文本分类传统机器学习方法
朴素贝叶斯模型与中文文本分类
\[ P(Y|X)=\frac{P(X|Y)P(Y)}{P(X)} \]
\[ P(Y,X) = P(Y|X)P(X)=P(X|Y)P(Y) \]
条件独立假设的一个缺陷是,失去了词语之间的顺序信息。这就相当于把所有的词汇扔进到一个袋子里随便搅和,贝叶斯都认为它们一样。因此这种情况也称作词袋模型(bag of words)。
优化
- 取对数
- 转换为权重,每个词一个重要度,而不是计数
- 选取top k关键词
- 分割样本,根据文本长度选择不同数量的关键词数量,文本长时选取多一些
- 位置权重:比如在标题中的关键词,权重大一些
Logistic Regression
Logistic 回归并非最强大的分类算法,它可以很容易地被更为复杂的算法所超越,另一个缺点是它高度依赖正确的数据表示。但是其计算效率是相对较高的。不能用 logistic 回归来解决非线性分类问题,因为它的决策边界是线性的。
SVM
找到具有最小间隔的样本点,然后拟合出一个到这些样本点距离和最大的线段/平面。
目标函数:
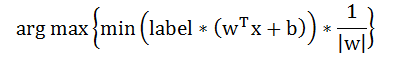
优化问题可推导出:【过程见机器学习笔记】
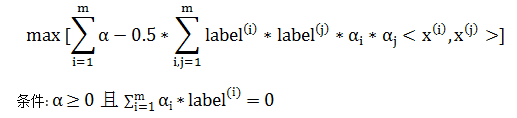
得到回归系数:
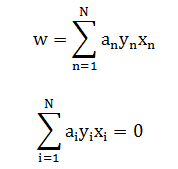
实验
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!