号监听和子进程回收等;
- 然后将服务挂接到 ZooKeeper 的树节点上;
- 再编写客户端消费者从 ZooKeeper 中读取服务节点地址,连接 RPC 服务器进行交互;
- 同时还要监听 ZooKeeper 树节点的变更,在 RPC 服务器节点变动时能动态调整服务列表地址。
gRPC简介
gRPC 选择 HTTP2.0 作为基础协议。HTTP2.0有一些特性,使得传输效率得到提升:
- HTTP2.0 是基于二进制协议的乱序模式 (Duplexing)。这意味同一个连接通道上多个请求并行时,服务器处理快的可以先返回而不用顺序等待。
- HTTP2.0 对请求头的 key/value 做了字典处理,对于常用的 key/value 文本无需重复传送,而是通过引用内部字典的整数索引,显著节省了请求头传输流量。
- HTTP2.0 使用分帧传送。同一个响应会有同一个
stream_id,消息接收端会将具有相同stream_id的消息帧串起来作为一个整体来处理。同一个连接上会有多个流穿插传输,相互之间互不影响。 消息协议使用 protobuf,这在前面有介绍。
- gRPC 默认使用的是异步 IO 模型,底层有一个独立的事件循环。gRPC 使用开源异步事件框架 gevent。gevent 的优势在于可以让用户使用同步的代码编写异步的逻辑。
- gRPC 的一个特色之处在于提供了 Streaming 模式(建立在 HTTP2.0 的 特性3 之上),客户端可以将一连串的请求连续发送到服务器,服务器也可以将一连串连续的响应回复给客户端。Streaming 可以理解为 gRPC 的异步调用。且 gRPC Streaming 为双工通信,可以同时收发消息,当然也可以单向 Streaming。
- gRPC 对异常的处理方式是,在响应头帧里使用 Status 和 Status-Message 两个 header 来标识异常的 code 和原因。
- gRPC 默认不支持重试,如果 RPC 调用遇到错误,会立即向上层抛出错误。若要重试,需要自行设计。
- gRPC 默认支持超时选项,当客户端发起请求时,可以携带参数 timeout 指定最长响应时间,如果 timeout 时间内,服务器还没有返回结果,客户端就会抛出超时异常。
- gRPC 在客户端和服务器都提供了拦截器选项,用户可以通过拦截器拦截请求和响应。比如客户端可以通过拦截器统一在请求头里面增加 metadata,服务器可以通过拦截器来跟踪 RPC 调用性能等。 具体细节,推荐查看 Documentation | gRPC 官方文档。
Thrift简介
1 | |
Thrift 是一个全套的 RPC 框架,支持多种协议,多种传输模式和多种服务器模型。 Transport 层可以选择多种传输模式,Protocol 层可以选择多种协议。
- Thrift 支持多种协议,有文本协议有二进制协议。
- Thrift 支持多种服务器模式,上文所诉的所有模式,都支持。
- Thrift 支持多种传输模式,除了普通的 TCP socket 之外,还有对 ssl 的支持等。通常在传输层使用缓冲模式,在序列化消息时,待完整的消息结构体序列化完成后调用 flush 方法才会将消息传递到对方,有助于提升 IO 效率。
- Thrift 的协议文件要比 gRPC 简洁多了,参数和返回支持很多原生类型。gRPC 则必须使用指定类型,所以输入和输出都要定义 message 结构体。
- Thrift 的超时机制是通过套接字的 timeout 属性来控制读写超时的,gRPC 则是通过定时器来控制的。Thrift 客户端一旦出现超时,就会关闭连接。 具体可参见 Apache Thrift - Concepts 官方文档。 与gRPC对比:
- 在协议的效率上 gRPC 基于 HTTP2.0 协议,这个肯定是无法抗衡 Thrift 纯粹的二进制协议的。
- gRPC 的客户端是多路复用的线程安全的,可以拿过来直接使用。Thrift 的客户端还需要用户自己去封装一个连接池才能使用。
- gRPC 虽然使用了稍微浪费流量的 HTTP2.0 协议,但是考虑到 HTTP 协议的广泛性,支持 HTTP2.0 的代理服务器中间件、负载均衡中间件很多,gRPC 可以直接透明地在这些中间件之间进行转发而无需进行复杂的协议转换工作。Thrift 兼容性就差的太远了。
- Thrift 的源码要简单很多,它的 py 版本几乎全是纯粹的 Python 语言编写的,如果要研究源码的话,还是应该选择 Thrift。gRPC 的源码, c 语言实现,代码量很大,不如看 gRPC 的丰富的文档来得直接。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!