单节点Hadoop
1.安装JDK
| sudo apt-get update
sudo apt-get install default-jdk
java -version
|
查看安装路径
2.设定 SSH无密码登入
| sudo apt-get install ssh
sudo apt-get install rsync
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
ll ~/.ssh
|
为了无密码登录本机,加入公匙到许可证文件
| cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
|
| systemctl restart sshd.service
|
3.下载安装Hadoop
| wget https:
sudo tar -zxvf hadoop-2.9.2.tar.gz
sudo mv hadoop-2.9.2 /usr/local/hadoop
ll /usr/local/hadoop
|
4.设定Hadoop环境变数
修改~/.bashrc
输入下列内容
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
|
让~/.bashrc修改生效
5.修改Hadoop组态设定档
Step1 修改hadoop-env.sh配置文件
| sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
|
输入下列内容:
| export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
|
Step2 修改core-site.xml,设置HDFS名称
| sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
|
在之间,输入下列内容:
| <configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
|
Step3 修改yarn-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
|
在之间,输入下列内容:
| <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
|
Step4 修改mapred-site.xml,监控Map和reduce程序的JobTracker
| sudo cp /usr/local/hadoop/etc/hadoop/mapred-site.xml.template /usr/local/hadoop/etc/hadoop/mapred-site.xml
|
| sudo gedit /usr/local/hadoop/etc/hadoop/mapred-site.xml
|
在之间,输入下列内容:
| <property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
|
Step5 修改hdfs-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
在之间,输入下列内容:
dfs.replication设置blocks在其他节点的备份数量
| <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
|
6.建立与格式化HDFS
目录
| sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
|
| sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
|
| sudo chown ray:ray -R /usr/local/hadoop
|
chown要根据当前用户名进行修改
格式化
7.启动Hadoop
启动start-dfs.sh,再启动 start-yarn.sh
| start-dfs.sh
start-yarn.sh
|
或 启动全部
查看目前所执行的行程
stop-dfs.sh
stop-yarn.sh
stop-all.sh
8.开启Hadoop
ResourceManagerWeb接口
Hadoop ResourceManager Web接口网址 http://localhost:8088/
