CRF--SimpleNote
Motivation
NER标注输出不仅仅是简单的分类,而是具有一定关联规律的标注输出。CRF正是输出这种结构化结果的一种算法。
结合HMM(状态转移和状态释放)和最大熵模型(log linear model建模特征函数,寻找最优的条件概率),在MEMM的基础上,建立隐变量X的概率无向图解决了MEMM的局部归一化问题。
CRF loss in Deep Learning
loss的优化目标是使得模型输出的最优路径和groud truth路径尽量接近。即,最大化最优路径概率。
最优路径概率定义为,
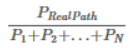
在CRF loss中,Pi通过两组变量求得,Emission Score和Transition Score(传统CRF中的特征函数)。
Emission Score:对应神经网络输出的hidden state。可视为每一步输出标签的分类概率分布预测,每一步输出维度为[#tags, 1]。
Transition Score:对应CRF层中定义的状态转移权重矩阵。保存在CRF layer中,[#tags, #tags]
两者在深度模型中都是作为权重变量来优化学习的。
深度模型中的优化目标实际实现为:
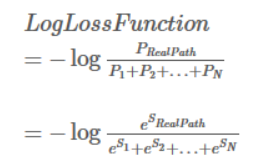
分子计算可以简单计算发现,就是当前路径的Emission Score和Transition Score沿路径之和。计算难点在于分母,可以通过递归实现其多分支结构计算。
递归过程:
维护两个记录列表:obs和 previous。previous存储了之前步骤的结果,obs代表当前状态可能的输出选择。
以step 0到step 1为例:
扩展到#tags维度,沿着1轴,和transition matrix同维度
对score的每一列取指数,求和,在取对数,得到新的previous
递归计算,直到达到最后一个时间步。
求得分母
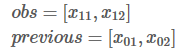
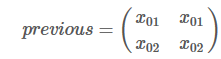
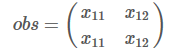
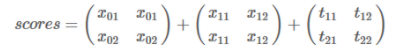
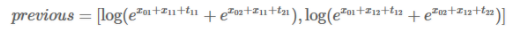
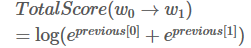
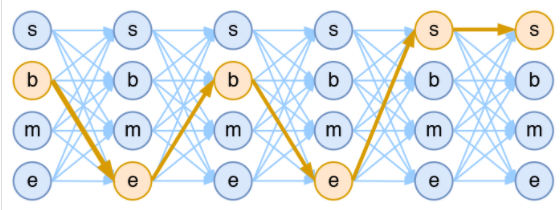
最佳路径导出Viterbi
动态规划算法,过程类似loss中求分母的部分,但是状态转移方程(动态规划)不同。
同样以step 0到step 1为例:
扩展到#tags维度,沿着1轴,和transition matrix同维度
previous保存的累计最优得分状态变化为:
然后保存这一轮状态转移中,不同step 0状态下对应的最优得分,以及最优得分对应的step 1最优状态。即,保存两个列表,在下一次转移时,将最优得分和对应的最优状态append到结果中。

根据最后一步的最优得分,回溯重构出最优路径。
对比MEMM
虽然CRF在MEMM的基础上,建立隐变量X的概率无向图解决了MEMM的局部归一化问题。但是,并不是说MEMM的结果就一定崩塌。
MEMM的一个明显的特点是实现简单、速度快,因为它只需要每一步单独执行softmax,所以MEMM是完全可以并行的,速度跟直接逐步Softmax基本一样。
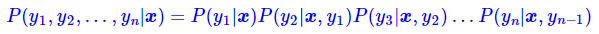
它的每一步计算,不需要整个序列的信息计算分母,而是依赖于上一步的状态。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!