ChatBot Simple Notes
基于检索技术的模型 VS 生成式模型
基于检索技术的模型较为简单,主要是根据用户的输入和上下文内容,使用了知识库(存储了事先定义好的回复内容)和一些启发式方法来得到一个合适的回复。启发式方法简单的有基于规则的表达式匹配,复杂的有一些机器学习里的分类器。这些系统不能够生成任何新的内容,只是从一个固定的数据集中找到合适的内容作为回复。
对于基于检索技术的模型,回复的内容语法上较为通顺,较少出现语法错误, 不能结合上下文给出回复。
生成式模型典型的有基于机器翻译模型的,与传统机器翻译模型不同的是,生成式模型的任务不是将一句话翻译成其他语言的一句话,而是输出一个回答(response)。
短对话 VS 长对话
处理长对话内容将更加困难,这是因为你需要在当前对话的情境下知道之前的对话说过什么。
开放域 VS 特定领域
面向开放域的聊天机器人技术面临更多困难,这是因为会话可能涉及的面太广,没有一个清晰的目标和意图。
面向特定领域的相关技术则相对简单一些,这是因为特定领域给会话的主题进行了限制,目标和意图也更加清晰,典型的例子有客服系统助手和购物助手。
面临的挑战
如何结合上下文信息
聊天机器人系统通常需要利用一些上下文信息(Context),这里的上下文信息包括了对话过程中的语言上下文信息和用户的身份信息等。在长对话中人们关注的是之前说了什么内容以及产生了什么内容的交换,这是语言上下文信息的典型。
语义一致性
机器人面对相同语义而不同形式的问题应该给予一致的回复,例如这两个问题[How old are you?]和[What’s your age?],很有可能不是一个个体。最大的原因在于训练模型的数据来源于大量不同的用户,这导致机器人失去了固定统一的人格。
对话模型的评测
在开放域中的对话系统没有一个清晰的优化目标。用于机器翻译的评测指标BLEU不能适用于此,是因为它的计算基础是语言表面上的匹配程度,而对话中的回答可以是完全不同词型但语义通顺的语句。
意图和回复多样性
生成式模型中的一个普遍问题是,它们可能生成一些通用的回答,例如[That’s great!]和[I don’t know]这样的可以应付许多的用户询问。
另外,人们在对话过程中的回复与询问有一定特定关系,是有一定意图的,而许多面向开放域的机器人不具备特定的意图。
目前深度学习的价值主要体现在能够获取大量数据的特定领域。目前一个无法做的事情是产生一个有意义的对话。
公开语料
- dgk_shooter_min.conv.zip 中文电影对白语料,噪音比较大,许多对白问答关系没有对应好
- The NUS SMS Corpus 包含中文和英文短信息语料,据说是世界最大公开的短消息语料
- ChatterBot中文基本聊天语料 ChatterBot聊天引擎提供的一点基本中文聊天语料,量很少,但质量比较高
- Datasets for Natural Language Processing 这是他人收集的自然语言处理相关数据集,主要包含Question Answering,Dialogue Systems, Goal-Oriented Dialogue Systems三部分,都是英文文本。可以使用机器翻译为中文,供中文对话使用
- 小黄鸡 据传这就是小黄鸡的语料:xiaohuangji50w_fenciA.conv.zip (已分词) 和 xiaohuangji50w_nofenci.conv.zip (未分词)
- 白鹭时代中文问答语料 由白鹭时代官方论坛问答板块10,000+ 问题中,选择被标注了“最佳答案”的纪录汇总而成。人工review raw data,给每一个问题,一个可以接受的答案。目前,语料库只包含2907个问答。(备份)
- Chat corpus repository chat corpus collection from various open sources 包括:开放字幕、英文电影字幕、中文歌词、英文推文
