文本分类深度学习方法
fastText
官方Git
fastText是Facebook AI Research在16年开源的一个文本分类器。 其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。
- 适合大型数据+高效的训练速度:在使用标准多核CPU的情况下10分钟内处理超过10亿个词
- 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。
- fastText专注于文本分类,在许多标准问题上有较好的表现(例如文本倾向性分析或标签预测)。
fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。 fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
基本框架:
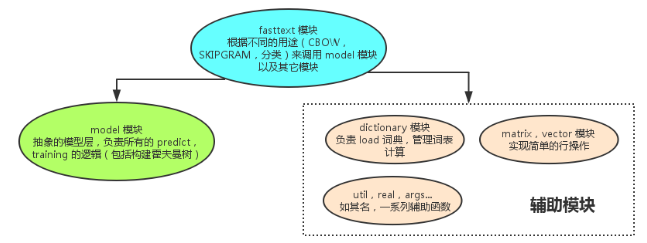
字符n-gram
将输入序列(一整句话,而不是CBOW的窗口输入),进行字符n-gram。n-gram一定程度上克服了CBOW这类bag of words模型无视了语序的缺点。
罕见词仍然可以被分解成字符n-gram。
1 | |
隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。
层次 Softmax 分类
基本思想是使用树的层级结构替代扁平化的标准Softmax,使得在计算 P(y=j) 时,只需计算一条路径上的所有节点的概率值,无需在意其它的节点。
层次 Softmax的原理在文本表示笔记部分,在word2vec的优化部分进行了说明。
一般情况下,使用fastText进行文本分类的同时也会产生词的embedding,即embedding是fastText分类的产物。
用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段同类文本的向量应该是相似的。
CNN
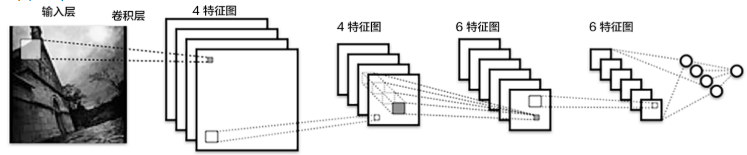
卷积神经网络经常用来处理具有类似网格拓扑结构(grid-like topology)的数据。
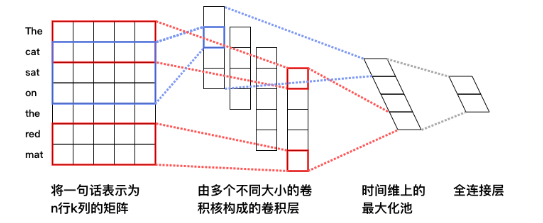
应用于文本处理很简单。
RNN
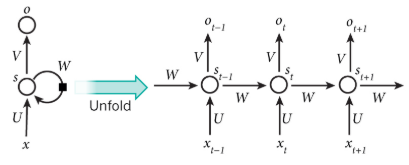 \[
