文本分类advanced
细粒度分类
多标签问题,每一个类别标签训练一个分类器,忽略了不同类别标签间的联系。
多任务学习,特征提取阶段共享参数,最后几层单独输出。优点是考虑了不同任务间的联系,有联系的类别标签可以一块训练,对不均衡的样本数据有增强作用。
Seq2Seq,把多标签的预测问题看成了一个序列到序列的学习,这样既考虑了标签之间的联系,又可以处理大量标签的问题。
Aspect Based,当有每种Aspect(可理解为主题)相关信息,且每个样本属于特定的Aspect。需要根据属于识别Aspect和分类。
数据处理
可选项有
- 明显噪声处理,例如全篇标点符号,繁体转简体等。
- 分词器选择与自定义词典扩充。使用word2vec初始化时,训练词向量的词表和模型使用的词表一致(分词器不要混用)。
- 分词与分字特征可分别利用,训练不同模型集成。
- word2vec 与 bert类模型提取的特征,拼接,输入下游任务设计。
- EDA:同义词替换,随机删除、交换位置等。翻译效果不稳定。
不平衡数据:
- 上采样:罕见类数据随机打乱作为扩充。同义词替换,随机删除、交换位置等扩充。使用扩充数据时,不要连续使用增强后的数据,可以相隔一两个epoch使用。
- 下采样,数据利用率不高。
- 标签权重加入loss计算。实际效果是,不一定带来提高,尤其是复杂的分类任务,但可选。
- Label smoothing。约束神经网络本身对错误标签的极大惩罚(loss在bp时,回传一般是label与predict之差)。提高泛化力。
- focal loss。损失计算偏向于没有正确分类的输出修正(理论上)。
使用预训练特征提取器时(EMLo,BERT类):
- 使用外部相似预料进行模型pretrain。
- 长度有限制的模型,可以尝试随机删除句子。(观测数据,如果开头和结尾重要,就删中间部分)
模型
- Bi-GRU + Multi Capsule
- Bi-GRU + Multi ResNet
- HAN + Attention
- Transformer Encoder + Convolutional
Seq2Seq
解码器三种思路:
- 使用LSTM(或其他)每一步(#不同种类标签数)的output表示不同种类标签的预测输出
- Beam Search尽量好的输出预测序列(只是在inference阶段使用)。
- Global Embedding(在训练阶段使用),类似Beam Search:
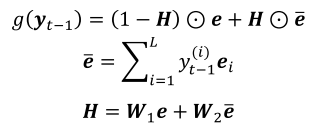
- y为预测标签分布(output softmax后的输出),e为每一步(#每一种标签)的output;g为global embedding的输出,代替LSTM的hidden state,进行序列解码任务。
- 【SGM: Sequence Generation Model for Multi-Label Classification】
Aspect Based Sentiment Analysis
抽取content特征,Aspect信息,使用各种方法attention到和输出label相关的信息。比如:
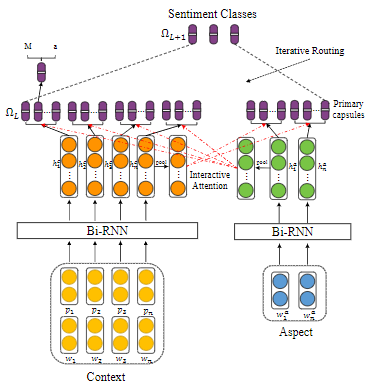
【Capsule Network with Interactive Attention for Aspect-Level Sentiment Classification】
另一种思路,树形(层级搜索):
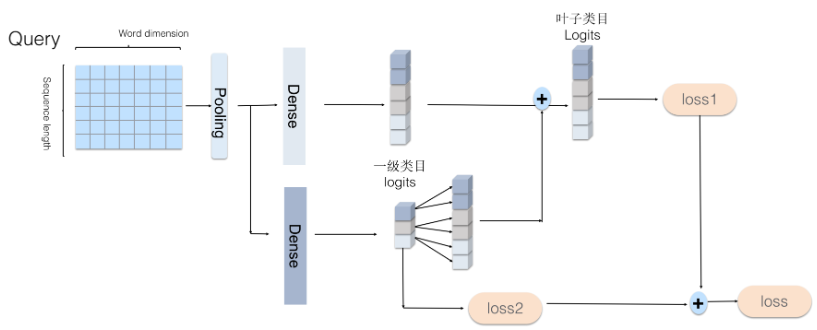
上图中加入aspect信息到输入层
模型训练
- Warm up:学习率先增加,然后减小。线性增加即可。也可以使用one cycle fitting,让学习率在一个epoch内,线性增加到一个较大值,然后线性减小为初始的较小学习率。绘制loss--lr曲线图,摘到loss的变化较大处的lr的十分之一。【A DISCIPLINED APPROACH TO NEURAL NETWORK HYPER-PARAMETERS: PART 1 – LEARNING RATE, BATCH SIZE, MOMENTUM, AND WEIGHT DECAY】
- 找到合适学习率后(实验), 将模型迭代足够多次(loss可能在一段时间不降之后,突然下降),保留验证正确率最高的模型。加载上一个最优模型,学习率设为当前1/10(实验),继续训练模型,保留验证正确率最高的模型。加载上一个最优模型,去掉正则化策略(dropout 等,如果有),学习率再降低,训练到收敛。
- 先调整学习率,再调整其他模型超参数。
- sequence模型,序列长度要选取合适。不损失太多信息。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!