- 保险行业QA语料库 通过翻译 insuranceQA产生的数据集。train_data含有问题12,889条,数据 141779条,正例:负例 = 1:10; test_data含有问题2,000条,数据 22000条,正例:负例 = 1:10;valid_data含有问题2,000条,数据 22000条,正例:负例 = 1:10
基于内容检索式的聊天机器人
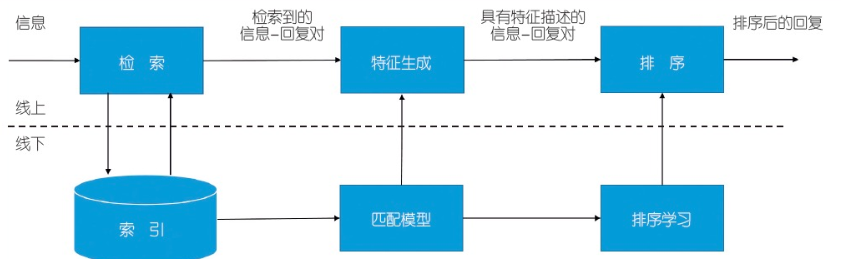
检索式模型的输入是一段上下文内容 C (会话到目前未知的内容信息) 和一个可能作为回复的候选答案;模型的输出是对这个候选答案的打分。寻找最合适的回复内容的过程是:先对一堆候选答案进行打分及排序,最后选出分值最高的那个最为回复。
Retrieval-Based Conversational Model in Tensorflow:https://github.com/dennybritz/chatbot-retrieval/
数据可以在Google Drive文件夹中找到:https://drive.google.com/open?id=1RIIbsS-vxR7Dlo2_v6FWHDFE7q1XPPgj
数据文件需要:
1 | |
数据集为Ubuntu对话数据集。chatbot-retrieval/notebooks/Data Exploration.ipynb文件为数据分析。
Ubuntu对话数据集
训练集
训练数据有1,000,000条实例,其中一半是正例(label为1),一半是负例(label为0,负例为随机生成)。
每条实例包括一段上下文信息(context),即Query;和一段可能的回复内容,即Response;Label为1表示该Response确实是Query的回复,Label为0则表示不是。
数据集的生成使用了NLTK工具,包括分词、stemmed、lemmatized等文本预处理步骤;同时还使用了NER技术,将文本中的实体,如姓名、地点、组织、URL等替换成特殊字符。这些文本预处理并不是必须的,但是能够提升一些模型的性能。
query的平均长度为86个word,而response的平均长度为17个word。
测试集和验证集
与训练集不同,在测试集和验证集中,对于每一条实例,有一个正例和九个负例数据(也称为干扰数据)。模型的目标在于给正例的得分尽可能的高,而给负例的得分尽可能的低。
负例生成方法可以参考谷歌的Smart Reply则使用了聚类技术,将每个类的中取一些作为负例,这样生成负例的方式显得更加合理(考虑了负例数据的多样性,同时减少时间开销)。
评测
模型的评测recall@k,即经模型对候选的response排序后,前k个候选中存在正例数据(正确的那个)的占比;显然k值越大,该指标会越高。
Dual Encoder LSTM Network
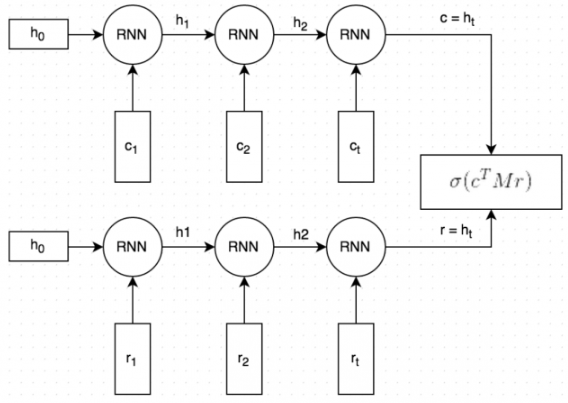
大致的流程如下:
Query和Response都是经过分词的,分词后每个词embedded为向量形式。初始的词向量使用GloVe vectors,之后词向量随着模型的训练会进行fine-tuned(实验发现,初始的词向量使用GloVe并没有在性能上带来显著的提升)。
Query和Response经过相同的RNN(word by word)。RNN最终生成一个向量表示,捕捉了Query和Response之间的[语义联系](图中的c和r);这个向量的维度是可以指定的,这里指定为256维。
将向量c与一个矩阵M相乘,来预测一个可能的回复r’。如果c为一个256维的向量,M维256*256的矩阵,两者相乘的结果为另一个256维的向量,相当于一个生成式的回复向量。矩阵M是需要训练的参数。
通过点乘的方式来预测生成的回复r’和候选的回复r之间的相似程度,点乘结果越大表示候选回复作为回复的可信度越高;之后通过sigmoid函数,转成概率形式。图中把第(3)步和第(4)步结合在一起了。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!