UDA & MixMatch
UDA
使用无监督方法,基本架构类似SimCLR等对比学习模型。
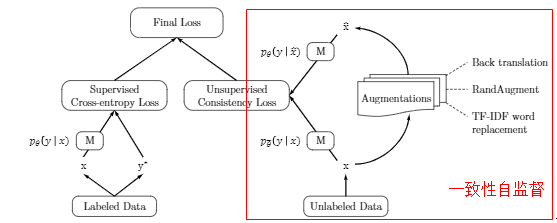
图中M为自定义的模型。
模型损失,UDA部分:
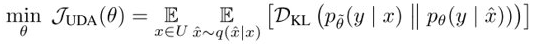
加上监督学习部分:
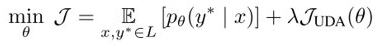
数据增广
图片数据:AutoAugment (RandAugment)、Cutout
文本数据:BackTranslation;基于TF-IDF的词替换,保留重要关键词,替换不重要词
训练方法
Training Signal Annealing (TSA),在训练时逐步释放训练信号:
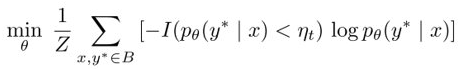
模型在有标注数据上,先拟合预测概率小于 \(\eta_t\) 的数据,逐渐调整 \(\eta_t\),训练先难后易。
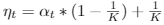
三种策略设置三种 \(\alpha_t\):
- log:
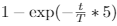
- linear:
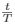
- exp:
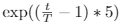
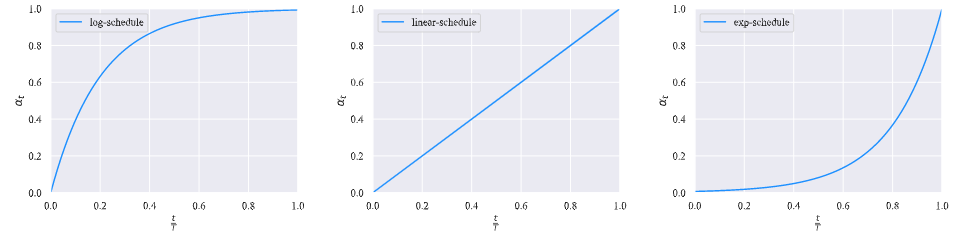
当模型容易过度拟合时,例如,当问题相对容易或标记数据非常有限时,exp-schedule是最合适的。相反,当模型不太可能过度拟合时(例如,当有丰富的标记数据或当模型使用有效的正则化时),log-schedule更合适。
其他处理
- 在使用模型M预测 无标注数据时,使用Confidence-based masking,将概率小于 \(\beta\) 的过滤掉。
- 使用sharpening prediction,大的更大,小的更小。
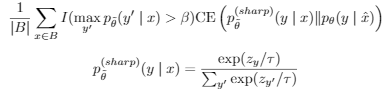
- 可以使用entropy minimization:
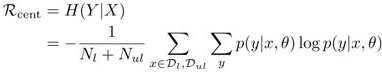
上式中还可以使用MixMatch sharpenig:
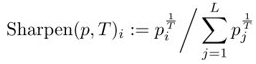
- Domain-relevance Data Filtering:对于外部搜集的数据,对于每个类别,都基于对所有示例进行排序属于该类别的概率,并选择概率最高的示例,构成外部数据。
MixMatch
方法
另一种混合有标签和无标签数据的方法。整体方法如下:

- 对于有标签数据,增广batch个,联合其标签 \(p_b\) 构成 \(\hat{X}\)
- 对无标签数据,每个样本增广K个,通过Label Guessing,取模型对K个样本预测的均值,作为这K个样本的伪标签。构成样本集 \(\hat{U}\).
- Shuffle样本集,将其进行MixUp,得到MixMatch样本集合
然后通过下式计算模型损失,模型为自定义模型:
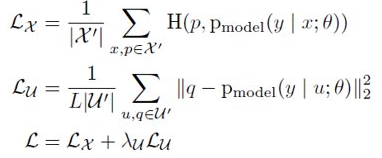
H就表示普通交叉熵损失,若是分类问题时。p、q就是MixMatch中得到的标签。q来自Label Guessing。
细节
使用的方法:
- 数据增广:crop, flip等常见方法
- Label
Guessing:
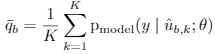
- sharpening:
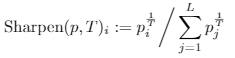
- MixUp:
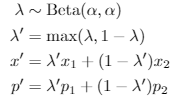
- 模型训练时可采用滑动平均、weight decay等方法
1 | |
消融实验结果:

使用论文中提到的所有方法,才能取得最好的结果。其中MixUp操作的影响最大。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!