h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)
\] 其中\(W_{xh}\)是输入到隐层的矩阵参数,\(W_{hh}\)是隐层到隐层的矩阵参数,\(b_h\)为隐层的偏置向量(bias)参数,\(\sigma\)为\(sigmoid\)函数。
\[
h_t=f(x_t,h_{t-1})=\sigma(W_{xh}x_t+W_{hh}h_{t-1}+b_h)
\] 其中\(W_{xh}\)是输入到隐层的矩阵参数,\(W_{hh}\)是隐层到隐层的矩阵参数,\(b_h\)为隐层的偏置向量(bias)参数,\(\sigma\)为\(sigmoid\)函数。
一般提取最后一个时刻的隐层状态作为句子表示进而使用分类模型。
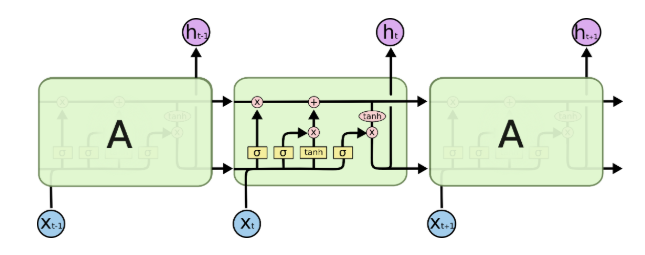
LSTM
LSTM增加了记忆单元𝑐、输入门𝑖、遗忘门𝑓及输出门𝑜。这些门及记忆单元组合起来大大提升了循环神经网络处理长序列数据的能力。
\(i_t = \sigma{(W_{xi}x_t+W_{hi}h_{t-1}+b_i)}\)
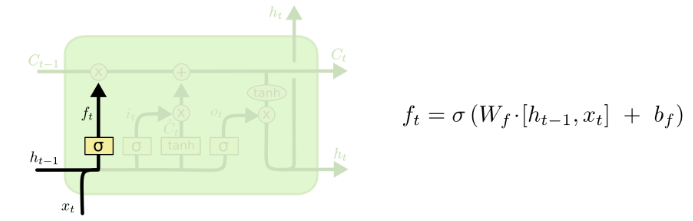
$ f_t = (W_{xf}x_t+W_{hf}h_{t-1}+b_f) $
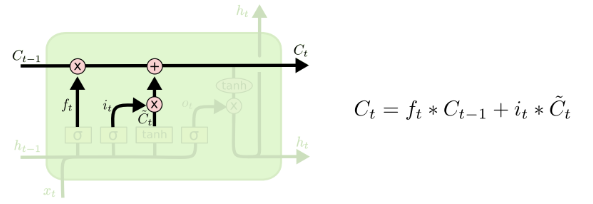
$ c_t = f_t c_{t-1}+i_t tanh(W_{xc}x_t+W_{hc}h_{t-1}+b_c) $
$o_t = (W_{xo}x_t+W_{ho}h_{t-1}+b_o) $
$ h_t = o_t tanh(c_t) $
其中,\(i_t, f_t, c_t, o_t\)分别表示输入门,遗忘门,记忆单元及输出门的向量值,带角标的\(W\)及\(b\)为模型参数,\(tanh\)为双曲正切函数,\(\odot\)表示逐元素(elementwise)的乘法操作。
输入门控制着新输入进入记忆单元\(c\)的强度,遗忘门控制着记忆单元维持上一时刻值的强度,输出门控制着输出记忆单元的强度。
三种门的计算方式类似,但有着完全不同的参数,它们各自以不同的方式控制着记忆单元\(c\):
Forget Gate:
Input Gate:
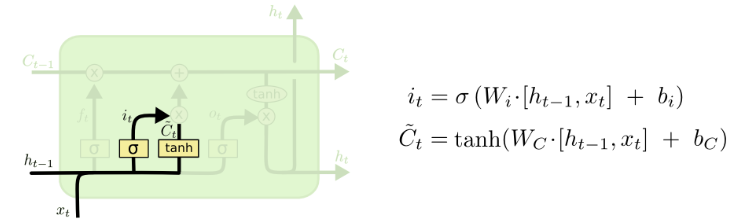
更新Cell state:
Output Gate:
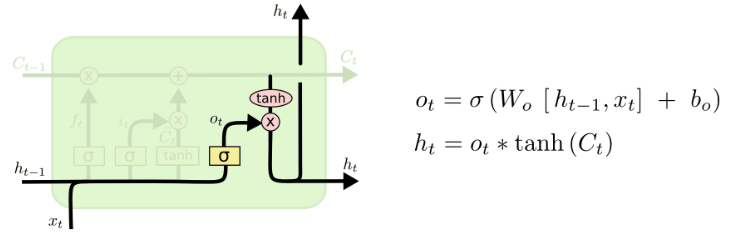
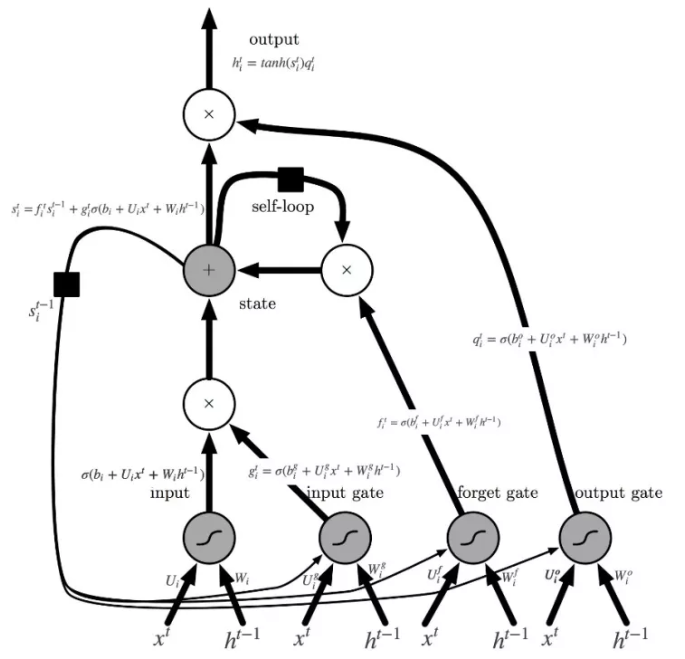
图中带有方块的线,没有在计算中直接公式求解,s即cell state,通过hidden state的计算,从而进行信息传递。详细内容查找神经网络笔记。
GRU
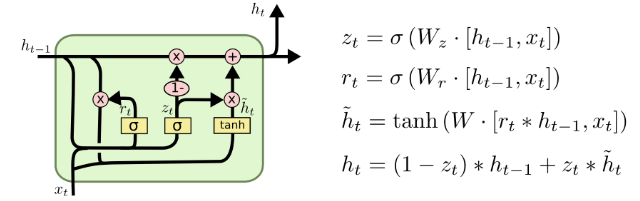
- 将忘记门和输入门合并成为一个单一的更新门
- 同时合并了数据单元状态和隐藏状态
- 结构比LSTM的结构更加简单
RCNN
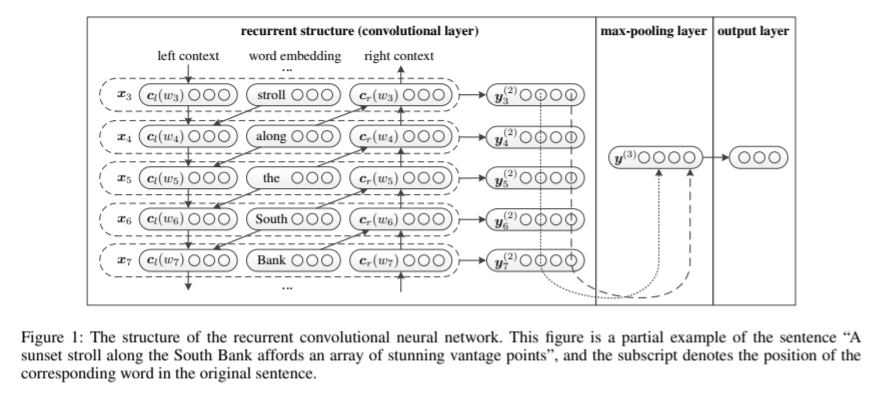
卷积层建立在一个BiRNN模型之上,通过正向和反向循环来构造一个单词的下文和上文,然后输入CNN,如下式:
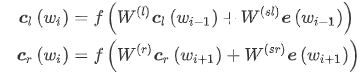
得到单词的上下文表示之后,用拼接的方式来表示这个单词.
然后通过max pooling层和全连接层,得到最后的输出。这一部分相当于文本表示的学习。
将该词向量放入一个单层神经网络中,得到所谓的潜语义向量(latent semantic vector),这里卷积层的计算结束了,时间复杂度仍是O(n)。接下来进行池化层,这里采用max-pooling可以将向量中最大的特征提取出来,从而获取到整个文本的信息。池化过程时间复杂度也是O(n),所以整个模型的时间复杂度是O(n)。得到文本特征向量之后,进行分类。
Quasi-RNN
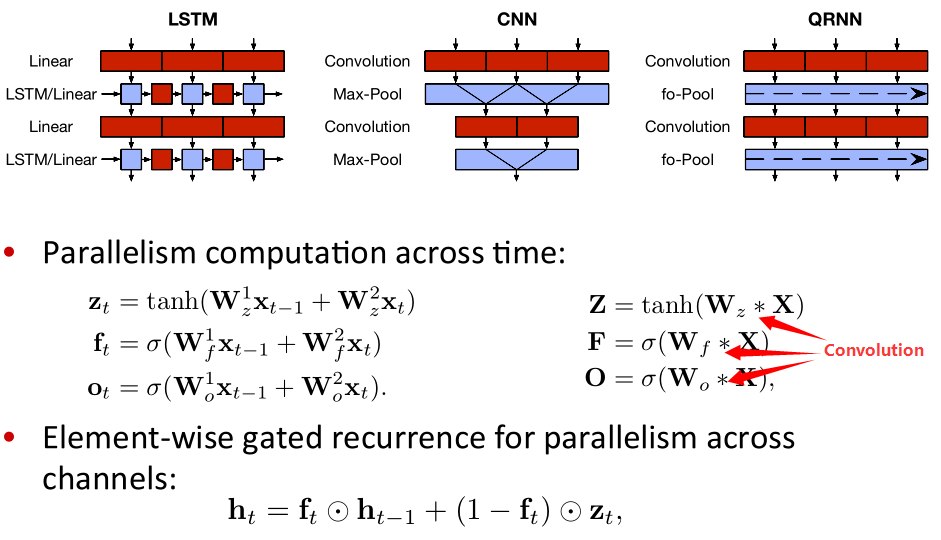
框图显示了QRNN的计算结构与典型值的比较LSTM和CNN架构。 红色表示卷积或矩阵乘法; 连续的块意味着这些计算可以并行进行。 蓝色表示无参数功能沿通道/特征维度并行运行的对象。 LSTM可以分解为(红色)线性块和(蓝色)element-wise部分,但每个时间步的计算仍取决于上一个时间步的结果。
fo-Pool指的是以下公式,包括forget 和 output 的h计算方式
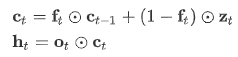
而上图中
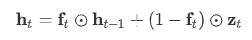
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!