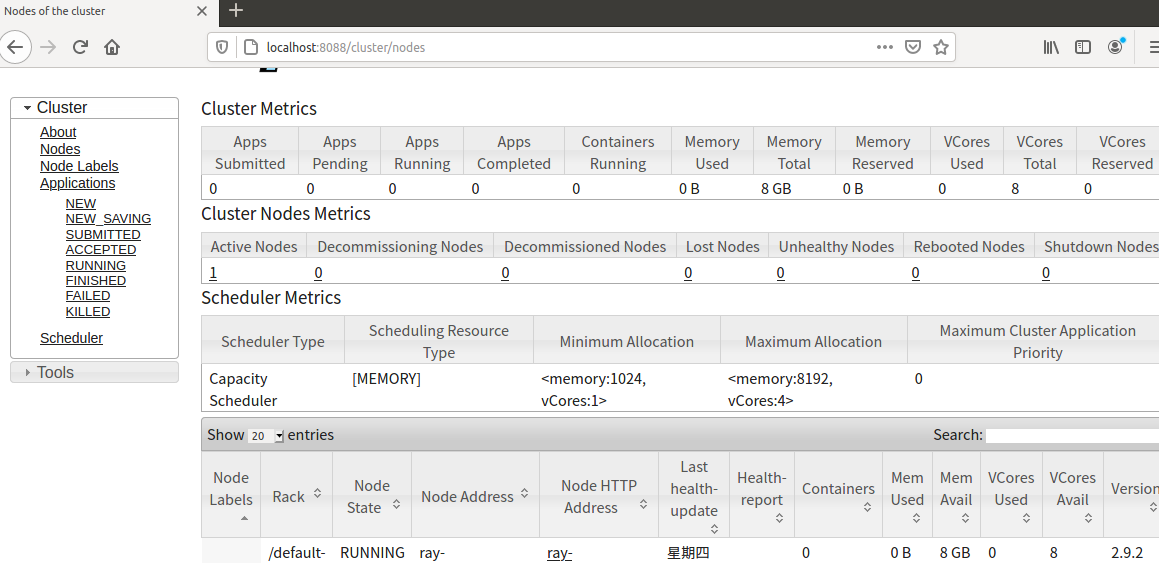 image
image
9.NameNode HDFS
Web接口
开启HDFS Web UI网址 http://localhost:50070/
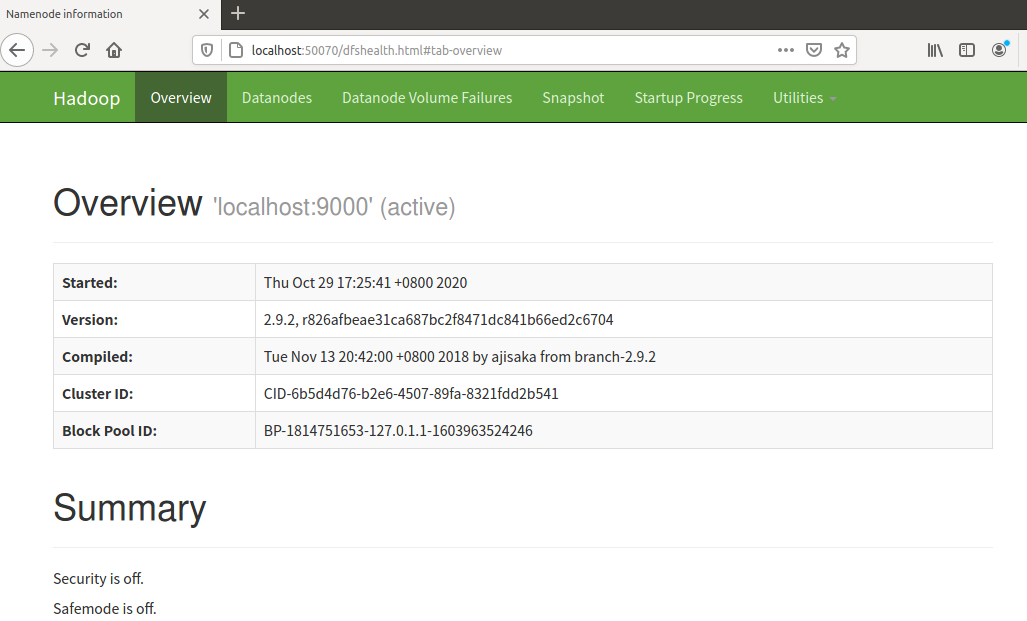 image
image
多节点Hadoop
- 由多台电脑组成:有一台主要的电脑master,在HDFS担任NameNode角色,在MapReduce2(YARN)担任ResourceManager角色
- 有多台的电脑data1、data2、data3,在HDFS担任DataNode角色,在MapReduce2(YARN)担任NodeManager角色
Hadoop Multi NodeCluster规划,整理如下表格:
| master |
192.168.0.100 |
NameNode |
ResourceManager |
| data1 |
192.168.0.101 |
DataNode |
NodeManager |
| data2 |
192.168.0.102 |
DataNode |
NodeManager |
| data3 |
192.168.0.103 |
DataNode |
NodeManager |
1复制Single Node
Cluster到data1
将之前所建立的Single Node Cluster VirtualBox
hadoop虚拟机器复制到data1
2设定data1伺服器
编辑网路设定档设定固定IP
| sudo gedit /etc/network/interfaces
|
输入下列内容 :
| # interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.0.101
netmask 255.255.255.0
network 192.168.0.0
gateway 192.168.0.1
dns-nameservers 192.168.0.1
|
| sudo vim /etc/NetworkManager/NetworkManager.conf
|
将managed=false修改成managed=true
| sudo service network-manager restart
|
重启
设定hostname
输入下列内容:
设定hosts档案
| 127.0.0.1 localhost
127.0.1.1 hadoop
192.168.0.100 master
192.168.0.101 data1
192.168.0.102 data2
192.168.0.103 data3
# The following lines are desirable for IPv6 capable hosts
::1 ip6-localhost ip6-loopback
fe00::0 ip6-localnet
ff00::0 ip6-mcastprefix
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
|
修改core-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/core-site.xml
|
在之间,输入下列内容:
| <property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
|
修改yarn-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/yarn-site.xml
|
在之间,输入下列内容:
| <property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8050</value>
</property>
|
修改mapred-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop /mapred-site.xml
|
在之间,输入下列内容:
| <property>
<name>mapred.job.tracker</name>
<value>master:54311</value>
</property>
|
修改hdfs-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
在之间,输入下列内容:
| <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
|
3复制data1伺服器至data2、data3、master
4设定data2、data3伺服器
设定data2固定IP
| sudo gedit /etc/network/interfaces
|
输入下列内容
| # interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.0.102
netmask 255.255.255.0
network 192.168.0.0
gateway 192.168.0.1
dns-nameservers 192.168.0.1
|
设定hostname
输入下列内容:
设定data3固定IP
| sudo gedit /etc/network/interfaces
|
输入下列内容
| # interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.0.103
netmask 255.255.255.0
network 192.168.0.0
gateway 192.168.0.1
dns-nameservers 192.168.0.1
|
设定hostname
输入下列内容:
5设定master伺服器
设定master固定IP
| sudo gedit /etc/network/interfaces
|
输入下列内容
| # interfaces(5) file used by ifup(8) and ifdown(8)
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet static
address 192.168.0.100
netmask 255.255.255.0
network 192.168.0.0
gateway 192.168.0.1
dns-nameservers 192.168.0.1
|
设定hostname
输入下列内容:
修改hdfs-site.xml
| sudo gedit /usr/local/hadoop/etc/hadoop/hdfs-site.xml
|
在之间,输入下列内容:
| <property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
|
设定master档案
| sudo gedit /usr/local/hadoop/etc/hadoop/master
|
输入下列内容:
设定slaves档案
| sudo gedit /usr/local/hadoop/etc/hadoop/slaves
|
输入下列内容:
6
master连线至data1、data2、data3建立HDFS目录
master SSH连线至data1并建立HDFS目录
| ssh data1
# 删除hdfs目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
# 创建datanode目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 更改所有者为当前用户
sudo chown ray:ray -R /usr/local/hadoop
|
回到master端
master SSH连线至data2并建立HDFS目录
| ssh data2
# 删除hdfs目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
# 创建datanode目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 更改所有者为当前用户
sudo chown ray:ray -R /usr/local/hadoop
|
回到master端
master SSH连线至data3并建立HDFS目录
| ssh data3
# 删除hdfs目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
# 创建datanode目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
# 更改所有者为当前用户
sudo chown ray:ray -R /usr/local/hadoop
|
回到master端
7建立与格式化NameNode
HDFS目录
| # 删除hdfs目录
sudo rm -rf /usr/local/hadoop/hadoop_data/hdfs
# 创建datanode目录
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
# 更改所有者为当前用户
sudo chown ray:ray -R /usr/local/hadoop
|
格式化NameNode HDFS目录
8启动Hadoop Multi Node
cluster
启动start-dfs.sh,再启动 start-yarn.sh
| start-dfs.sh
start-yarn.sh
|
或 启动全部
查看目前所执行的行程
停止
stop-dfs.sh
stop-yarn.sh
stop-all.sh
9开启Hadoop
Resource-Manager Web介面
http://master:8088/
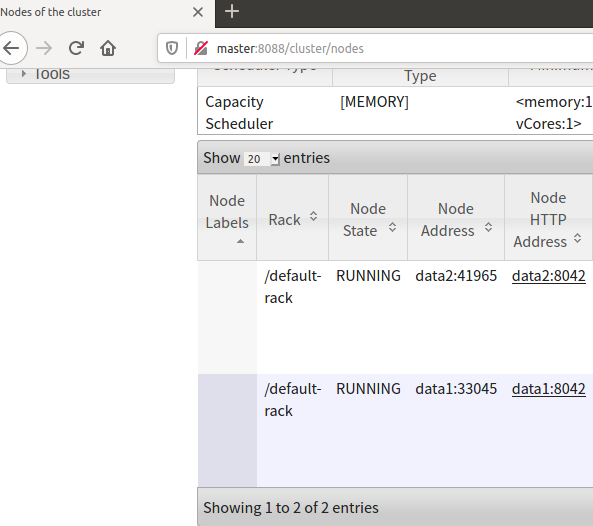 image
image
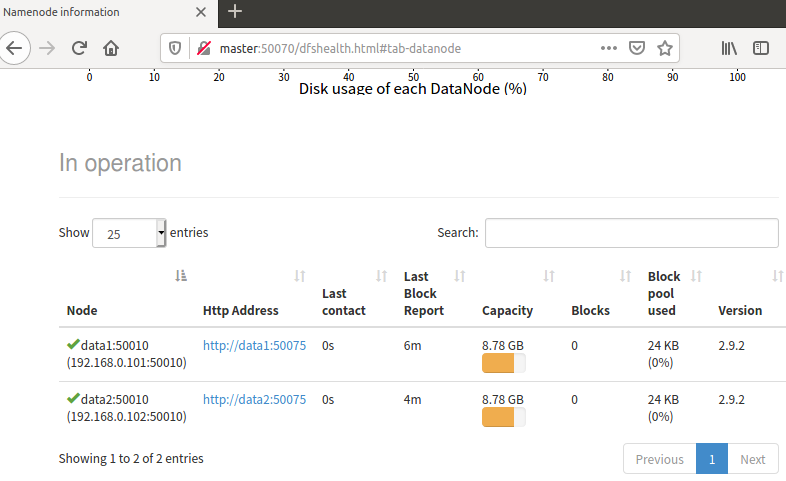
10开启NameNodeWeb介面
HDFS Web UI网址 http://master:50070/
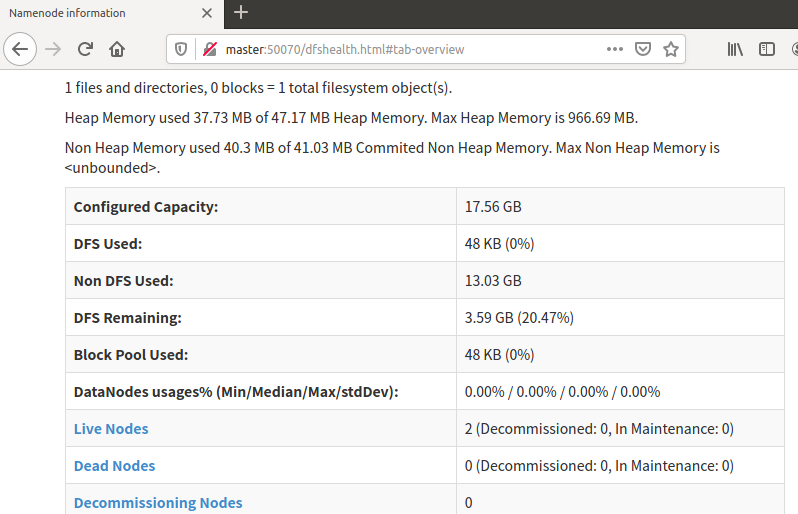 image
image
 image
image
常用命令
| hadoop fs -mkdir
hadoop fs -ls
hadoop fs -copyFromLocal # 复制到hdfs,提醒有重名
hadoop fs -put # 复制到hdfs,但是直接覆盖重名
hadoop fs -cat
hadoop fs -copyToLocal # 复制到本地,提醒有重名
hadoop fs -get # 复制到本地,但是直接覆盖重名
hadoop fs -cp
hadoop fs -rm
|
pyspark
scale
| tar xvf scala-2.11.12.tgz
sudo mv scala-2.11.12 /usr/local/scala
sudo gedit .bashrc
|
|
export SCALA_HOME=/usr/local/scala
export PATH=$PATH:$SCALA_HOME/bin
|
spark
| tar xvf spark-2.4.7-bin-without-hadoop.tgz
sudo mv spark-2.4.7-bin-without-hadoop /usr/local/spark
sudo gedit .bashrc
|
写入
| export SPARK_HOME=/usr/local/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
|
| cd /usr/local/spark/
cp ./conf/spark-env.sh.template ./conf/spark-env.sh
sudo gedit ./conf/spark-env.sh
|
写入
| export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop/bin/hadoop classpath)
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export PYSPARK_PYTHON=/usr/bin/python3
export PYSPARK_DRIVER_PYTHON=/usr/bin/ipython3
|
使用HDFS中文件时,先要启动Hadoop
测试
master机器上
| cd ~
mkdir wordcount/input -p
cp /usr/local/hadoop/LICENSE.txt ~/wordcount/input
|
| hadoop fs -mkdir -p /user/ray/wordcount/input
cd ~/wordcount/input
hadoop fs -copyFromLocal LICENSE.txt /user/ray/wordcount/input
hadoop fs -ls /user/ray/wordcount/input
|